How Does Machine Learning Work? Explained Simply
This article explains machine learning (ML) in plain language for beginners and non-technical decision-makers. It defines ML, compares the main types (supervised, unsupervised, reinforcement), and walks through a simple, step-by-step example: training a classifier from data collection through evaluation. The guide covers common terms (features, labels, training, overfitting), practical pitfalls to avoid, and a beginner's learning roadmap with safe, low-cost ways to experiment. Two in-article image placeholders are included to help readers visualize the data→model→prediction cycle. The article emphasizes pragmatic, responsible use and points to short hands-on resources so readers can try ML without heavy investment.


How Does Machine Learning Work? Explained Simply
Machine learning (ML) powers many helpful features we use every day — from search autocomplete to photo filters and fraud detection. But under the surface ML can look intimidating. This article explains exactly how ML works in straightforward steps so beginners, students, and decision-makers can understand the basic ideas and try small, safe experiments of their own.
1. What is machine learning — a short definition
Machine learning is a set of techniques that lets computers learn patterns from data and make predictions or decisions without being explicitly programmed with rules for every case. Instead of writing step-by-step instructions, we show examples (data) and let algorithms find patterns that generalize to new cases.
2. The basic idea in one sentence
Give a machine many examples (inputs) and the correct answers (labels) when available, let it learn a function that maps inputs to outputs, then use that function to make predictions on new inputs.
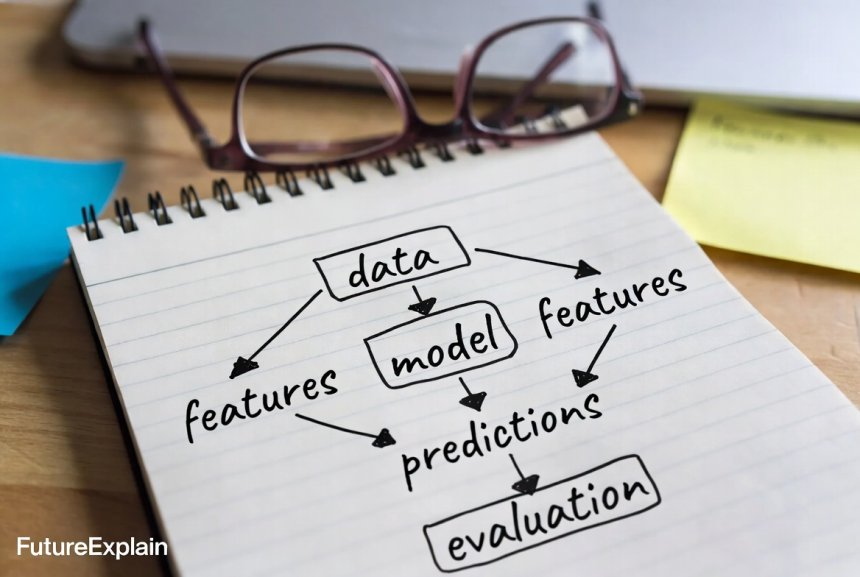
3. The common ML workflow (simple, step-by-step)
- Collect data: Gather examples that represent the problem — images, text, logs, numeric tables.
- Prepare data: Clean, label, and transform the data into a form models can use (this includes creating features).
- Choose a model: Pick a learning algorithm (simple linear model, decision tree, neural network, etc.).
- Train the model: Use training data to adjust the model parameters so predictions match the correct answers as closely as possible.
- Evaluate: Test the model on held-out data to estimate how well it performs on new examples.
- Deploy and monitor: Put the model into an application, then monitor for errors and data drift and update as needed.
Most real-world ML work is spent on data collection and preparation rather than on fancy algorithms. Good data often beats fancy models.
4. Key terms explained
- Feature: A measurable property or attribute of the input (e.g., word counts for text, pixel values for images).
- Label: The correct answer we want the model to predict (e.g., 'spam' or 'not spam').
- Model: The mathematical function (with parameters) that maps features to predictions.
- Training: The process of adjusting model parameters using labeled data.
- Inference: Using a trained model to make predictions on new data.
- Overfitting: When a model learns noise in the training data and performs poorly on new data.
5. Main types of machine learning (short)
- Supervised learning: Models learn from labeled examples (input + desired output). Common tasks: classification and regression.
- Unsupervised learning: Models find structure in unlabeled data (clustering, dimensionality reduction).
