Mitigating Hallucinations: Techniques and Tooling
This guide demystifies AI hallucinations—the tendency for models like ChatGPT to generate plausible-sounding falsehoods. We move beyond just defining the problem to provide a practical, actionable framework for mitigation. You'll learn the root causes of hallucinations, from training data gaps to overconfident generation. The core of the article details a five-level strategy for prevention, starting with foundational prompt engineering and climbing to advanced architectural solutions like Retrieval-Augmented Generation (RAG). We cover essential tools for verification, from simple fact-checking APIs to sophisticated AI-powered evaluation suites, and discuss how to build a responsible workflow that integrates human oversight. Designed for developers, project managers, and business leaders, this resource equips you with the knowledge to build more reliable, trustworthy, and effective AI applications.
If you've ever asked a chatbot for a book recommendation and received a glowing review of a title that doesn't exist, or requested a summary of a research paper only to find invented statistics, you've encountered an AI hallucination. This phenomenon, where a Large Language Model (LLM) generates confident, plausible-sounding information that is factually incorrect or nonsensical, is one of the most significant barriers to trusting and deploying AI in serious applications[citation:1].
Hallucinations aren't a sign that the AI is "lying" in a human sense. They are a byproduct of how these models work—as incredibly sophisticated pattern predictors, not knowledge repositories. The fear they generate, however, is real and can stall valuable projects. The good news is that while hallucinations cannot be eliminated entirely, they can be systematically managed, reduced, and controlled.
This guide is designed for anyone integrating AI into their work, from developers building applications to business leaders overseeing AI adoption. We will move past simple definitions and explore a practical, multi-layered toolkit of techniques and technologies you can use to ground your AI's outputs in reality. Our goal is to transform AI from a risky, unpredictable oracle into a reliable, verifiable partner.
What Exactly Is an AI Hallucination?
At its core, an AI hallucination is a failure of accuracy where the model's generated text diverges from truth or factual reality. Think of it as the AI filling in a gap in its knowledge not with "I don't know," but with its best statistical guess of what *should* come next, based on its training data. This can manifest in several ways:
- Fabrication: Inventing facts, figures, dates, or citations. A classic example is an AI generating a list of academic sources with correct formatting but completely fake authors and titles[citation:1].
- Misrepresentation: Distorting real information. For instance, summarizing a research paper and incorrectly stating it was based on 46 studies instead of the actual 69, or exaggerating the effectiveness of a treatment[citation:1].
- Contextual Failure: Providing a correct fact in the wrong context, like attributing a quote to the wrong person or describing a historical event with anachronistic details.
- Instruction Ignoring: Generating content that directly contradicts a clear constraint or instruction given in the prompt.
It's crucial to understand that this is not a bug but a fundamental characteristic of how generative LLMs operate. They are designed to generate fluent, coherent language by predicting the next most likely token (word or word piece). When the training data is ambiguous, conflicting, or lacks specific information, the model defaults to its primary directive: generate plausible language. The result is a "confabulation"—a convincing narrative built from patterns, not facts.

Visuals Produced by AI
Why Hallucinations Matter: The Real-World Cost
Beyond being a mere curiosity, hallucinations pose tangible risks that scale with the importance of the AI's task.
- Eroded Trust: A single, obvious hallucination can destroy user confidence in an entire system. If an AI assistant gives wrong product information or a legal research tool cites a non-existent case, users will abandon it.
- Operational Errors: In business automation, a hallucination could generate incorrect code, populate a database with bad data, or draft an email with false claims, leading to wasted time and potential reputational damage.
- Legal and Compliance Risk: In regulated industries like finance or healthcare, providing inaccurate information based on an AI's hallucination could have serious compliance and liability implications.
- Amplification of Bias: Hallucinations can perpetuate and amplify biases present in the training data. If an AI, tasked with generating candidate profiles, hallucinates details that align with gender or racial stereotypes, it actively reinforces harmful biases[citation:4].
- Decision-Making Hazard: For leaders using AI for analytics or summarization, acting on a hallucinated insight could lead to poor strategic decisions. The model's confident tone makes these errors particularly dangerous.
Understanding these stakes is the first step toward prioritizing mitigation. It shifts the conversation from "Can we build with AI?" to "How can we build *responsibly* with AI?"
