How to Implement Continuous Learning in Production
This comprehensive guide explains continuous learning for AI systems in production environments. Learn what continuous learning means, why it's essential for maintaining AI system performance, and how to implement it step-by-step. We cover data drift detection strategies, automated retraining pipelines, monitoring best practices, and practical implementation approaches for businesses of all sizes. Whether you're managing recommendation systems, fraud detection models, or customer service chatbots, this guide provides actionable strategies to keep your AI systems learning and improving automatically over time.

How to Implement Continuous Learning in Production
Artificial intelligence systems are not one-time projects—they're living systems that need to evolve and adapt. When you deploy an AI model to production, the world doesn't stand still. Customer behaviors change, market conditions shift, and new patterns emerge. Without continuous learning, your once-accurate AI model can quickly become outdated, making wrong predictions and losing value.
Continuous learning, also called continuous training or online learning, is the practice of automatically updating AI models in production as new data becomes available. Unlike traditional "train once, deploy forever" approaches, continuous learning creates systems that improve themselves over time. In this comprehensive guide, we'll explore what continuous learning means, why it's essential for modern AI systems, and provide practical step-by-step instructions for implementing it in your own production environments.
What Is Continuous Learning in AI Systems?
Continuous learning refers to the ability of an AI system to learn from new data while operating in production. Imagine you've deployed a recommendation system for an e-commerce store. On day one, it makes good suggestions based on historical purchase data. But as customers start buying new products, following trends, or changing preferences, the system needs to learn these new patterns to remain useful.
Traditional machine learning follows a static workflow: collect data → train model → deploy model → use until performance drops → repeat. Continuous learning transforms this into a dynamic loop: collect data → train model → deploy → monitor → collect new data → update model → deploy updated version → monitor → continue. This creates a self-improving system that adapts to changing conditions.
The Three Main Approaches to Continuous Learning
There are several ways to implement continuous learning, each with different trade-offs:
- Periodic Retraining: The most common approach where models are retrained on a fixed schedule (daily, weekly, monthly) using all available data. This is easier to implement but may miss sudden changes.
- Trigger-Based Retraining: Models retrain automatically when specific conditions are met, such as when performance drops below a threshold or when significant data drift is detected.
- Online Learning: The model updates incrementally with each new data point. This is complex but provides immediate adaptation to new patterns.
Most organizations start with periodic retraining and evolve toward trigger-based approaches as they gain experience. Online learning is typically reserved for specialized applications where immediate adaptation is critical, such as high-frequency trading systems or real-time fraud detection.
Why Continuous Learning Is Essential for Production AI
AI models degrade over time—a phenomenon known as "model decay" or "concept drift." This happens because the world changes while your model stays the same. Consider these real-world examples:
- A credit scoring model trained before an economic downturn may not recognize new patterns of financial stress
- A product recommendation system can't suggest trending items it hasn't seen before
- A fraud detection system becomes vulnerable to new attack patterns
- A customer sentiment analyzer misses emerging slang or cultural references
Research shows that AI models can lose significant accuracy within months if not updated. One study by MIT researchers found that COVID-19 pandemic fundamentally changed consumer behavior patterns, rendering many pre-pandemic models ineffective unless retrained with new data. This highlights why continuous learning isn't just nice to have—it's essential for maintaining business value from AI investments.
The Business Case for Continuous Learning
Implementing continuous learning delivers several concrete business benefits:
- Maintained Accuracy: Models stay relevant as conditions change, preserving prediction quality
- Reduced Manual Effort: Automated retraining eliminates the need for data science teams to manually update models
- Faster Adaptation: Systems can respond to market changes, new products, or emerging trends quickly
- Cost Efficiency: Prevents expensive model failures and bad business decisions from outdated predictions
- Competitive Advantage: Systems that learn continuously outperform static competitors
As Andrew Ng, a leading AI researcher, emphasizes: "The biggest challenge in AI isn't building models—it's keeping them working in production." Continuous learning addresses this fundamental challenge head-on.
