Multimodal AI: Combining Text, Image, Audio, and Video
Multimodal AI represents a major advancement in artificial intelligence by enabling systems to process and understand multiple types of data simultaneously - text, images, audio, and video. This comprehensive guide explains how multimodal AI works in simple terms, covering the technology behind it, real-world applications from healthcare to education, and practical tools beginners can try. You'll learn about different multimodal approaches, current limitations, and how this technology is transforming how computers understand our complex world. Whether you're a student, professional, or simply curious about AI, this guide provides clear explanations without technical jargon.

What Is Multimodal AI and Why It Matters
Imagine asking an AI assistant, "What bird is in this photo?" and showing it a picture. A traditional AI might analyze just the image or just your text question. But a multimodal AI can do something remarkable: it can simultaneously process your question (text), analyze the photo (image), compare it to its knowledge of bird species, and even play the bird's call (audio) while showing you a video of its behavior. This is multimodal AI - artificial intelligence systems that can understand, process, and generate multiple types of data or "modalities" at once.
For decades, most AI systems were unimodal - they specialized in just one type of data. Text-based AI like ChatGPT processes language. Computer vision systems like those in self-driving cars analyze images. Speech recognition software handles audio. But our human experience is naturally multimodal. We see, hear, speak, and read simultaneously, integrating all these inputs to understand our world. Multimodal AI aims to give computers this same integrated understanding.
The importance of multimodal AI becomes clear when you consider real-world applications. Medical diagnosis benefits from analyzing medical images alongside patient history (text) and doctor's notes (audio). Autonomous vehicles need to combine camera feeds (video), LIDAR data (3D points), GPS coordinates, and traffic sign recognition. Even everyday tasks like searching the internet are becoming multimodal - you can now search with an image and get text results, or describe what you're looking for and get image matches.
How Multimodal AI Works: The Technical Side Made Simple
At its core, multimodal AI works by creating a shared understanding space where different types of data can be compared and related. Think of it like learning a new language. When you learn French, you start connecting French words to their English equivalents and to the concepts they represent. Multimodal AI does something similar but with different data types instead of languages.
The Three Main Approaches to Multimodal AI
There are three primary ways researchers build multimodal systems, each with different strengths:
- Early Fusion: Combine all data types right at the beginning, before processing. Like mixing ingredients before baking - everything gets processed together. This approach works well when modalities are tightly connected (like lip movements and speech).
- Late Fusion: Process each modality separately, then combine the results at the end. Like having specialists examine different evidence separately, then comparing notes. This is more flexible but can miss connections between modalities.
- Intermediate/Hybrid Fusion: A balanced approach where modalities interact during processing but maintain some separation. Most modern systems use variations of this approach.
Tokenization: The Secret to Making Different Data Types Comparable
The key technical challenge in multimodal AI is making apples-to-apples comparisons between completely different data types. How do you compare a sentence to an image, or a sound to a video clip? The answer lies in a process called tokenization and embedding.
Text gets broken into words or subwords (tokens). Images get divided into patches (like a grid of smaller images). Audio gets converted into spectrograms (visual representations of sound frequencies). Video gets broken into frames and sometimes motion vectors. Each of these gets converted into numerical vectors - long lists of numbers that capture their essential features. Once everything is in this numerical vector form, the AI can find relationships between them.
