Data Labeling Best Practices for High-Quality Training Data
This guide explains data labeling, the essential process of tagging data to teach AI models. You'll learn why high-quality labels are the foundation of any successful AI project and how poor data leads to biased or broken systems. We cover practical best practices like creating clear guidelines, implementing multi-stage quality checks, and choosing the right tools for your project. The article also addresses common challenges like subjectivity and scale, and provides a beginner-friendly roadmap to start your first labeling project. By the end, you'll understand how to build reliable training data that makes AI systems accurate, fair, and effective.

Data Labeling Best Practices for High-Quality Training Data
If you've ever wondered how artificial intelligence learns to recognize a cat in a photo, understand a spoken command, or recommend a product, the answer starts long before any complex algorithm runs. It starts with data labeling. This fundamental, often unseen process is what makes modern AI possible. Simply put, data labeling is the act of tagging raw data—like images, text, audio clips, or videos—with informative labels that teach an AI model what it's looking at.
Think of it like teaching a young child. You wouldn't just show a child thousands of pictures and expect them to learn what a "dog" is. You point and say, "That's a dog." Data labeling does the exact same thing for AI. By adding these descriptive tags—"dog," "cat," "car," "happy sentiment," "spoken word 'hello'"—we create a structured set of examples that machine learning models learn from. The quality of this teaching material directly determines how smart, accurate, and fair the AI will be.
In this comprehensive guide, we'll walk through the essential best practices for data labeling. Whether you're a small business owner looking to build a custom AI tool, a student starting a project, or a professional exploring this field, you'll learn how to create the high-quality training data that is the bedrock of any successful AI system.
What is Data Labeling and Why Does It Matter?
At its core, data labeling is the process of adding meaningful and informative tags to raw data. These tags identify the properties, classifications, or features of the data that you want a machine learning model to recognize. For a more detailed look at how AI learns from data, check out our guide on how machine learning works.
Here are a few common types of labeling:
- Image Annotation: Drawing bounding boxes around objects, segmenting different parts of an image, or classifying an entire scene.
- Text Classification: Tagging sentences or documents with categories like "spam/not spam," "positive/negative sentiment," or topic labels.
- Audio Transcription: Converting speech to text and labeling speaker identity, emotions, or background noises.
- Video Labeling: Tracking objects across multiple frames or labeling actions and events over time.
The importance of this process cannot be overstated. High-quality labeled data is the single most critical ingredient for building performant AI. A model is only as good as the data it's trained on. If your labels are inaccurate, inconsistent, or biased, your AI will learn the wrong lessons. This leads to systems that make errors, perpetuate stereotypes, and fail in real-world use. Investing time in proper labeling isn't just a technical step; it's an investment in the reliability and ethics of your final AI product.
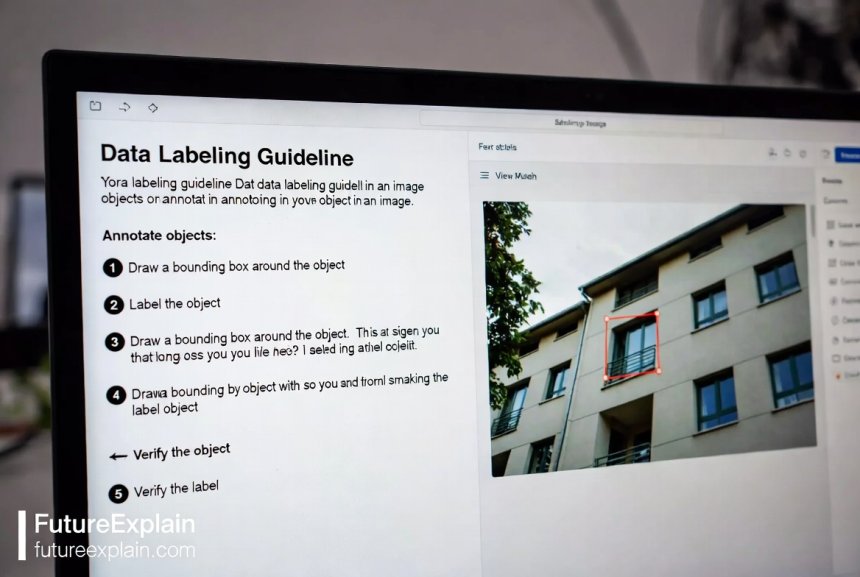
Best Practice 1: Create Crystal-Clear Labeling Guidelines
Before a single piece of data is labeled, you must create a comprehensive instruction document. This is your rulebook, and its clarity dictates the consistency of your entire dataset.
