Deploying Models to Production: Simple MLOps Guide
This guide demystifies the process of moving an AI model from a prototype to a reliable, real-world application—a practice known as MLOps (Machine Learning Operations). We break down this technical journey into simple, logical steps anyone can understand. You'll learn why a model that works perfectly in a lab can fail in production, and what crucial stages—like rigorous testing, containerization, deployment strategies, and continuous monitoring—prevent that. We explain key concepts such as A/B testing, model drift, and cost management without complex jargon. The article also covers how to set up basic monitoring to catch problems and plan for safe updates, providing a clear roadmap for beginners, business owners, and anyone looking to understand how AI applications are built to last.
You've seen the amazing demos: an AI that writes poems, identifies objects in images, or predicts trends. But how does that experimental code on a researcher's laptop become a feature in your favorite app, reliably serving millions of people? The journey from a working model to a trustworthy production system is where the real challenge—and magic—happens. This process is called MLOps, or Machine Learning Operations.
Think of it like this: building a model is like designing and test-driving a new car prototype. MLOps is everything required to manufacture that car at scale, ensure its safety, distribute it to dealerships, maintain it with regular service, and recall it if a flaw is found. Without this operational backbone, even the smartest AI model is just an interesting experiment.
This guide is for anyone curious about how AI really works in the real world. You don't need to be an engineer. We'll walk through the essential steps, explain why they matter, and give you the foundational knowledge to understand or even plan your own AI deployment.
Why “It Works on My Machine” Isn't Enough
Before we dive into the *how*, let's understand the *why*. A model in a development environment (like a data scientist's laptop) lives in a controlled, simplified world. The data is clean, the questions are predictable, and it's the only thing running. Production—the real world—is messy and demanding.
Here are the main reasons models fail after deployment:
- Data Drift: The real-world data the model receives changes over time. Imagine a model trained to recognize 2023 fashion trends suddenly getting 2025 photos. Its performance will drop because it's seeing new, unfamiliar patterns[citation:1].
- Scaling Problems: A model that handles 100 requests per hour beautifully might crash under 100,000 requests. Production systems need to be robust and efficient[citation:9].
- Integration Headaches: The model must connect seamlessly with other software: websites, mobile apps, databases. This requires specific technical interfaces.
- Hidden Bugs: Issues not apparent in testing, like rare edge cases or memory leaks, can surface under continuous use.
- Resource Constraints: In the lab, cost might be no object. In production, the compute power needed to run the model (inference) must be balanced against budget and speed requirements. Fortunately, the cost of AI inference has been dropping dramatically, making it more accessible[citation:1].
MLOps exists to build a bridge over these gaps, creating a repeatable, automated, and monitored pipeline for machine learning models. Research shows that while many companies are experimenting with AI, a much smaller fraction has successfully scaled it across their organization, highlighting the operational challenge[citation:8].

Phase 1: Preparation – Getting Your Model “Production-Ready”
You can't deploy a model straight from a training notebook. The preparation phase transforms a experimental asset into a deployable product.
Step 1: Rigorous Testing and Validation
This goes beyond checking if the model is accurate. You need to test its robustness and fairness.
- Unit Testing: Does each small function in your model code work correctly? This is basic software engineering applied to ML.
- Integration Testing: Does the model work correctly when connected to the data pipeline and the API that will call it?
- Performance Testing: What is the model's accuracy, speed (latency), and resource consumption (like memory)? These become your baseline metrics.
- Fairness and Bias Testing: Does the model perform equally well for different user groups? This is a critical ethical and business check. Techniques to manage model bias are becoming a necessary part of the deployment checklist[citation:9].
- Shadow Testing: A powerful technique where you deploy the new model to run in parallel with the old one, processing real data but not letting its predictions affect users. You log its outputs and compare them to the live system's results. This is a safe way to see how it behaves with real-world data.