- Reinforcement learning: An agent learns by receiving rewards or penalties while interacting with an environment.
For most beginner projects, supervised learning is the easiest and most practical place to start because labels provide a clear way to measure success.
6. A concrete, simple example — training a classifier in plain steps
Imagine you run a small shop and want an automated tool that flags product photos as 'good' or 'blurry' so staff don’t list poor images. Here is a simple supervised-learning approach:
- Step A — Collect examples: Gather 300–1,000 product images and label each as 'good' or 'blurry'.
- Step B — Prepare data: Resize images consistently, normalize pixel values, and split into training (80%) and test (20%) sets.
- Step C — Choose a model: Start with a simple model (pre-trained convolutional neural network as a feature extractor + a small classifier). Using a pre-trained model reduces the need for a huge dataset.
- Step D — Train: Use the training set to adjust the classifier's parameters; monitor a validation set to avoid overfitting.
- Step E — Evaluate: Measure accuracy, precision, and recall on the test set. If results are poor, collect more examples or improve data quality.
- Step F — Deploy: Integrate the model into your image upload pipeline to flag low-quality photos for review.
This small project is low-risk, inexpensive to pilot, and provides clear value — a good first ML experiment for non-technical teams.
7. Why feature engineering and data matter more than you might expect
Model performance often depends heavily on the features you provide and the quality of labels. Noisy labels, biased samples, or irrelevant features can make even powerful models perform poorly. For many simple problems, carefully engineered features with a simple model can outperform a complex model trained on messy data.
8. Common pitfalls and how to avoid them
- Overfitting: Monitor validation performance and use simpler models or regularization when necessary.
- Data leakage: Ensure test data does not accidentally include information from the training set.
- Bias: Check whether your training data represents the real population; if not, the model may perform unfairly for certain groups.
- Ignoring monitoring: Models degrade over time if the input data distribution changes — set up simple monitoring metrics.
9. How to evaluate a model (basic metrics)
Choose metrics that match your business goal. For example:
- Accuracy: Percentage of correct predictions (works for balanced classes).
- Precision & Recall: Useful when classes are imbalanced — precision measures how many predicted positives are correct; recall measures how many actual positives were found.
- Confusion matrix: A helpful table to inspect types of errors.
10. Quick, safe roadmap for beginners to get hands-on
- Read a short conceptual primer (Google's Machine Learning Crash Course is a good starting point with interactive visualizations).
- Try a no-code tool or AutoML for small experiments (these platforms hide much of the complexity).
- Use pre-trained models or transfer learning for image and text tasks to reduce data needs.
- Start with a narrow, measurable problem (e.g., classify images, detect simple text patterns).
- Document data sources, label decisions, and evaluation plans to stay responsible and reproducible.
11. Tools and free resources to try (beginner-friendly)
- Google Machine Learning Crash Course: short lessons and interactive visualizations.
- Hugging Face & model hub: easy access to pre-trained text and image models.
- AutoML and no-code platforms: Many cloud vendors and independent tools let you upload data and build models without heavy coding.
12. When to call an expert
If your task affects safety, fairness, or regulatory compliance, or if you need scalable, highly reliable production systems, involve ML engineers and data specialists. For small, low-risk projects, a product manager or analyst can often run an initial pilot with oversight.
13. Short glossary
- Epoch: One complete pass through the training dataset during training.
- Learning rate: A training parameter that controls how quickly the model updates; set too high and training may be unstable.
- Transfer learning: Reusing a model pre-trained on a large dataset and fine-tuning it for a new task.
14. Final practical tips
- Start small and measure impact.
- Invest time in labeling and data quality — it pays off.
- Use pre-trained models when possible to save time and data.
- Monitor in production and be ready to retrain as data changes.
Further reading
Share
What's Your Reaction?
 Like
2100
Like
2100
 Dislike
32
Dislike
32
 Love
420
Love
420
 Funny
65
Funny
65
 Angry
6
Angry
6
 Sad
14
Sad
14
 Wow
310
Wow
310














I appreciate the practical advice and next steps. Great article.
This is exactly the kind of primer we need — thank you.
Thanks — clear steps and realistic expectations.
I'm sharing this with the education team. Very useful.
Excellent primer — concise and actionable.
Practical and accessible. I'll use this for an intro session.