Privacy-Preserving AI: Differential Privacy & Federated Learning
This beginner-friendly guide explains two crucial privacy-preserving AI techniques: differential privacy and federated learning. You'll learn how differential privacy adds mathematical noise to datasets to protect individual information while maintaining useful statistical insights, and how federated learning enables AI models to train across multiple devices without centralizing sensitive data. We explore real-world applications from smartphone keyboard predictions to healthcare research, compare the strengths and limitations of each approach, and provide practical guidance for implementation. The article also covers emerging trends, regulatory considerations, and how these technologies work together to create more ethical, trustworthy AI systems that respect user privacy while delivering powerful capabilities.

Privacy-Preserving AI: Differential Privacy & Federated Learning
As artificial intelligence becomes increasingly integrated into our daily lives—from personalized recommendations to healthcare diagnostics—a critical question emerges: how can we benefit from AI's capabilities while protecting our personal privacy? Traditional AI systems often require collecting and centralizing vast amounts of data, creating significant privacy risks and potential for abuse. Privacy-preserving AI addresses this fundamental tension, offering technical approaches that allow AI to learn from data without compromising individual privacy.
This guide explores two of the most important privacy-preserving techniques in modern AI: differential privacy and federated learning. Whether you're a business leader considering AI implementation, a developer building ethical applications, or simply someone concerned about digital privacy, understanding these approaches will help you navigate the evolving landscape of responsible technology.
We'll start with foundational concepts, then dive deep into how each technique works, examine real-world applications, and finally explore how they can be combined for maximum privacy protection. Along the way, we'll use simple analogies and practical examples to make these technical concepts accessible to everyone.
Why Privacy-Preserving AI Matters Now
Before examining specific techniques, it's important to understand why privacy-preserving AI has become such an urgent priority. Traditional AI development follows a straightforward pattern: collect as much data as possible, centralize it in servers, train models on this data, and deploy those models to make predictions. This approach has powered everything from social media algorithms to voice assistants, but it comes with significant drawbacks:
- Privacy Risks: Centralized data repositories become attractive targets for hackers and potential sources of surveillance
- Regulatory Compliance: Laws like GDPR in Europe and CCPA in California impose strict requirements on data collection and usage
- User Trust: People are increasingly concerned about how their data is used and shared
- Data Silos: Valuable data often remains locked in organizations or on devices due to privacy concerns
Privacy-preserving techniques aim to address these challenges by redesigning how AI systems learn from data. Rather than asking \"How can we collect more data?\" they ask \"How can we learn from data without actually seeing it?\" or \"How can we extract useful insights while mathematically guaranteeing privacy?\" This shift in perspective is transforming how organizations approach AI development.
If you're interested in the broader ethical context of AI, our guide on AI Ethics & Safety provides foundational knowledge about responsible AI development.
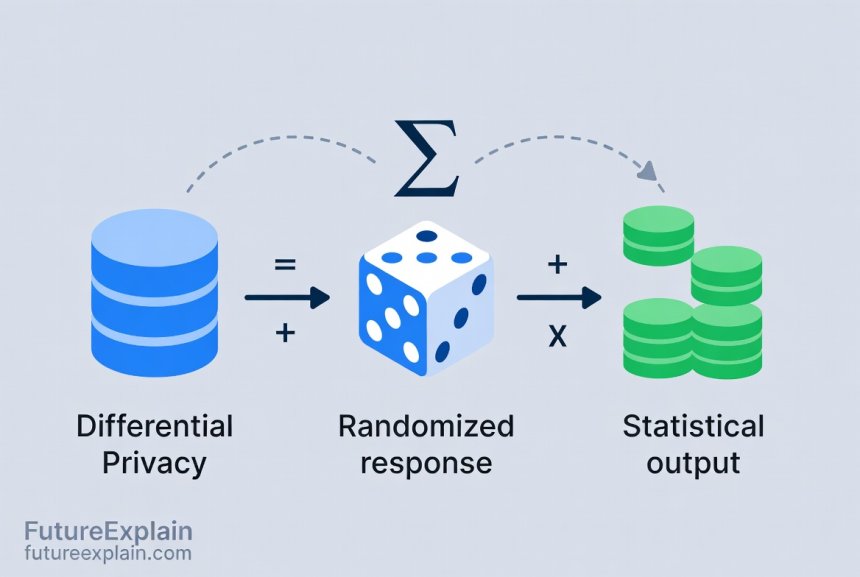
Differential Privacy: Mathematical Privacy Guarantees
Differential privacy is a rigorous mathematical framework for privacy protection that originated in academic research and has since been adopted by major technology companies including Apple, Google, and Microsoft. At its core, differential privacy provides a quantifiable, mathematical guarantee about the privacy risk incurred when someone's data is included in a dataset.