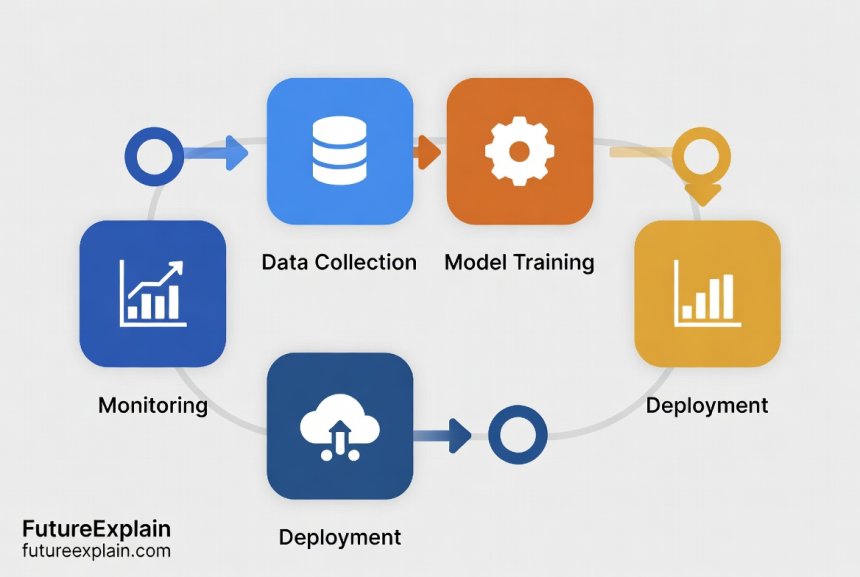
The Continuous Learning Pipeline: Core Components
A complete continuous learning system consists of several interconnected components working together. Let's explore each part of the pipeline:
1. Data Collection and Management
Continuous learning starts with data. You need systems to collect new data from production, store it properly, and prepare it for training. Key considerations include:
- Data Versioning: Track which data was used to train which model version
- Data Quality Checks: Automatically validate incoming data for completeness and correctness
- Feature Storage: Maintain consistent feature definitions across training and inference
- Label Acquisition: Systems to obtain ground truth labels for supervised learning
Many organizations use feature stores—centralized repositories for managing machine learning features—to ensure consistency between training and serving. Tools like Feast, Tecton, or Hopsworks help manage this complexity.
2. Model Training Infrastructure
Automated model training requires infrastructure that can:
- Trigger training jobs based on schedules or events
- Manage computational resources efficiently
- Track experiment parameters and results
- Handle failures and retries gracefully
Cloud platforms like AWS SageMaker, Google Vertex AI, and Azure Machine Learning provide built-in capabilities for automated retraining. Open-source tools like MLflow, Kubeflow, and Apache Airflow can also orchestrate these workflows.
3. Model Evaluation and Validation
Before deploying a newly trained model, you need to validate that it actually performs better than the current version. This involves:
- A/B Testing: Compare new model against current model on a subset of traffic
- Performance Metrics: Calculate accuracy, precision, recall, and business-specific metrics
- Fairness Checks: Ensure the model doesn't introduce or amplify biases
- Explanability Analysis: Verify that the model's decisions make sense
Automated evaluation gates should prevent poorly performing models from reaching production. These checks become particularly important with continuous learning, as models can sometimes learn the wrong patterns from noisy data.
4. Model Deployment and Serving
Once a model passes validation, it needs to be deployed to production with minimal disruption. Modern deployment strategies include:
- Canary Deployments: Roll out to a small percentage of traffic first
- Blue-Green Deployments: Maintain two identical environments and switch between them
- Shadow Deployments: Run new model alongside old model without affecting predictions
Model serving infrastructure must support versioning, traffic splitting, and rollback capabilities. Tools like Seldon Core, KServe, or cloud-native solutions handle these requirements.
5. Monitoring and Alerting
Continuous learning requires continuous monitoring. You need to track:
- Model Performance: Accuracy, latency, throughput
- Data Drift: Changes in input data distribution
- Concept Drift: Changes in relationship between inputs and outputs
- Business Metrics: How model predictions affect business outcomes
Monitoring should trigger alerts when metrics exceed thresholds, potentially initiating automated retraining or alerting human operators. Open-source tools like Evidently AI, WhyLabs, and Amazon SageMaker Model Monitor provide specialized drift detection capabilities.
