How AI Personalization Works (Netflix, YouTube, Amazon)
A clear, beginner-friendly explanation of AI personalization used by Netflix, YouTube, and Amazon. Learn how recommendation systems work, key algorithms, data needs, evaluation, and practical steps for small teams to get started responsibly.


How AI Personalization Works (Netflix, YouTube, Amazon)
Introduction
If you''ve ever wondered why Netflix suggests the next show, YouTube queues a video you like, or Amazon shows product suggestions, you''ve experienced AI personalization. These systems analyze user behaviour and content features to suggest items each person is most likely to enjoy or buy. This article explains how those systems work in simple, practical terms and how beginners and small teams can approach personalization responsibly.
What is personalization?
Personalization means adjusting what a user sees based on their preferences, behaviour, or attributes. Instead of showing the same homepage to everyone, a personalized platform chooses content for each user to increase relevance and engagement.
Why personalization matters
- Improved experience: Users find relevant content faster.
- Higher engagement: Personalized suggestions keep people returning.
- Better conversion: For commerce platforms, personalization can increase sales and average order value.
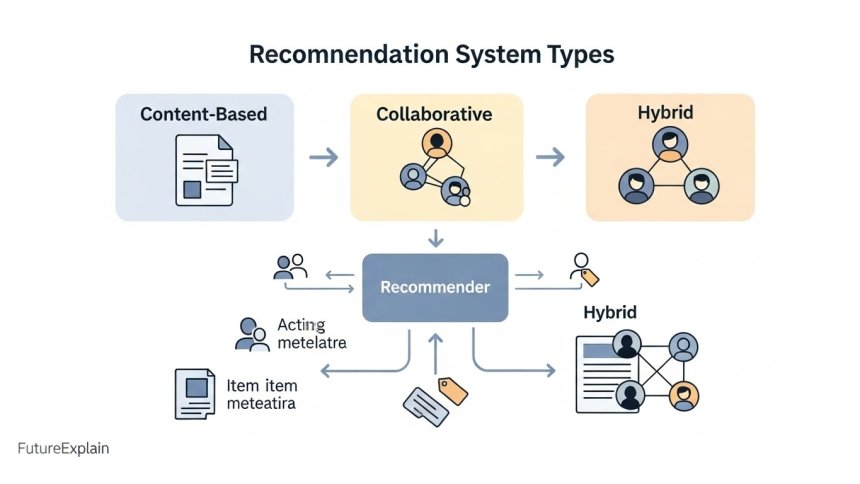
Three core approaches to recommendations
1. Content-based filtering
Content-based systems recommend items similar to what a user liked before. For example, if you watched sci-fi movies, the system looks at movie attributes (genre, actors, keywords) and recommends other sci-fi items.
- Data used: Metadata about items (genre, tags, descriptions, categories).
- Strengths: Works well when user history exists; interpretable recommendations.
- Limitations: Narrow suggestions (it keeps recommending similar items) and cold start for items lacking metadata.
2. Collaborative filtering
Collaborative filtering recommends items based on patterns of many users. The basic idea: “People similar to you liked X, therefore you might like X.” Two common collaborative approaches:
- User-based: Find users with similar behaviour and recommend what they liked.
- Item-based: Find items that are often liked together (e.g., users who liked movie A also liked movie B).
Strengths: Can suggest surprising but relevant items beyond obvious metadata. Limitations: Needs lots of interaction data; struggles with new items or new users.
3. Hybrid systems
Major platforms usually combine content-based and collaborative signals into hybrid recommenders. Hybrid systems leverage the strengths of both approaches to reduce weaknesses like cold start and overspecialisation.
Key algorithms (simple overview)
Matrix factorization
A common collaborative technique: it transforms the user-item interaction matrix into compact user and item vectors (embeddings). Similarity in this lower-dimensional space helps predict unseen preferences.