The fundamental insight of differential privacy is that we can protect individual privacy by carefully adding \"noise\" (randomness) to the outputs of data analysis. This noise is calibrated to be large enough to obscure any single individual's contribution but small enough that overall statistical insights remain accurate. Think of it like a crowd photo where individual faces are slightly blurred—you can still see the overall scene and make observations about the crowd, but you can't identify specific people.
How Differential Privacy Works: The Technical Essence
Differential privacy centers around a key parameter called epsilon (ε), which quantifies the \"privacy budget\" or amount of privacy loss. A smaller ε means stronger privacy protection but potentially less accurate results, while a larger ε means better accuracy but weaker privacy guarantees.
The mathematical definition is elegant: a randomized algorithm satisfies ε-differential privacy if, for any two datasets that differ in only one individual's data, the probability of getting any particular output is roughly the same (within a factor of e^ε). In practical terms, this means that whether or not your data is included in the analysis, the results will be essentially indistinguishable to an outside observer.
Implementation typically involves these key mechanisms:
- Laplace or Gaussian Mechanism: Adding carefully calibrated random noise drawn from specific probability distributions to query results
- Exponential Mechanism: Randomizing selection from a set of possible outputs rather than adding noise to numerical results
- Composition Theorems: Methods for tracking and bounding cumulative privacy loss across multiple queries
For example, if a healthcare researcher wants to know the average age of patients with a certain condition while protecting individual privacy, differential privacy wouldn't return the exact average. Instead, it would add a small amount of random noise to the result—enough that you couldn't deduce any individual's age, but still close enough to the true average to be statistically useful.
Real-World Applications of Differential Privacy
Differential privacy has moved from theoretical research to practical implementation in several high-profile applications:
- Census Data: The U.S. Census Bureau uses differential privacy to protect individual responses while publishing demographic statistics. This prevents reconstruction attacks where anonymized data can be de-anonymized by combining with other data sources.
- Apple's Data Collection: Apple uses differential privacy to learn usage patterns across devices without identifying individual users. For instance, they can discover common emoji usage or problematic websites in Safari without knowing which specific users contributed to those patterns.
- Google's Chrome: Chrome uses differential privacy to collect browser statistics that help identify performance issues and security threats while protecting user privacy.
- Healthcare Research: Hospitals and research institutions use differential privacy to share medical insights without revealing sensitive patient information.
The key advantage of differential privacy is its strong mathematical foundation—when implemented correctly, it provides provable privacy guarantees regardless of what auxiliary information an attacker might have. This makes it particularly valuable in high-stakes applications where privacy breaches could have serious consequences.
Limitations and Practical Considerations
Despite its theoretical elegance, differential privacy has practical challenges:
- Accuracy Trade-offs: Strong privacy protection (low ε) requires more noise, which reduces accuracy, especially for small datasets or complex queries
- Implementation Complexity: Correctly implementing differential privacy requires expertise to avoid subtle mistakes that could undermine the privacy guarantees
- Privacy Budget Management: Organizations must carefully track and limit how much of the privacy budget they \"spend\" on different analyses
- Performance Overhead: The computational cost of adding and managing noise can be significant for some applications
These limitations mean differential privacy isn't a one-size-fits-all solution, but rather a powerful tool in the privacy-preserving toolkit that works best for specific use cases, particularly statistical analysis of large datasets.