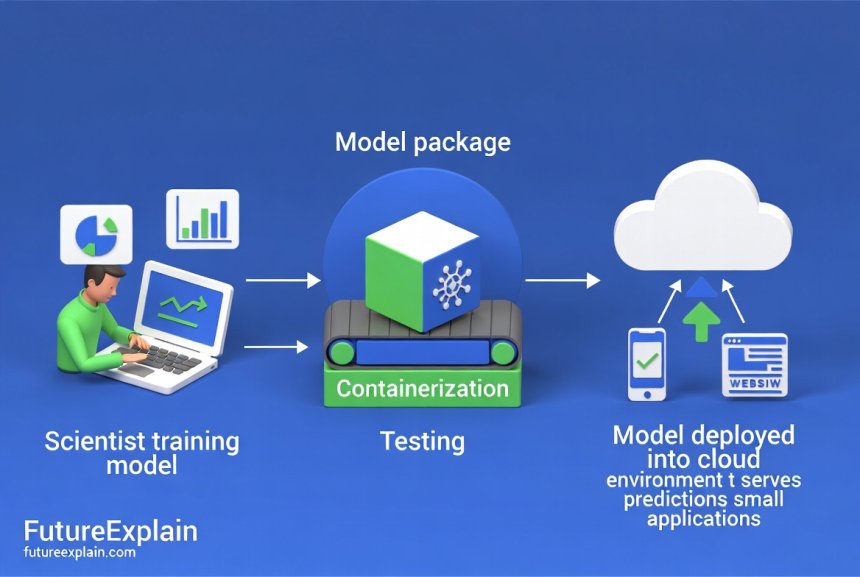
Step 2: Packaging and Containerization
To ensure the model runs the same way everywhere, you package it with its entire environment. This is where containers (like Docker) come in.
- The Dependency Problem: Your model needs specific versions of Python, libraries, and system files. If the production server has different versions, it will fail.
- The Container Solution: A container is a standardized, lightweight box that contains your model code, all its dependencies, and its runtime environment. It's like shipping a fully equipped, miniaturized computer that will run identically on any host machine that supports containers.
- Benefits: Consistency, portability (runs on your laptop, a company server, or any cloud), and isolation from other software on the host system.
Step 3: Model Registry and Versioning
You will update your model. You need a system to manage these versions, just like managing versions of a document.
- Model Registry: A central catalog or library where you store packaged models. Each entry has a unique name and version (e.g., sentiment-analyzer:v1.2).
- Why It's Essential: It allows you to track which model is in production, roll back to a previous version if the new one fails, and promote a model from “testing” to “staging” to “production” status.
Phase 2: Deployment – Launching Your Model to the World
Deployment is about choosing how and where your model will serve predictions (a process called inference).
Choosing a Deployment Strategy
You don't just replace the old model with the new one for everyone at once. Smart strategies reduce risk.
- Canary Deployment: Release the new model to a very small percentage of users or traffic (e.g., 1%). Monitor it closely. If all looks good, gradually increase the percentage to 5%, 25%, and finally 100%.
- A/B Testing: Deploy the new model (Version B) to a random subset of users, while the rest stay on the old model (Version A). Compare key business metrics (not just accuracy) between the two groups. Did Version B lead to more user engagement, sales, or satisfaction? This ties model performance directly to business value.
- Blue-Green Deployment: Maintain two identical production environments: “Blue” (running the current version) and “Green” (running the new version). You switch all user traffic from Blue to Green in an instant. If something goes wrong, you instantly switch back. This requires more infrastructure but offers the fastest rollback.
Where to Deploy: Deployment Targets
The choice depends on your needs for speed, cost, and data privacy.
- Cloud Endpoints: Services like Google Cloud AI Platform, AWS SageMaker, or Azure Machine Learning provide managed endpoints. You upload your model, and they handle the servers, scaling, and security. Ideal for getting started quickly and for variable traffic. The growth of cloud platforms is closely tied to AI development needs[citation:2].
- Serverless Functions: For models that are triggered by events (e.g., “when a user uploads an image”) and don't need to run constantly. You pay only for the milliseconds of compute time used. Highly cost-effective for sporadic workloads.
- On-Device/Edge Deployment: The model runs directly on a user's phone, a car's computer, or a factory sensor. This is crucial for applications requiring instant response (autonomous vehicles) or that must work offline. This trend towards running models “at the edge” is a major theme in the future of technology[citation:9].