The Root Causes: Why Do AI Models Hallucinate?
Effective mitigation starts with diagnosis. Hallucinations spring from several interconnected sources within the AI's architecture and training:
- Training Data Limitations: An LLM's knowledge is frozen at the point of its last training update. It has no innate knowledge of world events, new products, or internal company data that emerged afterward. When asked about these, it hallucinates. Furthermore, if its training data contained errors, contradictions, or "common knowledge" myths, it will reproduce them.
- The Statistical Nature of Generation: As mentioned, LLMs are probability machines. They choose sequences of words that are statistically likely, not necessarily true. In the absence of a strong "signal" for the correct answer, noise can take over.
- Over-Optimization for Fluency: Models are heavily optimized to produce human-like, fluent text. This objective can sometimes conflict with the objective of factual accuracy. A fluent, confident-sounding but incorrect answer may score higher in training than a hesitant but correct one.
- Prompt Ambiguity: Vague, broad, or overly complex prompts give the model too much room to invent. A prompt like "Tell me about the history of solar power" is an invitation to hallucinate details. A more grounded prompt like "List three key milestones in the adoption of residential solar panels in the U.S. between 2000 and 2010, citing reputable sources" provides guardrails.
- Lack of a "Don't Know" Function: Most general-purpose LLMs are not designed to reliably express uncertainty or refuse to answer questions outside their knowledge scope. Their default setting is to generate a response.
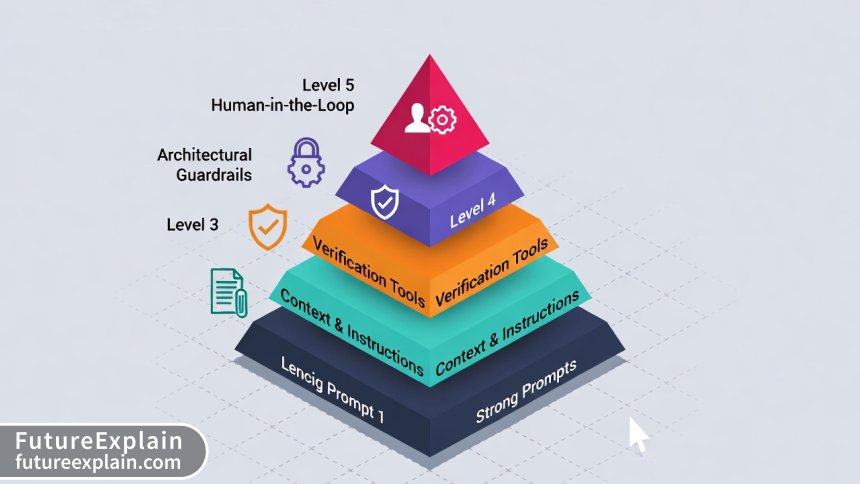
A Five-Level Framework for Mitigating Hallucinations
Tackling hallucinations requires a defense-in-depth strategy. Don't rely on a single silver bullet. Instead, implement controls at multiple layers, from the simple prompt to the overall system architecture.
Level 1: Foundation – Advanced Prompt Engineering
Your first and most accessible line of defense is the prompt itself. Well-crafted instructions can dramatically steer the model away from invention.
- Provide Clear Instructions and Role: Start by assigning a role that implies responsibility. "You are a careful and accurate research assistant who verifies facts before stating them. If you are uncertain, you say so."
- Use Few-Shot and Chain-of-Thought Prompting: Provide examples within your prompt. Show the model the *format* and *reasoning process* you want. For example: "Q: What is the capital of France? A: Let me recall. France is a country in Europe. I know its capital is Paris. I am confident. The capital is Paris." Then ask your real question. This guides the model to mimic a verification step[citation:2].
- Incorporate Grounding Context: Place the relevant, verified information directly in the prompt. Instead of asking "Summarize this quarter's sales," structure it as: "Based on the following sales data: [paste data]. Provide a summary focusing on top-performing regions." This anchors the model to your text.
- Ask for Citations and Source References: Instruct the model to cite its sources or quote directly from the provided context. The act of needing to reference can reduce loose fabrication. For example: "Answer the following question using only the text provided below. For any key claim, cite the relevant sentence from the text using its paragraph number."