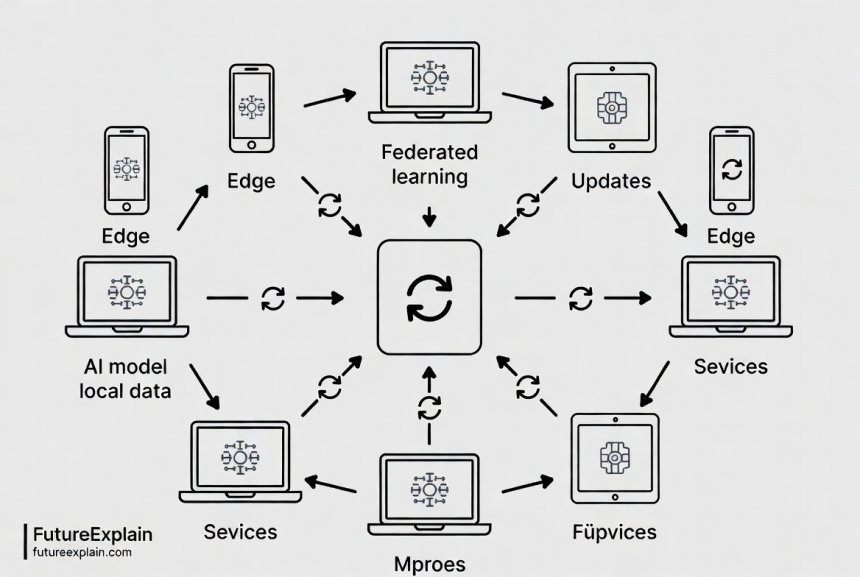
Federated Learning: Training Without Centralized Data
While differential privacy focuses on protecting data during analysis, federated learning takes a fundamentally different approach: it changes where the analysis happens. Instead of bringing data to a central model, federated learning brings the model to the data—training occurs locally on devices or within organizations, and only model updates (not raw data) are shared.
Imagine a group of chefs trying to improve a recipe. Instead of everyone bringing their secret ingredients to a central kitchen where they could be copied (traditional centralized learning), each chef experiments independently in their own kitchen. They then share only what they learned—\"adding a pinch of salt improved the flavor\" or \"cooking for 5 minutes less made it more tender\"—without revealing their exact ingredients or techniques. The collective wisdom improves everyone's cooking without anyone giving up their secrets.
Google introduced federated learning in 2016 to improve keyboard prediction on Android phones without uploading sensitive typing data to their servers. Since then, the approach has expanded to numerous applications across healthcare, finance, and other privacy-sensitive domains.
The Federated Learning Process: Step by Step
A typical federated learning system follows this iterative process:
- Initialization: A central server creates an initial global model and sends it to participating devices or organizations
- Local Training: Each device trains the model on its local data for a set number of iterations
- Update Transmission: Devices send their model updates (gradients or weights) back to the server
- Secure Aggregation: The server combines these updates using techniques like Federated Averaging to create an improved global model
- Model Redistribution: The updated global model is sent back to devices, and the cycle repeats
This process enables continuous improvement while keeping raw data decentralized. Advanced implementations add additional privacy protections, such as encrypting the updates before transmission or applying differential privacy to the updates themselves.
Types of Federated Learning
Federated learning comes in several flavors, each suited to different scenarios:
- Cross-Device Federated Learning: The most common type, involving many consumer devices like smartphones. Characterized by a large number of participants (millions), unreliable connectivity, and heterogeneous data distributions.
- Cross-Silo Federated Learning: Involves a smaller number of organizations (like hospitals or banks) collaborating. Participants are more reliable, have more computational resources, but may have greater concerns about data leakage between competitors.
- Horizontal vs. Vertical Federated Learning: Horizontal federated learning involves participants with the same features but different samples (e.g., different hospitals with similar patient records). Vertical federated learning involves participants with different features but overlapping samples (e.g., a bank and an e-commerce company with information about the same customers).
