Ethical AI Explained: Why Fairness and Bias Matter
A beginner-friendly guide to ethical AI: understand fairness, bias, real-world risks, and practical steps you can take to build and evaluate responsible AI systems.


Ethical AI Explained: Why Fairness and Bias Matter
Introduction
Artificial intelligence is increasingly part of everyday systems: hiring screens, loan approvals, search results, and recommendation engines. With that influence comes responsibility. Ethical AI is the practice of designing, deploying, and monitoring AI systems so they are fair, safe, and respectful of people. This article explains fairness and bias in plain language, describes common sources of harm, and gives practical steps non-technical readers can use to spot problems and push for better systems.
Why ethics in AI matters
AI systems are not neutral. They can replicate or amplify existing social inequalities when built on biased data or without suitable safeguards. Harm can take many forms:
- Individual harm: Incorrect decisions that affect an individual (denied credit, wrongful flagging).
- Group harm: Systematic poor outcomes for a demographic group (gender, race, age).
- Societal harm: Loss of trust, reduced access to services, and widening inequality.
Knowing these risks helps teams design systems that minimise harm and deliver real value.
Key concepts: fairness, bias, and harm
It helps to define three core terms clearly:
- Bias: Any systematic error in an output that disadvantages certain groups. Bias can come from data, labels, or model choices.
- Fairness: A social judgment about whether outcomes are acceptable across individuals or groups. There are multiple fairness definitions and no one-size-fits-all solution.
- Harm: The real-world negative impact from a system—financial loss, reputational damage, missed opportunities, or mental health effects.
Where bias comes from (simple examples)
Bias can enter an AI system at many stages. Here are common sources with plain examples:
- Data collection bias: If your training data is mainly from one region, the model may perform poorly elsewhere. Example: a face recognition dataset with primarily one skin tone.
- Label bias: If labels reflect a human annotator's stereotype, the model will learn it. Example: tagging job descriptions with gendered roles.
- Sampling bias: Underrepresentation of certain groups leads to poor performance for them. Example: medical data collected largely from one age group.
- Measurement bias: Poor or noisy sensors skew results. Example: cheaper microphones that perform worse for certain voices.
- Proxy variables: When a seemingly neutral input correlates with a protected attribute (e.g., zip code as a proxy for socioeconomic status).
Fairness definitions — what do they mean, simply?
There are many formal fairness definitions in research. For non-technical decision-makers, thinking about these three practical views is useful:
- Equal outcomes: Similar success rates across groups (e.g., approval rates should be comparable). This can be appropriate when outcomes are the primary concern.
- Equal treatment: The system should not use protected attributes (like race) directly. Note: omitting sensitive attributes does not guarantee fairness because proxies may persist.
- Contextual fairness: Adjusting for relevant differences—sometimes different groups legitimately require different handling due to differing base rates. This is a nuanced, case-by-case judgment.
How bias shows up in metrics
Even without advanced math, you can check simple metrics to spot disparities:
- Compare accuracy or error rates across groups (male vs female, region A vs region B).
- Check false positives and false negatives separately. A model can have equal overall accuracy but very different false negative rates for different groups.
- Measure coverage—how many people from each group are included in predictions or outcomes.
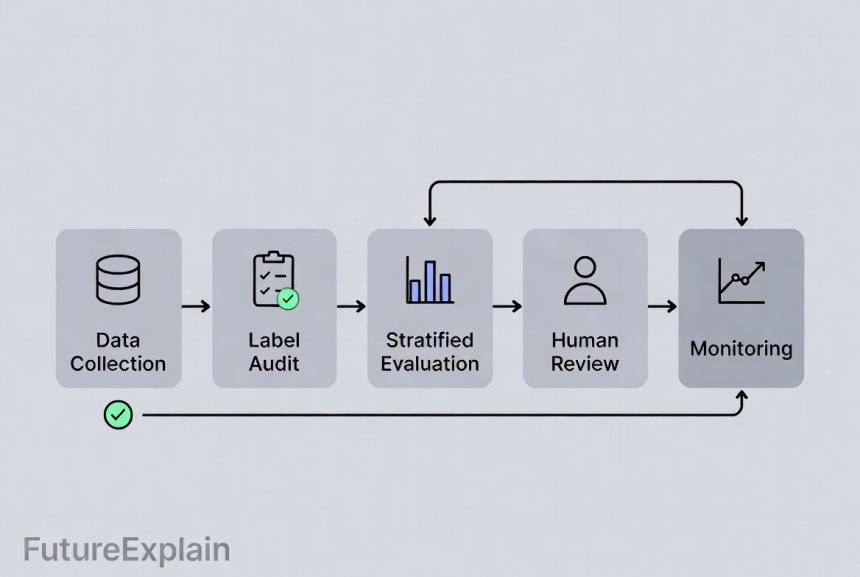
Practical checklist to detect bias (for non-technical reviewers)
Use this checklist when reviewing an AI project or vendor:
- Ask about the training data: Where did it come from? Is it representative of the population you serve?
- Request performance by group: Ask for accuracy and error rates broken down by relevant demographics.
- Find out labels and processes: How were labels created? Were annotators diverse and trained?
- Check post-deployment monitoring: Is the model tracked for performance drift and disparities over time?
- Human-in-the-loop: For high-risk decisions, confirm that humans review or override automated outputs.