Your guidelines should leave no room for interpretation. Don't just say "label all dogs." Define what constitutes a "dog" in your context: Are cartoon dogs included? What about statues of dogs? What if only the tail is visible? For a deep dive into how AI interprets complex data, you can explore deep learning and neural networks.
Essential elements of great guidelines include:
- Definitions: Precise, unambiguous definitions for every label and class.
- Visual Examples: Show multiple correct examples of each label. Crucially, also show common incorrect examples and explain why they're wrong.
- Edge Case Rules: Explicit instructions for ambiguous situations. What do labelers do if they're unsure?
- Tool Instructions: Step-by-step instructions for using the labeling software or platform.
- Quality Standards: A clear explanation of what "high-quality" means for your project (e.g., pixel-perfect segmentation, specific bounding box tightness).
Treat this as a living document. As your labelers start working, they will encounter scenarios you didn't anticipate. Update the guidelines regularly to address these new edge cases, ensuring everyone is always following the latest rules.
Best Practice 2: Implement a Multi-Stage Quality Assurance (QA) Process
Assuming labelers will be perfect is the fastest way to ruin a dataset. A robust QA process is non-negotiable. This involves multiple checks to catch and correct errors.
A proven structure includes:
- Labeler Self-Check: The initial labeler reviews their own work before submission.
- Peer Review: Another labeler reviews a sample of the work. This catches subjective errors and inconsistencies between people.
- Expert/Adjudicator Review: A senior labeler or project manager reviews disputed labels or a random sample of all data. They have the final say on ambiguous cases.
- Automated Consistency Checks: Use scripts or tool features to find obvious errors, like bounding boxes drawn outside the image boundaries or mismatched label formats.
A common and effective technique is to send a small percentage of data (e.g., 5-10%) to be labeled by multiple people independently. By measuring the "inter-annotator agreement," you get a quantitative score of how consistent your guidelines and labelers are. Low agreement means your guidelines are unclear or the task is too subjective, signaling a need to refine your approach before proceeding at scale.
Best Practice 3: Choose the Right Tool and Team for the Job
The tools and people you use will shape your project's efficiency and outcome.
Selecting Labeling Tools
Options range from fully manual to highly automated:
- DIY & Spreadsheets: For very simple text classification with a tiny dataset, a spreadsheet might suffice.
- Open-Source Tools: Tools like LabelImg, CVAT, or Label Studio offer great functionality for free and are good for technical teams who can host and manage them.
- Commercial Platforms: Cloud platforms like Scale AI, Labelbox, and Supervisely provide managed workforces, advanced QA features, and project management. They are ideal for larger projects or teams without technical infrastructure.
- Model-Assisted Labeling: The most efficient modern approach. You train a preliminary model on your first batch of labels, and then use that model to pre-label new data. Human labelers then just correct the model's suggestions, dramatically speeding up the process. This ties into concepts like continuous learning in production.
Building and Managing Your Labeling Team
Your team could be in-house staff, crowdsourced workers, or specialized contractors. Key considerations:
- Expertise: Labeling medical X-rays requires domain experts, while labeling everyday photos may not.
- Training: Never assume labelers understand the task from guidelines alone. Conduct interactive training sessions and have them label a test batch before starting real work.
- Feedback Loop: Create a direct channel (like a chat group or weekly review) where labelers can ask questions and report problematic data or edge cases.
- Motivation & Fair Pay: High-quality work requires focus. Ensure labelers are fairly compensated and understand the importance of their role in the larger AI project.
Best Practice 4: Iterate and Monitor Continuously
Data labeling is not a "set it and forget it" task. It's an iterative cycle.
- Start Small: Begin with a pilot project. Label a few hundred items using your draft guidelines and initial team.
- Train a Model & Test: Use this small batch to train a simple prototype model. Test it on a held-out validation set. The model's failure modes are your best diagnostic tool—they will clearly show you what your labels are missing or getting wrong. For related techniques on ensuring model quality, see our article on managing model bias.
- Analyze Errors & Refine: Did the model confuse two similar objects? Your labels might not be precise enough. Did it fail on specific backgrounds? You may need more diverse data. Use these insights to refine your labeling guidelines and data collection strategy.
- Scale with Confidence: Only after the pilot phase produces a model that learns correctly should you scale up the labeling effort to the full dataset.
