Differential Privacy Made Simple: Concepts and Use Cases
Differential privacy is a revolutionary approach to data analysis that allows organizations to gain insights from datasets while mathematically guaranteeing individual privacy. This guide explains differential privacy in simple, non-technical language, starting with the core concept of adding carefully calibrated 'noise' to data outputs. We'll explore practical applications from healthcare research to business analytics, breaking down complex ideas like privacy budgets (epsilon), the privacy-utility tradeoff, and implementation strategies. You'll learn how differential privacy differs from traditional anonymization, discover real-world use cases across industries, and get practical guidance on implementing these techniques in your own projects while maintaining GDPR and regulatory compliance.

Introduction: Why Your Data Needs Mathematical Privacy Guarantees
In our data-driven world, organizations constantly face a fundamental dilemma: how to extract valuable insights from sensitive information while protecting individual privacy. Traditional approaches like anonymization, aggregation, and data masking have repeatedly failed, with studies showing that 87% of Americans can be uniquely identified from just three data points: zip code, birth date, and gender. This privacy crisis demands a more robust solution, and that's where differential privacy enters the picture.
Differential privacy represents a paradigm shift in how we think about data protection. Rather than relying on ad-hoc techniques that can be reverse-engineered, it provides mathematical guarantees about privacy loss. Developed by leading computer scientists including Cynthia Dwork, differential privacy has become the gold standard for privacy-preserving data analysis, adopted by technology giants like Apple, Google, and Microsoft, as well as government agencies including the U.S. Census Bureau.
This guide will demystify differential privacy for non-technical readers, business professionals, and developers alike. We'll start with simple analogies, build up to practical implementations, and explore real-world applications that demonstrate why this technology is revolutionizing how organizations handle sensitive data.
What Is Differential Privacy? The Simple Explanation
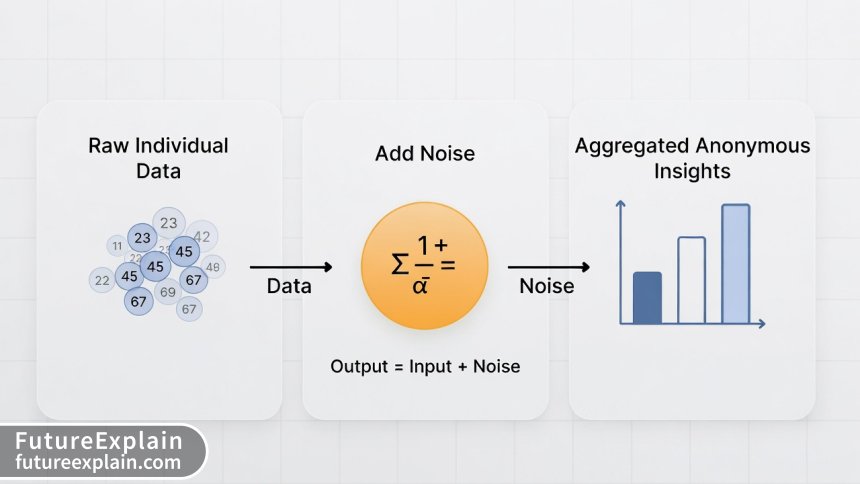
At its core, differential privacy is a mathematical framework for measuring and limiting privacy loss when analyzing datasets. The fundamental idea is surprisingly intuitive: by adding carefully calibrated "noise" or randomness to query results, we can provide useful aggregate insights while making it statistically impossible to determine whether any specific individual's data was included in the analysis.
Imagine you're at a party where people are discussing their salaries. If someone asks for the average salary in the room, you could answer truthfully but add or subtract a small random amount. The result remains useful for understanding salary ranges in your industry, but no one can reverse-engineer to discover your exact salary. This is the essence of differential privacy—protecting individuals while preserving statistical utility.
The Mathematical Foundation: Privacy Budget (ε) and Parameters
Differential privacy operates on two key parameters: ε (epsilon) and δ (delta). Think of ε as your privacy budget—a measure of how much privacy you're willing to "spend" to get useful insights. A smaller ε means stronger privacy guarantees but less accurate results, while a larger ε provides more accuracy at the cost of weaker privacy protection.