- Kubernetes: An open-source system for automating the deployment and management of containerized applications (like your model). It can automatically scale your model up or down based on traffic, restart it if it crashes, and manage rolling updates. It's the industry standard for complex, large-scale deployments.
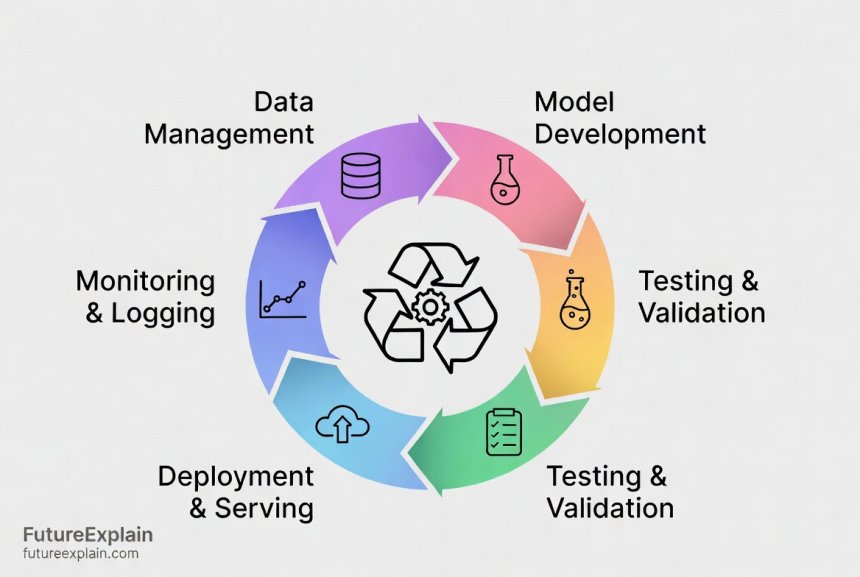
Phase 3: Monitoring and Maintenance – The Never-Ending Job
Deployment is not the finish line; it's the start of a new phase. A model in production must be constantly watched and cared for. Leading organizations are those that actively redesign workflows and implement monitoring to capture value from their AI systems[citation:8].
What to Monitor: The Key Signals
You need a dashboard that tracks more than just “is it running?”.
- Performance Metrics:
- Latency/P95 Latency: How long does it take to get a prediction? The 95th percentile (P95) tells you the speed for 95% of requests, revealing tail-end slowness.
- Throughput: How many predictions per second can it handle?
- Error Rate: The percentage of requests that fail (e.g., due to timeouts or crashes).
- Model Quality Metrics:
- Prediction Drift: Are the model's outputs changing statistically over time? A shift could indicate a problem.
- Data Drift: Are the characteristics of the input data changing? Use statistical tests to compare live data to the training data distribution.
- Business Metrics: Ultimately, does the model's performance translate to business success? If it's a recommendation model, track click-through rate. If it's for fraud detection, track the value of fraud caught versus false alarms.
- System Health: Standard IT monitoring: CPU/RAM usage, network traffic, and container health.
Automated Alerting and Human-in-the-Loop
Monitoring is useless if no one looks at it. Set up automated alerts for when metrics cross a threshold (e.g., “Alert if accuracy drops below 90% for 15 minutes”). However, not every alert requires rolling back the model. Establish a human-in-the-loop process for reviewing predictions when confidence is low or when the system detects potential drift. This human oversight is a key best practice for managing risk[citation:8].
Phase 4: Iteration and Governance – The Cycle Continues
MLOps is a continuous cycle. Insights from monitoring feed directly back into improving the model.
Retraining and the CI/CD Pipeline
When performance degrades due to data drift, or when you collect new, better training data, you need to retrain. Modern MLOps aims to automate this through Continuous Integration and Continuous Delivery (CI/CD) for ML.
- CI (Continuous Integration): Automatically test every new version of the model code as it is developed.
- CD (Continuous Delivery): Automatically package, validate, and deploy the new model to a staging environment, ready for a final manual approval to go to production.