Nearest neighbors
Item-based nearest neighbors compute similarity between items using co-occurrence or feature similarity and recommend the most similar items.
Deep learning & embeddings
Modern systems use neural networks to learn embeddings for users and items from raw data (text, images, clicks). These embeddings capture subtle features and are powerful for large-scale personalization.
Sequence models
For platforms like YouTube, the order of interactions matters. Sequence models (e.g., RNNs or transformer-based architectures) learn patterns in user sessions to recommend the next best video.
Where platforms differ: Netflix, YouTube, Amazon (high-level)
Netflix
Netflix blends many signals: viewing history, show metadata, user ratings, session behavior, and more. It places large emphasis on experimentation — multiple algorithms run in parallel and the final ranking is an ensemble optimized by A/B testing for engagement metrics (watch time, retention).
YouTube
YouTube heavily emphasises session-aware and sequential recommendations. It uses both short-term signals (what you''re watching now) and long-term interests. Because the platform focuses on immediate next-action (next video), sequence models and watch-signal predictions are central.
Amazon
Amazon mixes collaborative signals with strong commerce features: purchase intent, cart additions, reviews, and product metadata. Conversion-centric metrics (click-to-purchase, add-to-cart) drive optimization. Recommendations often have commercial goals: increase basket size, cross-sell or up-sell.
Data used for personalization
Common data sources include:
- Interaction data: Views, clicks, watch time, purchases, likes, skips, search queries.
- Item metadata: Titles, descriptions, genres, product attributes, categories.
- User metadata: Device type, location (coarse), declared preferences, account age.
- Contextual signals: Time of day, session length, device, referral source.
Cold start problem: new users & new items
Two common challenges:
- New user: No history—use onboarding questions, immediate context (what they clicked in session), or demographic defaults.
- New item: No interactions—use content-based signals (metadata, descriptions, images) and early promotion to gather initial feedback.
Evaluation: how to know a recommender works?
Evaluation uses both offline metrics and online experiments:
- Offline metrics: Precision@k, Recall@k, Mean Average Precision (MAP), NDCG — measure how well the model predicts held-out interactions.
- Online metrics (A/B tests): Watch time, clickthrough rate (CTR), conversion, retention — these measure real user impact and are the gold standard.
Practical pilot for small teams
Small teams can run effective pilots without building large infrastructure. A basic path:
- Start with simple item-similarity: Use product/category metadata to create content-based suggestions.
- Use off-the-shelf libraries: Tools like implicit, surprise, or managed SaaS recommenders can provide collaborative baselines.
- Shadow mode testing: Generate recommendations but don''t show them live — compare predicted recommendations with actual outcomes.
- Run a small A/B test: Show recommendations to a portion of users and compare conversion or engagement against control.
For a guide on starting with no-code automation tools that can integrate into small pilots, see no-code-vs-ai-tools-what-should-beginners-choose and for tools recommended for beginners see top-ai-tools-for-beginners-to-boost-productivity.
Ranking & freshness: balancing relevance and novelty
Platforms must balance recommending popular items and showing fresh, novel choices. Too much popularity bias makes the feed stale; too much novelty risks irrelevant suggestions. Many systems include exploration strategies:
- Explore-exploit tradeoff: Occasionally show less-certain items to learn more about user preferences.
- Decay and recency: Give more weight to recent actions for session-sensitive recommendations.
Personalization at scale: engineering considerations
Real-time personalization involves engineering choices:
- Batch vs real-time: Some models are trained offline and predictions are served from precomputed tables; others require online scoring (e.g., next-video suggestions).
- Feature pipelines: Reliable pipelines to compute user/item features are critical.
- Latency: Predictions for interactive apps must be fast; teams often use approximate nearest neighbour (ANN) libraries for speed.
Responsible personalization: privacy & fairness
Practical rules:
- Minimize sensitive data: Don''t use highly sensitive attributes for personalization unless required and explicitly consented to.