Continuous monitoring is also key. As you scale, periodically re-check label quality. Labeler performance can drift over time, or fatigue can set in. Regular QA sampling keeps the entire process on track.
Common Data Labeling Challenges and How to Overcome Them
Every labeling project faces hurdles. Being prepared makes them manageable.
- Subjectivity: Labels like "beautiful" or "angry tone" are inherently subjective. Solution: Break subjectivity into objective components. For emotion, use a well-defined framework like Ekman's basic emotions. Provide extensive, clear examples and measure inter-annotator agreement closely.
- Scale and Cost: Labeling millions of items is expensive and slow. Solution: Leverage model-assisted labeling and active learning. Active learning algorithms identify which data points would be most informative for the model to have labeled next, so you label smarter, not harder.
- Labeler Bias: Labelers' own unconscious biases can seep into labels. Solution: This is a major focus of AI ethics and safety. Use diverse labeling teams, anonymize data to remove biasing context where possible, and conduct rigorous audits for fairness across different demographic groups represented in your data.
- Data Privacy & Security: Handling sensitive personal data (medical records, faces). Solution: Use secure, compliant platforms. Anonymize or pseudonymize data before labeling. Ensure all labelers have signed confidentiality agreements and are trained on data handling protocols.
Your Practical Roadmap to a First Labeling Project
Ready to start? Follow this beginner-friendly roadmap:
- Define Your Objective: Be crystal clear on what you want your AI model to predict. This defines your labels.
- Source Your Raw Data: Collect or gather the unlabeled data. Ensure it's relevant and representative of the real-world scenarios your AI will face. For ideas on sourcing data, our guide on open data and licenses can help.
- Draft Version 1 of Your Guidelines: Create the rulebook with definitions, examples, and edge cases.
- Choose a Tool & Label a Pilot Batch: Pick a simple, user-friendly tool. Label 200-500 items yourself to understand the task's nuances.
- Refine Guidelines & Train a Small Team: Update your guidelines based on pilot learnings. Train 2-3 labelers and have them label the same small set to check for consistency.
- Establish QA & Launch Phase 1: Set up your peer-review process. Launch the labeling of your first substantial batch (e.g., 5,000 items).
- Validate with a Model: Train a simple model. Analyze its errors and loop back to refine data and guidelines.
- Scale and Monitor: Gradually increase labeling volume while maintaining regular QA checks.
Remember, the goal is not just to label data, but to create a reliable knowledge base from which AI can learn. By following these best practices—clear guidelines, robust QA, the right tools, and an iterative mindset—you build a solid foundation. This foundation is what transforms a promising AI concept into a trustworthy, effective, and fair application that works in the real world.
Further Reading
To continue your learning, explore these related guides on FutureExplain:
- Managing Model Bias: Techniques and Checklists - Learn how to audit and correct bias that can originate from your training data.
- Synthetic Data for Training: When and How to Use It - Discover how artificially generated data can supplement your labeled datasets.
- Open Data & Licenses: Where to Source Training Data - Find legal and free sources of data to kickstart your projects.
Share
What's Your Reaction?
 Like
1240
Like
1240
 Dislike
12
Dislike
12
 Love
310
Love
310
 Funny
45
Funny
45
 Angry
5
Angry
5
 Sad
8
Sad
8
 Wow
180
Wow
180


















Finally, an article that doesn't treat data labeling as an afterthought! The "garbage in, garbage out" principle is so true. This is the foundation.
I appreciate the emphasis on data privacy. It's too easy to just send sensitive data to a third-party platform without thinking. The reminder about anonymization and agreements is crucial.
We're labeling sensor data from IoT devices. The principle of "defining edge cases" applies even to non-visual data. What counts as a "faulty sensor reading" versus "normal noise" needed very clear thresholds.
As a student, the biggest takeaway for me is that data labeling is a serious engineering and management task, not just mechanical work. This really elevates the importance of the role.
The comparison table of different tool types is super useful. It's not just about features, but about what your team can actually manage. We're a two-person startup, so "managed service" is now our top criterion.
Question about the pilot phase: how small is "small"? Are we talking 100 images, 500, 1000?
Good rule of thumb, Ezekiel: Start with the minimum amount that lets you encounter a variety of your expected edge cases. For many image projects, 200-500 is a great pilot batch. For text, maybe 500-1000 documents. The goal isn't to train a good model yet, but to stress-test your guidelines and process.