Level 2: Architectural Solution – Retrieval-Augmented Generation (RAG)
When your questions require knowledge beyond a single prompt's context, RAG is the most powerful anti-hallucination tool available today. RAG works by separating the knowledge store from the language generator.
Here’s how it works: When a user asks a question, the system first queries a searchable database of trusted documents (your company wiki, product manuals, approved research). It retrieves the most relevant text passages. Then, it passes *only those retrieved passages* as context to the LLM, instructing it to form an answer based solely on that provided text. This ensures the model's "knowledge" for that query is fresh, controlled, and verifiable.
For a practical, step-by-step guide on implementing this powerful technique, see our tutorial on Retrieval-Augmented Generation (RAG) — Advanced Practical Guide.
Level 3: Tool-Based Verification
Use specialized tools to check the AI's work automatically or make verification easier for humans.
- Fact-Checking APIs: Services exist that can take a generated statement and cross-reference it against known knowledge bases or the live web to flag potential inaccuracies.
- Embedding-Based Consistency Checkers: After generating a long text (like a report), you can use the AI to break it down into individual claims. Each claim can be converted into a numerical vector (an embedding). The system can then search your trusted knowledge base for text with similar vectors. If no close match is found for a critical claim, it gets flagged for human review.
- Self-Reflection Prompts: Build a two-step process. First, the AI generates an answer. Second, you prompt the same AI with: "Review the following answer for potential factual inaccuracies or hallucinations. List any statements that may need verification." Often, the model can catch its own more obvious errors in this reflective mode.
Level 4: System Guardrails and Model Choice
Your choice of model and the rules you wrap around it form another critical layer.
- Choose Models with Guardrails: Some API providers and open-source models now come with built-in systems designed to reduce hallucinations or express uncertainty. Research and select models that prioritize factual accuracy.
- Implement Output Parsing and Validation: For structured tasks (like generating JSON data), use strict output parsers. If the AI's response doesn't match the required schema (e.g., a date is in the wrong format, a required field is missing), the system automatically rejects it and asks for a regeneration.
- Use Confidence Scores: Some model APIs return a confidence score or token-level probabilities for the generated text. While not perfect, very low confidence on a specific segment can be a signal to flag it or seek human input.
Level 5: The Essential Human-in-the-Loop
No fully automated system is 100% reliable for high-stakes tasks. The final, non-negotiable layer is human oversight.
Design workflows where AI is a draft generator or an assistant, not a final authority. This is especially true in fields like healthcare, law, and finance, where AI is increasingly used as a support tool for diagnostics, research, and analysis, but the final decision remains with the professional[citation:4][citation:6]. Establish clear protocols:
- Critical Point Review: For a marketing email, a human reviews the final copy. For a code module, a developer reviews the logic.
- Source Spot-Checking: Have reviewers randomly verify a percentage of the AI's citations or key facts against the source material.
- Feedback Loops: When a human corrects a hallucination, that correction should be logged and, where possible, fed back into the knowledge base or used to improve the prompts, creating a learning system.
This human-centric approach is the cornerstone of effective Human plus AI Collaboration.
Visuals Produced by AI
Building a Responsible AI Workflow: A Practical Blueprint
Let's translate these levels into a concrete plan for a project, such as building an AI assistant that answers customer questions based on a product manual.
- Define Acceptable Risk: For pre-sale product questions, a hallucination about a product spec is high risk. For a general company history question, it's lower risk. Define your tolerance.
- Architect with RAG: Build the core of your assistant using a RAG system. Ingest all your product PDFs, help articles, and official documentation into a vector database. This is your single source of truth.
- Craft Robust Prompts: Create a system prompt for the LLM that says: "You are a helpful and accurate support agent. Answer the user's question using ONLY the following context retrieved from our documentation. Do not use any outside knowledge. If the answer is not clearly in the context, say 'I cannot find a specific answer to that in our documentation, but I can connect you with a live agent for help.'"
- Implement Tool Verification (Optional but Recommended): For high-risk queries (e.g., containing words like "warranty," "safety," "price"), run the AI's generated answer through a quick consistency check against the retrieved chunks.