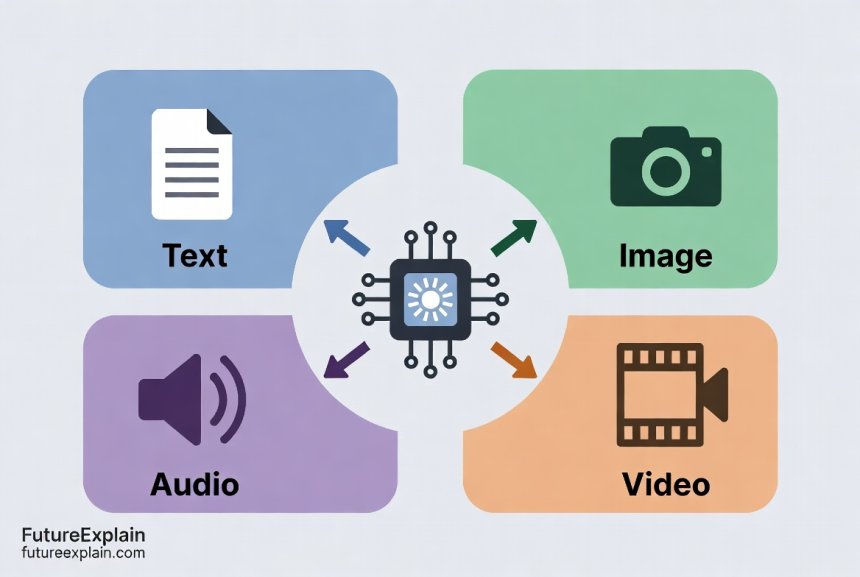
This process creates what researchers call a "joint embedding space" - a kind of universal coordinate system where "cat" as a word, a picture of a cat, and the sound "meow" all get mapped to similar locations. When you show the system a picture of a cat and ask "What animal is this?", it converts the image to its vector location, finds that this location is close to the word vector for "cat," and returns the correct answer.
Real-World Applications Transforming Industries
Healthcare: More Accurate Diagnoses
In healthcare, multimodal AI is revolutionizing diagnostics. Consider a patient with potential skin cancer. A dermatologist might examine the skin lesion (image), review the patient's medical history (text), listen to the patient's description of symptoms (audio converted to text), and consider lab results (more text and numerical data). A multimodal AI system can integrate all these sources simultaneously.
Researchers at Stanford developed a system that combines skin lesion images with patient metadata (age, gender, lesion location, patient history) to achieve diagnostic accuracy surpassing individual dermatologists. The system doesn't just look at the image - it understands that certain types of lesions are more concerning in older patients or in specific body locations.
Education: Personalized Learning Experiences
Educational technology powered by multimodal AI can observe how students learn through multiple channels. It can analyze what content a student reads (text), how they interact with educational videos (video + audio), their performance on interactive exercises, and even their facial expressions during difficult concepts (via webcam, with appropriate privacy safeguards).
This allows for truly personalized learning paths. If a student struggles with written explanations of mathematical concepts but responds well to visual demonstrations, the system can automatically provide more diagram-based explanations. If another student learns better through audio explanations while looking at problems, the system can adapt accordingly.
Content Creation and Media
The creative industries are being transformed by multimodal AI tools. Imagine being able to:
- Upload a rough sketch and describe what you want, generating a complete illustrated scene
- Hum a melody and get a fully orchestrated composition with sheet music
- Describe a video scene in text and have it generated with matching audio
- Take a product photo and automatically generate marketing copy, social media posts, and video ads
Tools like DALL-E 3, Midjourney, and Runway ML are already moving in this direction, allowing text-to-image generation. The next generation will seamlessly integrate audio, animation, and interactive elements based on multimodal inputs.
Accessibility Technology
Some of the most impactful applications are in accessibility technology. Microsoft's Seeing AI app uses multimodal approaches to help visually impaired users understand their environment. It can:
- Read text aloud from documents (text to audio)
- Describe scenes and people (image to text to audio)
- Recognize currency (image to text to audio)
- Identify products via barcodes (image to text to audio)
Similarly, tools are emerging that can generate captions for videos (audio/video to text), describe images for social media (addressing the "alt text" problem), and even convert sign language to speech via camera analysis.
Current Tools and Platforms You Can Try Today
For Beginners: No-Code Options
You don't need to be a programmer to experiment with multimodal AI. Several platforms offer user-friendly interfaces:
- ChatGPT with Vision: OpenAI's ChatGPT can now accept image inputs alongside text. You can upload a photo and ask questions about it, or provide images as context for your conversations.