- Continuous Training (CT): An advanced extension where the system automatically retrains the model on a schedule or when drift is detected, running it through the pipeline. This is the pinnacle of automation but requires extremely robust testing.
Model Governance and Cost Management
As you scale, you need rules and oversight.
- Governance: Who can deploy a model? What approval is needed? How are models audited for compliance? Clear policies are essential, especially in regulated industries like finance or healthcare. The responsible AI ecosystem is evolving, with governments showing increased urgency in creating governance frameworks[citation:1].
- Cost Management: Track the cost of training and, more importantly, the ongoing cost of inference. Optimize model size, use efficient hardware, and consider spot instances or serverless options to control expenses. The inference cost for capable AI systems has dropped significantly, but conscious management is still key[citation:1].
Getting Started: A Simple MLOps Roadmap for Beginners
This all might sound complex, but you can start small and grow.
- Start with a Single Model: Choose one important model. Manual deployment is okay for the first time.
- Implement Basic Monitoring: Even if it's just a weekly manual check of accuracy and latency against a log file, start observing.
- Package Your Model: Learn to put your model in a container. This is a fundamental skill that solves the “works on my machine” problem.
- Use a Managed Cloud Service: For your first deployment, use a cloud endpoint. It abstracts away server management and lets you focus on the model itself.
- Automate One Thing: Pick one step to automate next. Maybe it's automated testing when you commit new code, or an alert when the error rate spikes.
- Document Everything: Keep a record of every model version, what changed, how it was tested, and its performance. This is your institutional knowledge.
Remember, the goal of MLOps is not complexity for its own sake. It's reliability, scalability, and velocity. It allows you to trust your AI applications, adapt them quickly, and deliver consistent value. By understanding this pipeline, you move from seeing AI as a magical black box to appreciating it as a robust, engineered system—one that you can build and depend on.
The Bigger Picture: You are not alone in navigating this. Industry surveys show that while AI adoption is widespread, scaling it effectively remains a key challenge. The most successful organizations are those that treat AI deployment not as a one-off IT project, but as an ongoing operational discipline integrated into their business workflows[citation:8]. They invest in the talent and processes for MLOps, seeing it as a core competitive capability for the future[citation:7].
Further Reading
- Cost Optimization for AI: Managing API and Inference Costs – Learn how to manage the budget for running models in production.
- What Is Workflow Automation? Beginner Explanation – Understand the broader concept of automation that MLOps fits into.
- Intelligent Automation Explained (AI + Automation Together) – See how operationalized AI fits into larger business automation strategies.
Share
What's Your Reaction?
 Like
1420
Like
1420
 Dislike
12
Dislike
12
 Love
305
Love
305
 Funny
45
Funny
45
 Angry
8
Angry
8
 Sad
5
Sad
5
 Wow
210
Wow
210
















The infrastructure as code approach is key. Our entire MLOps pipeline is defined in Terraform and Kubernetes manifests. Reproducible across environments.
We built a "model card" for each deployment with essential info: purpose, training data, performance, limitations, owners, etc. Really helps with knowledge sharing.
What's the ROI on all this MLOps investment? We're spending more on operations than on developing new models.
Valid concern, Katalina. The ROI comes from: 1) Reduced incident response time (catching failures early), 2) Increased model utilization (if models are reliable, business uses them more), 3) Faster experimentation (reliable pipelines let data scientists test ideas quicker), 4) Compliance risk reduction. Track metrics like "time from model idea to production" and "production incident frequency" to measure improvement.
How do you handle legal requirements for model auditing? We need to reproduce exact model behavior from 2 years ago for compliance investigations.
We archive everything: model binary, code, dependencies, and training data snapshot. It's heavy but necessary. Docker helps with reproducibility.
For monitoring: we alert on statistically significant changes, not absolute thresholds. A 2% accuracy drop might be noise, but if it's statistically significant for 4 hours, we investigate.
The article could mention data versioning too. If you retrain a model, you need to know exactly which data snapshot was used.