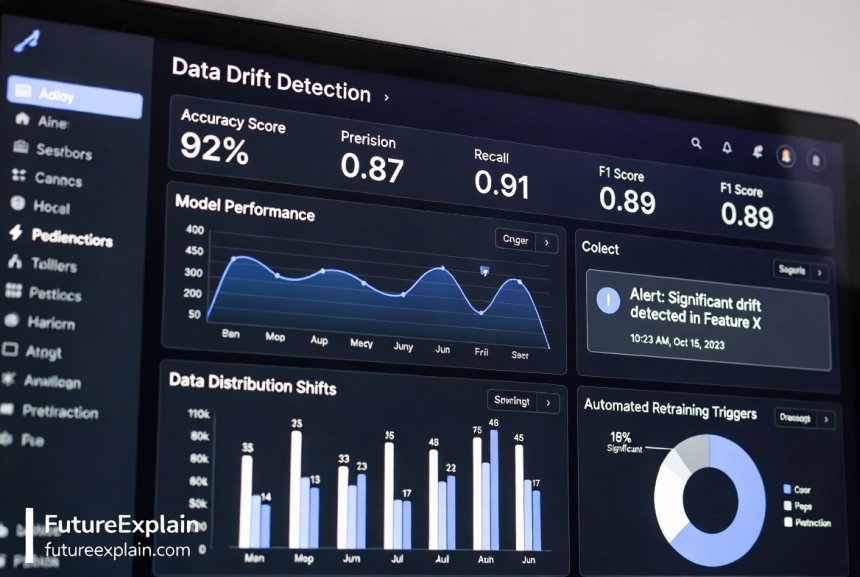
Detecting When Models Need Retraining
The heart of continuous learning is knowing when to retrain. Here are the main signals that indicate a model needs updating:
Data Drift Detection
Data drift occurs when the statistical properties of input data change over time. For example, if your customer demographic shifts or product prices change significantly, your model may need retraining. Common drift detection methods include:
- Statistical Tests: Kolmogorov-Smirnov test, Chi-square test, or Wasserstein distance
- Distribution Comparison: Comparing current data distributions to training data distributions
- Feature Monitoring: Tracking individual feature statistics over time
Data drift doesn't always require retraining—sometimes data preprocessing or feature engineering needs adjustment instead. But it's a strong signal that something has changed.
Concept Drift Detection
Concept drift happens when the relationship between inputs and outputs changes. For instance, during a holiday season, customer purchase patterns change—what predicts purchases in October differs from predictions in July. Detection methods include:
- Performance Monitoring: Tracking accuracy or error metrics over time
- Window-Based Methods: Comparing model performance in recent time windows
- Error Distribution Analysis: Monitoring patterns in prediction errors
Concept drift is more serious than data drift and almost always requires model retraining or architectural changes.
Business Metric Monitoring
Sometimes models maintain statistical accuracy but lose business value. A recommendation system might still accurately predict what users will click, but if those clicks don't lead to purchases, the business value has dropped. Monitor:
- Conversion rates associated with model predictions
- Revenue impact of automated decisions
- Customer satisfaction scores related to AI interactions
- Operational efficiency metrics
These business-focused signals provide the ultimate test of whether your AI system continues to deliver value.
Step-by-Step Implementation Guide
Now let's walk through implementing continuous learning in your production environment. We'll start with simpler approaches and progress to more sophisticated systems.
Step 1: Establish Baselines and Monitoring
Before implementing continuous learning, you need to understand your current system:
- Document your current model's performance metrics
- Establish data quality baselines for your input features
- Set up basic monitoring for model performance and data statistics
- Create alerting for critical failures or significant performance drops
This baseline gives you something to compare against as you implement continuous improvements. Without knowing where you started, you can't measure progress.
Step 2: Implement Automated Data Pipelines
Continuous learning requires reliable data flow:
- Set up automated collection of new data from production systems
- Implement data validation checks to catch quality issues early
- Create feature transformation pipelines that can process new data consistently
- Establish data versioning practices to track what data trained which models
Tools like Apache Airflow, Prefect, or Dagster can orchestrate these data pipelines. Cloud data warehouses like Snowflake, BigQuery, or Redshift often include built-in data pipeline capabilities.
Step 3: Create Automated Training Workflows
Start with scheduled retraining before moving to trigger-based approaches:
- Containerize your training code for reproducibility
- Set up scheduled jobs (weekly or monthly initially)
- Implement experiment tracking to compare different training runs
- Add automated model evaluation against validation datasets
Many organizations use their existing CI/CD (Continuous Integration/Continuous Deployment) systems to orchestrate model training. GitLab CI, GitHub Actions, or Jenkins can trigger training jobs when new data arrives or on a schedule.
Step 4: Implement Gradual Deployment Strategies
Deploying updated models safely is crucial:
- Start with canary deployments to limited user segments
- Implement A/B testing frameworks to compare model versions
- Create rollback plans for when new models underperform
- Monitor business metrics during deployments
Feature flagging systems like LaunchDarkly or Split.io can help control which users see which model versions. This allows for safer experimentation and gradual rollouts.
Step 5: Add Sophisticated Drift Detection
Once basic continuous learning is working, enhance it with smart triggers:
- Implement statistical drift detection for key features
- Set up performance degradation alerts
- Create automated retraining triggers based on drift thresholds
- Add human-in-the-loop approvals for major retraining decisions
Open-source libraries like Alibi Detect, River, or scikit-multiflow provide pre-built drift detection algorithms. For teams with limited ML expertise, managed services like Amazon SageMaker Model Monitor or Google Vertex AI Model Monitoring offer easier starting points.