- Google Lens: While not typically called "AI," this smartphone tool is a practical example of multimodal AI - it analyzes images from your camera and provides relevant text information, translate text in images, identify objects, and more.
- Descript: This audio/video editing tool uses AI to transcribe speech to text, allows editing video by editing text, and can even generate synthetic voice for corrections.
- Runway ML: Offers various multimodal tools including text-to-image, image-to-image, and text-to-video generation through a relatively accessible interface.
For More Technical Users
If you have some technical background, these platforms offer more control:
- Hugging Face Transformers: The transformers library includes multimodal models like CLIP (connects images and text) and Whisper (speech recognition). You can use these with Python and relatively simple code.
- Google's MediaPipe: A framework for building multimodal applied ML pipelines. It includes pre-built solutions for face detection, hand tracking, object detection, and more that can work together.
- OpenAI's CLIP: While primarily a research model, CLIP demonstrates the power of connecting visual concepts with language. You can experiment with it through various implementations and demos online.
The Technology Behind the Scenes: Key Architectures
Transformer Architecture: The Common Foundation
Most modern multimodal AI systems are built on transformer architecture - the same technology that powers ChatGPT and similar language models. Transformers are particularly good at finding relationships between different elements, whether those elements are words in a sentence, patches in an image, or frames in a video.
The key innovation that makes transformers work for multimodal tasks is the attention mechanism. This allows the model to focus on the most relevant parts of each modality when making decisions. For example, when answering a question about an image, the attention mechanism helps the model focus on the specific region of the image that's most relevant to the question.
Contrastive Learning: Teaching AI to Make Connections
How do you teach an AI that the word "dog" is related to pictures of dogs and barking sounds? One powerful technique is contrastive learning. During training, the model is shown matching pairs (an image of a dog with the text "dog") and non-matching pairs (an image of a dog with the text "cat").
The model learns to pull matching pairs closer together in the embedding space and push non-matching pairs apart. Through millions of such examples, it builds a sophisticated understanding of how different modalities relate to each other. This is similar to how we might learn a new language by seeing pictures labeled with words in that language.
Cross-Attention: The Bridge Between Modalities
Cross-attention mechanisms are what allow information to flow between modalities. When processing a video with audio, cross-attention lets the visual features inform how the audio is interpreted (and vice versa). This is crucial for tasks like lip reading, where the visual mouth movements help disambiguate similar-sounding words.
In technical terms, cross-attention works by allowing the "queries" from one modality to attend to the "keys" and "values" from another modality. This creates a dynamic, context-aware connection between different data streams.
Challenges and Limitations of Current Multimodal AI
Technical Challenges
Despite impressive progress, multimodal AI faces significant technical hurdles:
- Alignment Problem: Different modalities often have different granularities and structures. A single word might correspond to an entire image region, or a brief sound might relate to several seconds of video. Getting these alignments right is challenging.
- Data Imbalance: High-quality labeled multimodal datasets are scarce and expensive to create. There are billions of text documents on the internet, but far fewer videos with accurate captions, timestamped audio descriptions, and aligned text transcripts.
- Computational Cost: Processing multiple high-dimensional data streams requires significant computational resources, making real-time applications challenging and expensive.
- Integration Complexity : Simply having multiple modalities doesn't guarantee better performance. Poorly integrated multimodal systems can actually perform worse than their unimodal counterparts due to conflicting signals or noise amplification.
Ethical and Practical Concerns
Beyond technical issues, multimodal AI raises important ethical questions:
- Privacy Implications: Systems that can process camera feeds, microphone audio, location data, and personal documents simultaneously create significant privacy concerns. What happens when these systems are always listening and watching?
- Bias Amplification: If a system learns biases from text data and image data separately, combining them might amplify rather than reduce these biases. A multimodal hiring tool might discriminate based on both resume wording (text) and appearance (images from video interviews).