- Transparency: Explain why a recommendation appears where possible (e.g., "Recommended because you watched X").
- Audit for bias: Check whether certain groups are systematically underserved and correct where needed.
Real examples: how a recommendation might be generated
Example 1 — A streaming service: A user watched two mystery dramas in the last week. The system:
- Identifies metadata tags for those shows (mystery, drama, lead actor).
- Looks up items frequently co-watched with those titles.
- Ranks candidate titles using a hybrid score that mixes collaborative similarity, content similarity, and a freshness boost.
- Returns the top 10 personalized choices.
Example 2 — An e-commerce site: A customer bought hiking boots. The system:
- Finds products purchased together with hiking boots (socks, gaiters, backpacks).
- Includes content-based suggestions (other hiking boot models with similar features).
- Personalizes by user segment (frequent buyer, price sensitivity).
Common pitfalls and how to avoid them
- Overfitting to short signals: Short-term patterns can mislead; balance long-term and short-term signals.
- Ignoring evaluation: Always measure against control groups.
- Privacy mistakes: Don''t expose or misuse private data in the name of personalization.
- Over-personalization: Avoid recommendations that feel intrusive or overly specific.
Design tips for product teams
- Start with a clear success metric (watch time, CTR, conversion).
- Use small experiments and iterate — many large systems evolved through thousands of A/B tests.
- Keep human oversight for sensitive cases or high-value recommendations.
- Document datasets, features, and business rules for reproducibility and audits.
Tools and libraries for teams that want to build
Beginners can experiment with:
- Open-source: surprise and implicit for collaborative filtering, faiss or annoy for nearest neighbour search.
- Cloud services: Managed recommenders from cloud providers or SaaS tools that provide endpoints and dashboards.
- No-code integrations: Tools that plug into existing analytics and allow simple personalization rules without heavy engineering.
Measuring user trust and acceptance
Beyond raw metrics, measure perceived relevance with user surveys and small focus groups. Monitor retention and whether personalization improves long-term satisfaction, not just short-term clicks.
Next steps and further reading
To understand the AI fundamentals behind these systems, read how-does-machine-learning-work-explained-simply. For ethical considerations and safe deployment, see how-to-use-ai-responsibly-beginner-safety-guide.
Conclusion
Personalization combines data, models, and product decisions to deliver relevant experiences. Platforms like Netflix, YouTube, and Amazon use hybrid approaches, rigorous experimentation, and careful measurement to balance relevance, novelty, and business outcomes. For beginners, the best approach is to start small, measure carefully, and keep users'' privacy and trust central to every decision.
For related practical posts on tools and smaller pilots, see best-automation-tools-for-non-technical-users and ai-for-small-businesses-practical-use-cases.
Share
What's Your Reaction?
 Like
1200
Like
1200
 Dislike
14
Dislike
14
 Love
210
Love
210
 Funny
32
Funny
32
 Angry
4
Angry
4
 Sad
1
Sad
1
 Wow
95
Wow
95
















Question: Any quick advice for reducing bias in recommendations?
Monitor performance across user segments, introduce fairness constraints in ranking, and surface diverse options intentionally to prevent echo chambers.
Praise: I like the practical product and engineering considerations — helpful for planning.
Question: How often should we rotate exploration to avoid stale recommendations?
A small rotation (5-10% exploration) is common; adjust based on catalogue size and user feedback. Monitor exploration performance to avoid negative impact.
Constructive feedback: Could use a small table comparing algorithms and when to pick them.
Question: Are embeddings the same as feature vectors, and how steep is the learning curve to use them?
Embeddings are a type of learned feature vector that captures semantics. Many libraries and tutorials exist — the learning curve is moderate but manageable with examples.
Question: Can personalization reduce organic discovery if over-optimized for short-term clicks?
Yes — over-optimization for short-term engagement can reduce diversity. Monitor discovery metrics and rotate exploration to keep the catalog visible.