- Design the Human Handoff: Make the "I cannot find..." response trigger a smooth, automatic ticket creation in your support system, handing off to a human agent.
- Monitor and Iterate: Log all queries and answers. Have support leads periodically review logs for potential inaccuracies. Use these findings to improve your documentation (the knowledge base) and refine your prompts.
Future Directions and Evolving Tools
The fight against hallucinations is a primary focus of AI research. Emerging trends to watch include:
- Better Base Models: New model architectures and training techniques, such as reinforcement learning from human feedback (RLHF) focused on truthfulness, are producing base models that are inherently less prone to fabrication.
- Advanced RAG Techniques: Methods like "hypothetical document embeddings" and recursive retrieval are making RAG systems smarter at finding the exact right context, further reducing gaps where hallucinations can creep in.
- Integrated Tool Use (AI Agents): Future AI systems won't just generate text; they will be programmed to use tools like calculators, code executors, and web search APIs by themselves. This allows them to *compute* answers or *look up* facts in real-time rather than relying solely on parametric memory, drastically cutting down on numerical and factual errors. Learn more about this evolving paradigm in our article on AI Agents.
- Standardized Evaluation Benchmarks: The community is developing better standardized tests (like "TruthfulQA") to measure a model's propensity to hallucinate, allowing for clearer comparisons between models and tools.
Conclusion: Towards Trustworthy AI
Mitigating hallucinations is not about achieving perfection; it's about managing risk and building trust. By understanding the why, and systematically applying the layered how—from smart prompting to RAG architecture to human review—you can harness the incredible power of generative AI while safeguarding your projects, your users, and your reputation.
The most reliable AI system is one that knows its limits, is grounded in verified information, and is designed to collaborate with human intelligence. Start by implementing one or two techniques from Level 1 and 2, measure the improvement in output quality, and build your robust framework from there. The path to dependable AI is iterative, but each step makes your applications more powerful and trustworthy.
Further Reading
- Prompt Engineering in 2025: Patterns That Actually Work – Deepen your skills in crafting prompts that guide AI toward accurate outputs.
- AI Myths vs Reality: What AI Can and Cannot Do – Ground your understanding of AI's fundamental capabilities and limitations.
- Evaluation Suites: Building Tests That Catch Failures – Learn how to systematically test your AI applications for errors like hallucinations.
Share
What's Your Reaction?
 Like
1245
Like
1245
 Dislike
18
Dislike
18
 Love
342
Love
342
 Funny
45
Funny
45
 Angry
12
Angry
12
 Sad
9
Sad
9
 Wow
287
Wow
287
















We're in the legal tech space. The "Human-in-the-Loop" isn't just Level 5 for us; it's the entire foundation. The AI drafts, spots potential issues, and suggests precedents, but a lawyer reviews every line. This framework validates our approach. Thanks!
This should be required reading for every product manager spec'ing an AI feature. The "Real-World Cost" section alone would prevent so many bad, rushed launches.
The article mentions "confidence scores" from APIs. In practice, I've found these scores to be almost useless for catching subtle hallucinations. The model is very confident about its fabricated facts. Does anyone have experience with more reliable confidence metrics or tools?
David, I agree. Raw token probability is a poor proxy for truth. We've had better luck with the embedding-based consistency check mentioned in Level 3. It's more work to set up, but it directly tests if the AI's claim is *semantically similar* to anything in our trusted knowledge base. It catches a different class of error.
Implementing the "self-reflection prompt" (Level 3) has been a game-changer for our content generation workflow. We have the AI draft a blog section, then ask it to critique its own draft for factual claims that need citations. It catches about 70% of the issues before it even gets to our editor.
The comparison of RAG to having a "source folder" open is genius. I finally get it. We've been feeding whole documents into the context window and wondering why it still goes off-track. Retrieving only the relevant bits first is the key we were missing.
As an educator, I'm trying to teach students about AI literacy. The section on "Root Causes" is perfect for explaining to them *why* ChatGPT makes things up, rather than just telling them it happens. Can I use a simplified version of your five-level pyramid as a teaching aid?
Absolutely, Samira! Please do. We create these resources to be used and shared to promote understanding. I'm glad it's useful for your students. If you create a version, we'd love to see it.