The choice between these approaches depends on the specific application, available infrastructure, and privacy requirements. For example, improving smartphone keyboard predictions naturally fits cross-device federated learning, while collaborative medical research between hospitals might use cross-silo horizontal federated learning.
Real-World Applications and Success Stories
Federated learning has moved beyond research to practical deployment in several domains:
- Mobile Keyboard Predictions: As mentioned, Google's Gboard uses federated learning to improve next-word prediction and autocorrect without uploading what users type. The system has trained on billions of messages while keeping the content private.
- Healthcare Diagnostics: Hospitals can collaboratively improve medical imaging AI models without sharing sensitive patient scans. For instance, the MELLODDY project demonstrated how pharmaceutical companies could use federated learning to improve drug discovery while protecting proprietary compound data.
- Financial Fraud Detection: Banks can develop better fraud detection models by learning from patterns across institutions without exposing customer transaction data.
- Industrial IoT: Manufacturing equipment from different factories can learn collectively to predict maintenance needs while keeping each factory's operational data private.
These applications demonstrate how federated learning enables collaboration in domains where data cannot be centralized due to privacy regulations, competitive concerns, or technical constraints.
Challenges and Limitations of Federated Learning
Despite its promise, federated learning faces several practical challenges:
- Statistical Heterogeneity: Data on different devices often isn't identically distributed (some users type differently, some hospitals treat different patient populations), which can slow convergence or reduce model quality
- System Heterogeneity: Devices vary in computational capability, network connectivity, and availability, making coordination difficult
- Communication Overhead Sending model updates can consume significant bandwidth, especially for large models
- Security Vulnerabilities: Model updates can sometimes leak information about the training data, requiring additional protections
- Orchestration Complexity: Managing thousands or millions of participating devices requires sophisticated software infrastructure
Addressing these challenges is an active area of research, with developments in areas like adaptive federated optimization, compression techniques for model updates, and enhanced privacy protections.
Comparing Differential Privacy and Federated Learning
While both differential privacy and federated learning aim to preserve privacy, they approach the problem from different angles with distinct strengths and limitations. Understanding these differences helps determine which approach (or combination) is best for a particular application.
Philosophical Differences: Differential privacy assumes data will be centralized but protects it through mathematical noise. Federated learning avoids centralization altogether by distributing the computation.
Privacy Guarantees: Differential privacy offers provable mathematical guarantees that hold even against attackers with unlimited computational power and auxiliary information. Federated learning's privacy protections are more architectural—by keeping data local, it reduces exposure surfaces, but model updates might still leak information without additional safeguards.
Data Utility: Differential privacy can reduce accuracy, especially for complex queries or small datasets. Federated learning typically maintains higher model accuracy since it uses the actual data for training, though statistical heterogeneity across devices can reduce effectiveness.
Implementation Complexity: Both approaches require specialized expertise, but for different reasons. Differential privacy demands careful mathematical calibration of noise parameters. Federated learning requires distributed systems engineering to manage many devices and handle failures gracefully.
Best Use Cases: Differential privacy excels when centralized analysis is necessary or desirable, such as official statistics, research datasets, or any scenario requiring strong mathematical privacy guarantees. Federated learning shines when data naturally resides on edge devices or in separate organizations that cannot or will not share it, such as mobile applications, healthcare collaborations, or competitive business environments.
In practice, these approaches are often complementary rather than competitive. Many real-world systems combine them—using federated learning to avoid centralizing raw data, then applying differential privacy to the model updates for additional protection.
Combining Approaches: Hybrid Privacy-Preserving Systems
The most robust privacy-preserving AI systems often combine multiple techniques to address different attack vectors and requirements. By layering protections, these hybrid systems can achieve stronger privacy with better utility than any single approach alone.
A common pattern is federated learning with differential privacy, where devices add carefully calibrated noise to their model updates before sending them to the central server. This protects against privacy leaks that might occur even from model updates, especially important when dealing with sensitive data or untrusted servers.