- Interpretability Challenges: Understanding why a multimodal system made a particular decision is even harder than with unimodal systems. When an AI denies a loan application, is it because of something in the application text, something in supporting documents, or some combination?
- Access and Equity: The computational requirements for training and running multimodal AI mean that only well-resourced organizations can develop these systems, potentially concentrating power and limiting diverse perspectives.
Learning Pathways: How to Get Started with Multimodal AI
For Complete Beginners
If you're new to AI altogether, start with understanding the individual components:
- Learn about basic AI concepts
- Explore how machine learning works
- Understand neural networks and deep learning
- Experiment with simple unimodal tools first - try text-based AI like ChatGPT, image generation with DALL-E, or speech-to-text tools
Once comfortable with these, explore tools that combine modalities:
- Try ChatGPT's image upload feature - ask it to describe photos or answer questions about them
- Experiment with Google Lens on your smartphone
- Use Descript for simple audio/video editing with text-based interface
For Those with Technical Background
If you have programming experience (especially Python), you can dive deeper:
- Start with tutorials on open-source language models
- Learn about the transformer architecture through resources like the Hugging Face course
- Experiment with multimodal models on platforms like Hugging Face Spaces
- Try implementing simple multimodal tasks using pre-trained models from repositories
- Consider taking online courses that specifically cover multimodal machine learning
Academic and Research Paths
For those interested in research or advanced development:
- Study the seminal papers on multimodal learning (CLIP, DALL-E, Flamingo, etc.)
- Learn about different fusion techniques and when to apply them
- Explore specialized architectures for specific multimodal tasks
- Consider contributing to open-source multimodal projects
The Future of Multimodal AI: What's Coming Next
Near-Term Developments (1-3 Years)
In the immediate future, we can expect:
- Better Integration in Everyday Apps: More applications will seamlessly combine text, voice, and visual interfaces. Your calendar might suggest rescheduling based on detecting stress in your voice during a call, combined with your schedule conflicts.
- Improved Robotics: Robots will better understand and interact with their environment by combining visual perception, audio cues, and language instructions.
- Enhanced Creative Tools: Content creation tools will allow more natural multimodal inputs - sketch while describing what you want, or edit video by describing changes.
- More Accessible Interfaces: Technology will become more inclusive through better multimodal interfaces that adapt to different abilities and preferences.
Medium-Term Outlook (3-7 Years)
Looking further ahead:
- True Cross-Modal Understanding: Systems will move beyond surface correlations to deeper understanding of how modalities relate conceptually.
- Reduced Computational Requirements: More efficient architectures will make multimodal AI accessible on consumer devices without cloud dependency.
- Standardized Evaluation: Better benchmarks and evaluation methods will emerge for measuring multimodal understanding.
- Regulatory Frameworks: As these systems become more pervasive, regulations will develop around their ethical use, particularly for surveillance applications.
Long-Term Vision (7+ Years)
The ultimate goal is AI systems with human-like multimodal understanding:
- Seamless Human-AI Collaboration: AI assistants that understand context across all communication modes without explicit switching
- Holistic Problem Solving: Systems that can tackle complex real-world problems requiring integration of diverse information types
- New Forms of Creativity: AI-human co-creation across multiple media simultaneously
- Personalized Education and Healthcare: Truly individualized approaches based on comprehensive multimodal assessment
Practical Considerations for Businesses and Organizations
When to Consider Multimodal AI
Multimodal AI isn't always the right solution. Consider it when:
- Your problem inherently involves multiple data types (customer support with chat logs, call recordings, and screenshots)
- Unimodal approaches have hit performance limits
- You need more robust, context-aware systems
- The cost of errors is high enough to justify the added complexity
Implementation Strategy
If you decide to explore multimodal AI:
- Start Small: Begin with a pilot project combining just two modalities
- Leverage Existing Models: Use pre-trained models rather than training from scratch
- Focus on Data Quality: Ensure your multimodal data is well-aligned and representative
- Plan for Integration: Consider how the multimodal system will fit into existing workflows
- Address Ethical Concerns Early: Implement fairness checks and privacy safeguards from the beginning
Cost Considerations
Multimodal AI can be expensive due to:
- Data Collection and Annotation: Creating aligned multimodal datasets is labor-intensive
- Computational Resources: Training and inference require significant processing power
- Expertise : Multimodal AI specialists command premium salaries
- Integration Costs: Connecting multiple systems and data sources adds complexity
However, costs are decreasing as tools become more accessible and cloud services offer multimodal capabilities as APIs.