Simple mitigation strategies you can ask for
Not every team needs a data scientist to reduce bias. Here are approachable steps:
- Representative sampling: Improve the dataset where possible by collecting more data from underrepresented groups.
- Stratified evaluation: Test model performance across slices (by region, gender, age).
- Label auditing: Randomly review labeled examples to find noisy or biased labels.
- Reject option: For uncertain cases, route to human review rather than automatic decisions.
- Transparency & documentation: Keep a simple datasheet describing dataset sources, known limitations, and intended use.
Case studies — short, real-world style
Here are two concise hypothetical examples that show causes and remediation:
- Hiring tool: A resume screening model favours candidates who used certain universities. Root cause: training data from past hires that reflected biased past hiring. Fix: remove school as a feature, add diverse training examples, and introduce human review for shortlisted candidates.
- Support ticket triage: An LLM-based summariser underperforms for non-native English submissions. Root cause: training on fluent English examples. Fix: add examples of varied language, include multilingual support, and set a confidence threshold to escalate ambiguous cases.
Governance: roles and responsibilities
Ethical AI is organisational, not just technical. Practical governance steps:
- Ownership: Assign a responsible owner for model outcomes (product manager or ethics lead).
- Policy: Create a lightweight policy describing acceptable uses, sensitive contexts, and escalation paths.
- Review board: Use a cross-functional review (legal, domain expert, data lead) for higher-risk projects.
- Stakeholder input: Include end-user feedback, especially from affected groups.
Communication: explaining trade-offs simply
When discussing fairness, translate trade-offs into clear language:
- Accuracy vs fairness: Improving fairness for one group can change overall accuracy—be explicit about what changes and why.
- Transparency vs proprietary models: If a vendor won''t share model details, ask for independent audits or detailed performance slices.
- Automation vs human oversight: Explain which decisions must keep a human in the loop and why.
Practical templates you can ask vendors or teams to provide
Request these simple artefacts to evaluate an AI system:
- Datasheet: Short document with data sources, collection dates, known limitations, and sample sizes per group.
- Evaluation report: Performance numbers for key metrics broken down by relevant groups.
- Mitigation log: List of steps taken to reduce bias with evidence or tests.
Tools and resources for non-technical reviewers
If you want to dig deeper or ask for more rigorous checks, these accessible tools are useful:
- Simple spreadsheets that compare error rates across demographic columns.
- No-code fairness tooling or vendor reports that show group metrics.
- Short checklists from trusted organisations and open-source datasheets templates.
For broader context on building responsible systems, read how-to-use-ai-responsibly-beginner-safety-guide.
When fairness conflicts with other goals
Sometimes fairness requires trade-offs. Common scenarios:
- Business constraints: A product needs to scale quickly; more testing may slow release. Best practice: pilot in a limited audience and monitor.
- Legal and regulatory differences: Rules vary by country; align model behaviour with local laws.
- Metric ambiguity: Different fairness metrics can’t be satisfied simultaneously. Choose metrics aligned to your users and explain the decision.
How to structure simple ethical reviews (a one-page template)
Use this short template for any AI feature:
- What: Briefly describe the feature and its intended user value.
- Who: Who is affected? Which groups might be disadvantaged?
- Data: Where did the data come from? Any known gaps?
- Metrics: What performance and fairness metrics will you track?
- Mitigation: Planned steps (human review, extra data, thresholds).
- Monitoring: How often will you re-evaluate?
Education and career links
Understanding ethical AI is valuable for many careers. If you are exploring career paths, see ai-careers-explained-beginner-friendly-career-paths and broaden your skills with skills-you-should-learn-to-stay-relevant-in-the-ai-era. If you want step-by-step learning without heavy programming, consider how-to-start-learning-ai-without-a-technical-background.
Realistic next steps you can take this week
- Ask for a datasheet or a brief evaluation report for any AI vendor you use.
- Request group-wise performance numbers (errors by region or demographic).
- Run a small audit: sample 50 model decisions and review for problematic patterns.
Conclusion
Ethical AI is a practical discipline. Fairness and bias matter because they change people''s lives. Non-technical readers can meaningfully contribute by asking the right questions, requesting simple tests and documentation, and ensuring human oversight for high-risk decisions. While technical teams and researchers will develop the models, product managers, legal teams, domain experts, and everyday users all have a role to play in building responsible AI systems. For further reading on technical foundations and tools, see how-does-machine-learning-work-explained-simply, and explore practical tool recommendations in top-ai-tools-for-beginners-to-boost-productivity.
Share
What's Your Reaction?
 Like
1500
Like
1500
 Dislike
12
Dislike
12
 Love
240
Love
240
 Funny
35
Funny
35
 Angry
3
Angry
3
 Sad
1
Sad
1
 Wow
95
Wow
95

















Praise: This article is a great primer for teams who want ethical guidance without jargon.
Experience: Starting small with a pilot helped us balance speed and fairness.
Short opinion: Useful and accessible for managers and practitioners alike.
Question: Are there simple visualisations that reveal bias clearly?
Hi carterbell — use grouped bar charts of error rates and cumulative distribution plots for scores by group to reveal differences.
Praise: Concise and practical for real teams.
Experience: A documented mitigation log helped secure budget for better data.