Common Challenges and Solutions
Implementing continuous learning comes with several challenges. Here's how to address the most common ones:
Challenge 1: Label Acquisition for Supervised Learning
Many continuous learning scenarios require labeled data, but labels often arrive with delay or require human annotation. Solutions include:
- Active Learning: Systems that identify which data points would most benefit from human labeling
- Semi-Supervised Learning: Techniques that learn from both labeled and unlabeled data
- Weak Supervision: Using noisy or approximate labels from existing systems
- Label Prediction: Models that predict labels for new data based on patterns
For example, credit card fraud labels often arrive weeks after transactions when customers dispute charges. Systems must handle this label latency through techniques like delayed feedback modeling.
Challenge 2: Catastrophic Forgetting
When models learn new patterns, they sometimes "forget" previously learned patterns—a phenomenon called catastrophic forgetting. Mitigation strategies include:
- Elastic Weight Consolidation: Techniques that constrain how much important weights can change
- Experience Replay: Periodically retraining on old data along with new data
- Multi-Task Architectures: Designing models that maintain separate representations for different patterns
- Ensemble Methods: Combining old and new models rather than replacing entirely
Catastrophic forgetting is particularly problematic for online learning systems and requires careful architectural consideration.
Challenge 3: Computational Costs
Frequent retraining can become expensive. Optimization approaches include:
- Incremental Learning: Updating models with new data rather than retraining from scratch
- Transfer Learning: Starting from pre-trained models and fine-tuning for new data
- Efficient Architectures: Using model compression or distillation techniques
- Cost-Aware Scheduling: Scheduling retraining during off-peak hours or using spot instances
Cloud cost management tools can help track and optimize ML training expenses. Setting up budgets and alerts prevents unexpected bills.
Challenge 4: Regulatory Compliance
In regulated industries (finance, healthcare, etc.), model changes may require documentation and approval. Compliance strategies include:
- Comprehensive Logging: Documenting all model changes, data used, and performance results
- Audit Trails: Maintaining complete history of model versions and decisions
- Explainability Tools: Generating explanations for model predictions that regulators can understand
- Change Management Processes: Integrating model updates into existing compliance workflows
Tools like IBM Watson OpenScale, Fiddler AI, or Arthur AI provide specialized capabilities for regulated AI environments.
Real-World Implementation Examples
Let's examine how different organizations implement continuous learning:
E-commerce Recommendation Systems
A major online retailer implements continuous learning for their recommendation engine:
- Data Collection: Real-time tracking of user clicks, purchases, and browsing behavior
- Retraining Trigger: Weekly scheduled retraining plus triggers when new products launch
- Deployment Strategy: Canary deployment to 5% of users, then gradual rollout
- Monitoring: Track click-through rates, conversion rates, and revenue per recommendation
- Special Considerations: Handle seasonal patterns (holidays, back-to-school) and flash trends (viral products)
This system adapts to changing consumer preferences and maintains relevance despite constantly changing inventory.
Financial Fraud Detection
A bank implements continuous learning for credit card fraud detection:
- Data Collection: Transaction data with delayed fraud labels (when customers report fraud)
- Retraining Trigger: Daily retraining with a 30-day data window to capture recent patterns
- Deployment Strategy: Shadow deployment alongside existing rules-based system
- Monitoring: False positive rates, fraud detection rates, and customer complaint volumes
- Special Considerations: Adversarial patterns—fraudsters actively try to evade detection
The continuous learning system adapts to new fraud techniques while maintaining low false positive rates to avoid customer frustration.
Customer Service Chatbots
A software company implements continuous learning for their support chatbot:
- Data Collection: Chat transcripts with human agent resolutions as labels
- Retraining Trigger: Monthly retraining plus triggers when new product features launch
- Deployment Strategy: A/B testing with human evaluation of chatbot responses
- Monitoring: Customer satisfaction scores, resolution rates, and escalation to human agents
- Special Considerations: Handling new terminology, emerging issues, and changing user expectations
The chatbot improves its understanding of customer issues and resolution accuracy over time, reducing support costs while improving customer experience.