Getting Hands-On: Simple Multimodal Project Ideas
Beginner Project: Image Captioning with Context
Start with a simple project using existing tools:
- Use Google's Vision API or a similar service to generate captions for images
- Combine this with a language model (like GPT) to answer questions about the images
- Create a simple web interface where users can upload images and ask questions
This gives you experience with combining visual and language processing without needing to train models from scratch.
Intermediate Project: Emotion Recognition from Multiple Cues
A more advanced project could involve:
- Collecting a small dataset of videos showing different emotions
- Using pre-trained models to extract facial expressions (from video), speech tone (from audio), and spoken words (transcribed text)
- Building a simple classifier that combines these three modalities to predict emotion
- Comparing the multimodal approach to using each modality separately
Advanced Project: Educational Content Analysis
For those with more experience:
- Create a system that analyzes educational videos
- Extract and align: spoken content (speech to text), visual content (slides/diagrams), and on-screen text
- Build an interface that allows searching across all these modalities simultaneously
- Add features like automatic summary generation or question generation based on the content
Conclusion: The Multimodal Future Is Here
Multimodal AI represents a significant step toward artificial intelligence that understands our world more like we do - through multiple, integrated senses. While current systems are still primitive compared to human multimodal understanding, they're already transforming industries and creating new possibilities.
The journey from unimodal to multimodal AI mirrors the evolution of human communication - from text-only to multimedia, from single-channel to rich, integrated experiences. As this technology develops, it will enable more natural human-computer interaction, more powerful tools for creativity and problem-solving, and new approaches to challenges from healthcare to education.
Whether you're a developer, business leader, student, or simply someone curious about technology, understanding multimodal AI is becoming increasingly important. The systems that can effectively combine and reason across different types of information will be at the forefront of the next wave of technological innovation.
Remember that with this power comes responsibility. As we develop and deploy multimodal AI systems, we must consider their ethical implications, work to mitigate biases, and ensure they're used to benefit society as a whole. The future of AI isn't just about making systems more powerful - it's about making them more understanding, in every sense of the word.
Further Reading
Share
What's Your Reaction?
 Like
2450
Like
2450
 Dislike
12
Dislike
12
 Love
890
Love
890
 Funny
45
Funny
45
 Angry
8
Angry
8
 Sad
3
Sad
3
 Wow
420
Wow
420
















Excellent overview! I'm sharing this with my team at work. The implementation strategy section provides a practical roadmap we can follow.
The computational cost discussion matches my experience. We had to scale back our multimodal project because inference costs were 10x our text-only system.
The section on bias amplification is crucial. We need more awareness that combining biased data sources can make things worse, not better.
Absolutely right, Miriam. This is why diverse teams and rigorous testing are essential in AI development. We cover bias management in more detail in our article on <a href="/managing-model-bias-techniques-and-checklists">Managing Model Bias</a>.
As someone without a technical background, I appreciate how this article explains complex concepts without overwhelming the reader. More content like this please!
The explanation of contrastive learning was brilliant. I've read technical papers on this but never understood it as clearly as from the language learning analogy.
I tried the beginner project suggestion with Google Vision API and GPT. It worked surprisingly well! Got my 12-year-old interested in AI too.