Another powerful combination is federated learning with secure multi-party computation (MPC) or homomorphic encryption. These cryptographic techniques allow the server to aggregate model updates without ever seeing them in plaintext, providing strong confidentiality guarantees even against a malicious central server.
For example, a healthcare consortium might use:
- Federated learning to keep patient data within each hospital
- Differential privacy on model updates to prevent reconstruction of individual records
- Secure aggregation to prevent the central coordinator from learning individual hospital contributions
- Formal verification to ensure the system doesn't memorize sensitive patterns
This defense-in-depth approach mirrors cybersecurity best practices, where multiple layers of protection create a more resilient system than any single barrier.
Implementing Privacy-Preserving AI: Practical Guidance
For organizations considering privacy-preserving AI, here's a practical roadmap:
1. Assess Your Needs and Constraints: Begin by identifying what you need to protect (what data, whose privacy), regulatory requirements (GDPR, HIPAA, etc.), technical constraints (device capabilities, network conditions), and what you hope to achieve (what insights or model improvements).
2. Start Simple, Then Add Complexity: Begin with the simplest approach that meets your core requirements. For many applications, basic federated learning or differentially private statistics might be sufficient. Add more sophisticated protections only as needed.
3. Use Established Frameworks and Libraries: Several open-source frameworks simplify implementation: - TensorFlow Federated and PySyft for federated learning - Google's Differential Privacy Library and IBM's Differential Privacy Library for differential privacy - OpenMined tools for combining multiple privacy techniques
4. Validate and Test Thoroughly: Privacy-preserving techniques can fail in subtle ways. Conduct rigorous testing, including privacy attacks (trying to extract training data from the model) and utility testing (ensuring results remain useful).
5. Plan for Ongoing Maintenance: Privacy-preserving systems often require more maintenance than traditional approaches—managing device participation, tracking privacy budgets, updating cryptographic protocols as threats evolve.
If you're just starting with AI implementation, our guide on AI for Small Businesses offers foundational advice that applies to privacy-preserving approaches as well.
The Future of Privacy-Preserving AI
Privacy-preserving AI is rapidly evolving, with several exciting trends shaping its future:
1. Hardware-Enabled Privacy: New hardware features, like trusted execution environments (TEEs) in processors, provide hardware-level isolation for sensitive computations. This enables new approaches that combine hardware security with algorithmic privacy.
2. Synthetic Data Generation: Advanced generative models can create synthetic datasets that preserve statistical patterns of real data while containing no actual personal information. When combined with privacy guarantees, this approach could enable data sharing without privacy risks.
3. Regulatory Evolution: Privacy regulations worldwide are beginning to recognize and encourage privacy-preserving techniques. The GDPR specifically mentions data pseudonymization as a recommended practice, and future regulations may provide \"safe harbors\" for techniques like differential privacy.
4. Standardization and Certification: As these techniques mature, we're seeing efforts to standardize implementations and create privacy certifications. The IETF is working on standards for privacy-preserving measurement, while organizations like NIST are developing guidelines and testing methodologies.
5. Cross-Disciplinary Integration: Privacy-preserving AI increasingly draws from multiple fields—cryptography, statistics, distributed systems, law, and ethics. This cross-pollination leads to more robust and practical solutions.
These developments suggest that privacy-preserving techniques will become increasingly accessible and integrated into mainstream AI development rather than remaining specialized tools for edge cases.
Ethical Considerations and Responsible Implementation
While privacy-preserving techniques address important ethical concerns, they don't automatically make AI systems ethical. Several additional considerations remain:
Transparency and Explainability: Privacy-preserving techniques can make AI systems less transparent. Adding noise or distributing computation makes it harder to understand why a model makes certain predictions. Techniques like explainable AI must be adapted to work with privacy-preserving approaches.
Fairness and Bias: Privacy protections can sometimes exacerbate or obscure bias. For example, differential privacy's noise addition might disproportionately affect small demographic groups, while federated learning might amplify biases if some devices have unrepresentative data. Regular fairness audits remain essential.