Tools and Platforms for Continuous Learning
Several tools can accelerate your continuous learning implementation:
Cloud Platform Solutions
- AWS SageMaker: Pipelines for automated retraining, model monitoring, and drift detection
- Google Vertex AI: Managed pipelines with integrated monitoring and continuous training
- Azure Machine Learning: MLOps capabilities including pipelines, monitoring, and trigger-based retraining
Open-Source Frameworks
- MLflow: Experiment tracking, model registry, and deployment management
- Kubeflow: End-to-end ML workflows on Kubernetes with pipeline orchestration
- Apache Airflow: Workflow orchestration for scheduling and triggering training jobs
- Evidently AI: Monitoring and drift detection with interactive dashboards
Specialized Monitoring Tools
- WhyLabs: AI observability platform with automated anomaly detection
- Arize AI: Model performance monitoring and troubleshooting
- Fiddler AI: Model monitoring with bias detection and explainability
The right tool choice depends on your team's expertise, existing infrastructure, and specific requirements. Many organizations start with cloud-managed services and gradually introduce open-source tools for greater control.
Best Practices for Successful Implementation
Based on industry experience, here are key practices for successful continuous learning:
- Start Simple: Begin with scheduled retraining before implementing complex triggers
- Monitor Business Outcomes: Track how model changes affect real business metrics, not just accuracy
- Maintain Model Versioning: Keep complete records of all model versions and their performance
- Implement Rollback Capabilities: Always be able to revert to previous model versions quickly
- Include Human Oversight: Even with automation, maintain human review for significant changes
- Document Everything: Create clear documentation of your continuous learning processes
- Test Thoroughly: Implement comprehensive testing for model updates before production
- Plan for Edge Cases: Consider what happens during data outages, label delays, or system failures
Getting Started with Your First Continuous Learning System
If you're new to continuous learning, here's a practical starting plan:
- Week 1-2: Set up basic monitoring for your existing model's performance and input data
- Week 3-4: Implement automated data pipelines to collect and validate new data
- Week 5-6: Create a scheduled retraining job (monthly initially)
- Week 7-8: Implement automated model evaluation against a holdout validation set
- Week 9-10: Add canary deployment for new model versions
- Week 11-12: Implement basic drift detection and alerting
This gradual approach allows you to build confidence and address issues at each stage. Remember that continuous learning is itself a continuous process—you'll improve your implementation over time as you learn what works for your specific use case.
Conclusion: The Future of Production AI
Continuous learning represents the evolution of AI from static artifacts to dynamic, adaptive systems. As AI becomes more integrated into business operations, the ability to learn continuously from new data will differentiate successful implementations from failed experiments.
The journey to continuous learning requires investment in infrastructure, processes, and skills. But the payoff is substantial: AI systems that maintain their value, adapt to changing conditions, and continue delivering business results long after initial deployment. As you implement continuous learning in your organization, focus on starting simple, measuring impact, and iterating based on what you learn.
Remember that continuous learning isn't just about technology—it's about creating feedback loops between your AI systems and the real world they operate in. By closing these loops, you transform AI from a one-time project into a lasting competitive advantage.
Further Reading
To learn more about related topics, check out these guides:
Share
What's Your Reaction?
 Like
842
Like
842
 Dislike
12
Dislike
12
 Love
315
Love
315
 Funny
28
Funny
28
 Angry
5
Angry
5
 Sad
3
Sad
3
 Wow
187
Wow
187

















This article has been bookmarked for our entire data science team. The practical examples and clear explanations make complex MLOps concepts accessible. Looking forward to more content on production AI systems!
How do you handle feature engineering changes with continuous learning? If we discover a better way to engineer features, do we need to retrain all historical data?
We maintain feature transformation pipelines that can reprocess historical data. When we improve feature engineering, we rerun the pipeline on our entire dataset and retrain. It's computationally expensive but necessary for consistency.
The section on business metric monitoring resonates with me. We improved our recommendation system's accuracy but saw decreased sales because it became too conservative. Now we monitor revenue per user alongside accuracy.
I'd love to see a follow-up article on monitoring data pipelines for continuous learning. We've had issues where data quality problems went undetected and corrupted our retraining process.
We're in the insurance industry and regulatory approval for model changes can take months. How do we implement continuous learning when we can't deploy frequently?
This is a common challenge in regulated industries. You can implement continuous learning in stages: 1) Continuous retraining and validation in development environments, 2) Accumulate evidence of improved performance over multiple retraining cycles, 3) Bundle multiple improvements into fewer regulatory submissions. Also, work with regulators early to establish approval processes for automated retraining within certain bounds (like retraining with the same architecture but new data).
The tools comparison is helpful, but I'd add DVC (Data Version Control) to the list. It's been essential for us in tracking data, code, and model versions together in our continuous learning pipeline.