The parameter δ represents the probability that the privacy guarantee might fail. In practice, δ is typically set to a very small value (like 10⁻⁵), meaning there's only a 0.001% chance the privacy protection could be compromised. This mathematical rigor is what sets differential privacy apart from earlier approaches—it provides quantifiable, proven privacy guarantees rather than vague promises.
How Differential Privacy Actually Works: The Noise Mechanism
The magic of differential privacy happens through carefully designed noise addition algorithms. The most common approach uses the Laplace or Gaussian distributions to add random noise to query results. The amount of noise added depends on:
- The sensitivity of the query (how much individual data can affect results)
- The chosen privacy parameters (ε and δ)
- The number of queries made against the dataset
Here's a concrete example: Suppose a healthcare researcher wants to know how many patients in a database have a specific condition. With differential privacy, the system might return "152" instead of the exact count of 150. The added noise of 2 protects individual patients while still providing statistically valid insights for research purposes.
Visuals Produced by AI
Differential Privacy vs. Traditional Anonymization: Why Old Methods Fail
Traditional data protection methods rely on techniques like removing names, masking identifiers, or aggregating data. However, research has repeatedly demonstrated their vulnerabilities:
- De-anonymization attacks: Netflix Prize dataset (2007) showed how movie ratings could be matched to public IMDb profiles
- Linkage attacks: Massachusetts hospital data was re-identified by linking to voter registration records
- Differencing attacks: Subtracting aggregate results can reveal individual information
Differential privacy solves these problems through its mathematical foundations. Even if an attacker has access to all but one record in a dataset (the "differential" in differential privacy), they cannot determine with confidence whether that remaining individual's data was included. This provides what's called "plausible deniability" for every person in the dataset.

Visuals Produced by AI
Practical Applications: Where Differential Privacy Makes a Difference
Healthcare and Medical Research
Medical researchers need access to patient data to study disease patterns, treatment effectiveness, and public health trends. Traditional approaches require complex consent processes or limit data sharing. With differential privacy, hospitals can share aggregated insights while guaranteeing patient confidentiality. The COVID-19 pandemic highlighted this need, as researchers needed to analyze infection patterns without compromising individual health data.
For example, researchers at Stanford Medicine used differential privacy to analyze cancer patient outcomes across multiple institutions. They could identify which treatments showed the best results for specific genetic profiles while ensuring no individual patient's data could be identified or leaked between collaborating hospitals.
Business Analytics and Customer Insights
Companies collect vast amounts of customer data to improve products and services. Differential privacy enables businesses to:
- Analyze user behavior patterns without tracking individuals
- Test new features on subsets of users while protecting their privacy
- Share aggregate market insights with partners without revealing proprietary customer data
Apple uses differential privacy in iOS to collect usage statistics for emoji popularity, typing suggestions, and battery usage patterns. This allows them to improve user experience without accessing individual message content or personal information.
Government and Public Policy
The U.S. Census Bureau adopted differential privacy for the 2020 Census after research showed traditional methods could be exploited to identify individuals. By adding controlled noise to demographic data, the Census can publish detailed population statistics while meeting strict legal privacy requirements.
Similarly, transportation departments use differential privacy to analyze traffic patterns from GPS data without tracking individual vehicles, and education departments can assess school performance trends without revealing individual student records.
Implementing Differential Privacy: A Practical Guide
Choosing the Right Privacy Budget (ε)
Selecting appropriate ε values is both an art and a science. Here's a practical framework:
- ε = 0.1 to 1: Strong privacy protection suitable for highly sensitive data (medical records, financial information)
- ε = 1 to 5: Moderate protection for business analytics, user behavior studies
- ε = 5 to 10: Weaker protection for non-sensitive aggregate statistics
Remember: ε is cumulative across queries. If you run 10 queries with ε=0.1 each, your total privacy budget consumption is ε=1. This necessitates careful query planning and budget allocation.
Open-Source Tools and Libraries
Several excellent open-source libraries make differential privacy accessible to developers:
- Google's Differential Privacy Library: Production-ready C++ and Go implementations with Python bindings
- IBM's Diffprivlib: Python library focused on machine learning with differential privacy
- OpenDP (Harvard): Flexible framework for building privacy-preserving applications
- Microsoft's SmartNoise: SDK for differential privacy with SQL and machine learning support
For beginners, I recommend starting with IBM's Diffprivlib due to its Python integration and comprehensive documentation. It allows you to add differential privacy to scikit-learn machine learning pipelines with just a few lines of code.