Informed Consent: Even with privacy protections, users should understand how their data contributes to AI systems. Clear communication about what's being protected and what risks remain is crucial for ethical implementation.
Power Dynamics: Privacy-preserving techniques can shift power dynamics—giving individuals more control over their data but potentially concentrating technical expertise in large organizations. Thoughtful design should consider these distributional effects.
Our article on Ethical AI Explained delves deeper into these broader ethical considerations beyond privacy.
Getting Started with Privacy-Preserving AI
Whether you're an individual developer, a business leader, or simply someone interested in the field, here are practical steps to engage with privacy-preserving AI:
For Developers and Data Scientists: - Experiment with open-source frameworks like TensorFlow Federated or PySyft on simple problems - Take online courses on Coursera or edX about privacy-preserving techniques - Start implementing basic differential privacy in your data analyses - Join communities like OpenMined to learn from practitioners
For Business Leaders and Decision-Makers: - Educate yourself on the basics to ask informed questions of your technical teams - Consider pilot projects in non-critical areas to build organizational experience - Evaluate vendors not just on their AI capabilities but on their privacy-preserving approaches - Develop clear policies about when and how to use these techniques
For Everyone Concerned About Privacy: - Learn the basics to make informed choices about the services you use - Support organizations that implement strong privacy protections - Advocate for responsible regulations that encourage privacy-preserving innovation - Consider privacy implications when choosing between competing services or products
Privacy-preserving AI represents a fundamental shift in how we think about data and learning. By designing systems that respect privacy from the ground up, we can harness AI's potential while maintaining the confidentiality and autonomy that are essential in a democratic society.
Conclusion: Toward a Privacy-Respecting AI Future
Differential privacy and federated learning represent two powerful approaches to one of AI's most pressing challenges: how to learn from data without compromising individual privacy. While they approach the problem differently—one through mathematical noise, the other through distributed computation—both move us toward AI systems that respect fundamental privacy rights.
As these techniques mature and combine with other privacy-enhancing technologies, we're moving toward a future where powerful AI doesn't require mass surveillance, where organizations can collaborate without exposing sensitive data, and where individuals can benefit from personalized services without sacrificing control over their information.
The journey toward privacy-preserving AI is just beginning, but the direction is clear: the most successful and sustainable AI systems will be those that respect privacy not as an afterthought or compliance burden, but as a core design principle. By understanding and implementing techniques like differential privacy and federated learning, we can build AI that serves humanity without compromising our fundamental rights.
For more on how AI is transforming various sectors while addressing ethical concerns, explore our articles on AI in Healthcare, AI in Finance, and AI Regulation Overview.
Share
What's Your Reaction?
 Like
2150
Like
2150
 Dislike
12
Dislike
12
 Love
340
Love
340
 Funny
45
Funny
45
 Angry
8
Angry
8
 Sad
3
Sad
3
 Wow
280
Wow
280

















I'm a student studying computer science, and this article has inspired me to focus on privacy-preserving AI for my thesis. It feels like an area where I can make a real positive impact.
That's wonderful to hear, Maisie! Privacy-preserving AI is a fantastic area for research with both theoretical depth and practical impact. Feel free to reach out if you'd like suggestions for research directions or resources as you develop your thesis.
The conclusion about building AI that serves humanity without compromising fundamental rights perfectly captures why this work matters. It's not just about technology - it's about the kind of future we want to build.
I've shared this article with my entire team. It's become required reading for anyone working on our AI initiatives. Thank you for such a comprehensive and accessible overview.
The section on informed consent was particularly important. Even with privacy-preserving techniques, we should still be transparent with users about how their data contributes to AI systems.
As a compliance officer, I appreciate how this article connects technical approaches to regulatory requirements. It helps me have more informed conversations with our engineering team.
This article has fundamentally changed how I think about AI and privacy. Instead of seeing them as inherently in conflict, I now see them as challenges we can solve with the right technical approaches.