Implementation Checklist
- Data Sensitivity Assessment: Classify your data by sensitivity level
- Privacy Budget Planning: Determine acceptable ε values for your use case
- Tool Selection: Choose appropriate library based on your tech stack
- Noise Mechanism Testing: Validate that added noise provides utility while protecting privacy
- Iterative Refinement: Start with conservative ε values, adjust based on utility needs
- Documentation: Clearly document privacy parameters and guarantees
- Compliance Verification: Ensure implementation meets regulatory requirements
Common Challenges and Solutions
Balancing Privacy and Utility
The fundamental tradeoff in differential privacy is between privacy protection and data utility. Too much noise renders insights useless; too little compromises privacy. The key is iterative refinement: start with strong privacy guarantees (low ε) and gradually increase until you achieve acceptable accuracy for your use case.
Advanced techniques like privacy amplification (applying differential privacy to random samples rather than full datasets) and composition theorems (mathematically tracking cumulative privacy loss) help optimize this balance.
Handling Complex Queries
Simple counting queries (how many users did X) are straightforward to protect with differential privacy. More complex operations like machine learning model training require specialized algorithms. Fortunately, research has produced differentially private versions of most common algorithms:
- Differentially private gradient descent for neural networks
- Private decision trees and random forests
- Private k-means clustering
- Private logistic regression
These algorithms modify the training process to limit the influence of any individual data point, typically by clipping gradients and adding noise during optimization.
Real-World Case Studies
Case Study 1: Apple's iOS Data Collection
Apple's implementation of differential privacy for iOS analytics demonstrates practical deployment at scale. They collect data on:
- Emoji usage patterns to improve prediction algorithms
- Battery usage statistics to optimize power management
- Typing behavior to enhance autocorrect suggestions
Each data submission includes differentially private noise, and Apple uses a technique called "privacy bands" to group similar users while protecting individuals. This approach allowed Apple to maintain its privacy-first branding while still gathering valuable product improvement data.
Case Study 2: U.S. Census 2020
The Census Bureau's adoption of differential privacy followed years of research showing that traditional anonymization methods were vulnerable. Their implementation faced unique challenges:
- Legal requirement to produce accurate population counts for congressional representation
- Need for detailed demographic data for research and policy planning
- Historical commitment to respondent confidentiality
By carefully tuning privacy parameters and developing new disclosure avoidance techniques, the Census Bureau created what they call "formal privacy" guarantees—mathematically proven protection that withstands modern computational attacks.
Ethical Considerations and Best Practices
Transparency and Accountability
Implementing differential privacy requires more than just technical deployment. Organizations should:
- Clearly communicate privacy guarantees to data subjects
- Document privacy budget usage and remaining allocations
- Establish governance procedures for privacy parameter decisions
- Conduct regular privacy impact assessments
Avoiding Privacy Washing
Just as "greenwashing" exaggerates environmental benefits, "privacy washing" can misuse differential privacy terminology without proper implementation. Best practices include:
- Using established, peer-reviewed algorithms rather than custom implementations
- Publishing privacy parameter choices and justifications
- Undergoing third-party privacy audits for critical applications
- Being honest about limitations (differential privacy doesn't solve all privacy problems)
The Future of Differential Privacy
Emerging Trends and Research Directions
The field of differential privacy continues to evolve rapidly. Key areas of active research include:
- Local differential privacy: Adding noise at the data source (user device) rather than centrally
- Federated learning with differential privacy: Training models across decentralized data with privacy guarantees
- Differential privacy for unstructured data: Extending protection to text, images, and multimedia
- Automated privacy budget management: AI systems that optimize ε allocation across queries
Integration with Other Privacy Technologies
Differential privacy doesn't exist in isolation. It's increasingly combined with:
- Homomorphic encryption: Performing computations on encrypted data
- Secure multi-party computation: Collaborative analysis without sharing raw data
- Zero-knowledge proofs: Verifying insights without revealing underlying data
These combinations create powerful privacy-preserving systems that offer multiple layers of protection.
Getting Started: Your First Differential Privacy Project
Step-by-Step Tutorial
Let's walk through a simple differential privacy implementation using Python and Diffprivlib:
- Install the library:
pip install diffprivlib - Import and configure a differentially private mean calculator:
This simple example protects individual salaries while calculating average income statistics. The epsilon parameter controls privacy strength, and the library automatically handles noise addition and privacy accounting.
Common Pitfalls to Avoid
- Ignoring composition: Each query consumes privacy budget; track cumulative usage
- Overestimating protection: Differential privacy protects against specific attacks but not all privacy risks
- Underestimating noise impact: Test utility with realistic data before deployment
- Neglecting data preprocessing: Outliers and data quality issues affect privacy guarantees
Conclusion: Embracing Mathematical Privacy Guarantees
Differential privacy represents a fundamental advancement in how we balance data utility with individual privacy. By providing mathematical guarantees rather than heuristic protections, it offers a robust foundation for responsible data analysis in an increasingly privacy-conscious world.
As you explore differential privacy for your own projects, remember that it's not a silver bullet but a powerful tool in the privacy engineering toolkit. Start with small experiments, learn from the growing community of practitioners, and contribute to the development of privacy-preserving technologies that benefit everyone.
The transition to differential privacy requires investment in education, tooling, and cultural change within organizations. However, the benefits—maintaining user trust, complying with evolving regulations, and enabling innovative data uses—make this investment essential for any organization working with sensitive data in the 21st century.
Further Reading
- Privacy-Preserving AI: Differential Privacy & Federated Learning - Explore how differential privacy combines with other privacy technologies
- AI Ethics & Safety - Broader context on ethical AI development and deployment
- Responsible Data Collection: Consent and Compliance (Practical) - Learn about data governance frameworks that complement differential privacy
Share
What's Your Reaction?
 Like
1247
Like
1247
 Dislike
18
Dislike
18
 Love
356
Love
356
 Funny
42
Funny
42
 Angry
9
Angry
9
 Sad
5
Sad
5
 Wow
289
Wow
289


















This is the most comprehensive yet accessible guide to differential privacy I've encountered. It balances theory with practice perfectly. The real-world case studies and implementation checklist make it actually useful rather than just theoretical. Will be sharing with my entire data science team.
The section on federated learning with differential privacy is particularly timely. We're seeing increased regulatory pressure in finance to use these techniques. Does anyone have experience with DP in federated learning for cross-border data sharing?
We tried implementing OpenDP but found the documentation lacking for production use. Ended up switching to Google's library. The learning curve was steep but worth it. Wish the article had more troubleshooting tips for common implementation pitfalls.
The article mentions δ is typically set to 10⁻⁵. Why this specific value? Is there a standard or is it arbitrary? What happens if we set δ=0 for perfect privacy?
@Silas - δ=10⁻⁵ is a common heuristic—it means there's a 0.001% chance the privacy guarantee fails, which is considered acceptable risk in many applications. You CAN set δ=0, but then you're in "pure" ε-differential privacy, which is more restrictive and often requires more noise. Most practical implementations use (ε,δ)-differential privacy because it allows better utility for the same privacy guarantee. The exact δ value involves tradeoffs: too high increases failure risk, too low increases noise.
As a business director, I care about ROI. What's the cost implication of implementing differential privacy vs. potential fines from data breaches? Are there studies showing the business case beyond just compliance?
@Raj - Our company did this analysis last year. Implementation cost for a mid-sized dataset was about $50k in developer time/tools. Average GDPR fine for a medium breach is €500k-€1M. Plus there's brand damage. For us, the math was clear—DP is insurance with positive ROI. Also, we've since used our privacy-first stance as a marketing differentiator.
How does differential privacy handle outliers? If we have a dataset where 99% of values are between 1-100, but one value is 1,000,000, won't the noise need to be enormous to protect that outlier? Doesn't this destroy utility for normal cases?
@Alistair That's exactly right—it's called "sensitivity to outliers." The standard solution is clipping: you set a maximum possible value (say 200 in your example) and clip anything above that. Then the sensitivity is bounded by your clip range. The article briefly mentions "clipping gradients" in ML context, but the same principle applies to data values.