Voice & Speaker Verification Basics for Security
This article provides a clear, beginner-friendly guide to voice and speaker verification technology. It explains the core concept of using your unique voiceprint as a biometric key for security. You'll learn how the technology has evolved from traditional statistical models to modern deep learning systems, and understand the key components that make it work. We also cover the practical challenges developers face, such as background noise and spoofing attacks, and explore real-world applications from phone unlocking to securing healthcare data. Finally, we look at the future trends and ethical considerations shaping this field.

Voice & Speaker Verification Basics for Security
In a world where passwords are frequently stolen and PINs can be guessed, security experts are turning to a key you always have with you and is incredibly difficult to forge: your voice. Voice and speaker verification technology, a branch of biometrics, uses the unique characteristics of your voice to confirm your identity. This technology powers features like phone unlocking, secure banking access, and voice-controlled personal assistants. For beginners and professionals alike, understanding how this AI-driven security works is becoming essential. This guide will break down the basics, explain the technology's evolution, and explore its practical applications and challenges.
What is Speaker Verification? Your Voice as a Digital Key
At its core, speaker verification is a biometric authentication process. Its goal is to answer a simple question: "Does this voice belong to the person it claims to belong to?" It's different from speech recognition, which asks "What is being said?" and from speaker identification, which asks "Who out of many possible speakers is talking?" Verification is a one-to-one matching problem, making it ideal for security checkpoints[citation:1].
Your voice is a powerful biometric because it combines physiological traits (the shape of your vocal cords, throat, and mouth) with behavioral patterns (your accent, speaking rate, and pronunciation habits). This blend creates a unique "voiceprint" that is very difficult for an impostor to perfectly replicate[citation:1][citation:2]. The system process typically involves two main phases: enrollment, where your voice is recorded to create and store a reference voiceprint, and verification, where a new voice sample is compared against the stored reference to accept or reject the claimed identity.
Visuals Produced by AI
The Evolution of the Technology: From Statistics to Deep Learning
The journey to today's sophisticated AI models has gone through several key stages, each building on the last to improve accuracy and robustness.
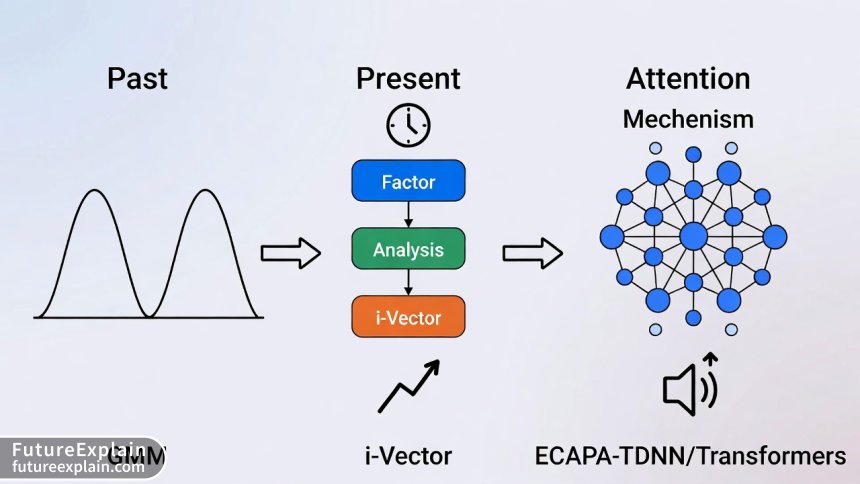
1. The Foundational Era: Statistical Models
Early systems relied on probabilistic and statistical methods. The dominant approach for years was the Gaussian Mixture Model - Universal Background Model (GMM-UBM). Here's a simplified breakdown:
- Universal Background Model (UBM): A general model trained on voices from many speakers to represent "average" speech characteristics.
- Gaussian Mixture Model (GMM): For a specific user, the UBM is adapted using their voice samples. This creates a unique model that captures how their voice differs from the average background.
2. The Modern Revolution: Deep Learning Takes Over
The explosion of deep learning has transformed the field. Modern systems use neural networks to directly learn the most discriminative features from audio data. Instead of engineers manually designing features, deep learning models discover them automatically through training on massive datasets like VoxCeleb2, which contains over a million utterances from thousands of speakers[citation:3].
Popular architectures include:
- Convolutional Neural Networks (CNNs) and Time Delay Neural Networks (TDNNs): Excellent at extracting local patterns from audio spectrograms, much like they do with images.
- The ECAPA-TDNN Model: A current state-of-the-art model. It builds on TDNNs but introduces advanced tricks like "channel attention" and "residual connections" to better focus on relevant voice characteristics and improve training efficiency. Real-world implementations report this architecture achieving high accuracy (e.g., 99.6%) and fast verification times (around 300 milliseconds)[citation:3].
- Transformer Networks: Famous for powering large language models like GPT, Transformers are now being applied to speaker verification. Their "self-attention" mechanism is particularly good at modeling long-range dependencies in speech, capturing how the sound at one moment relates to sounds that came much earlier[citation:1].
Visuals Produced by AI
Key Components of a Verification System
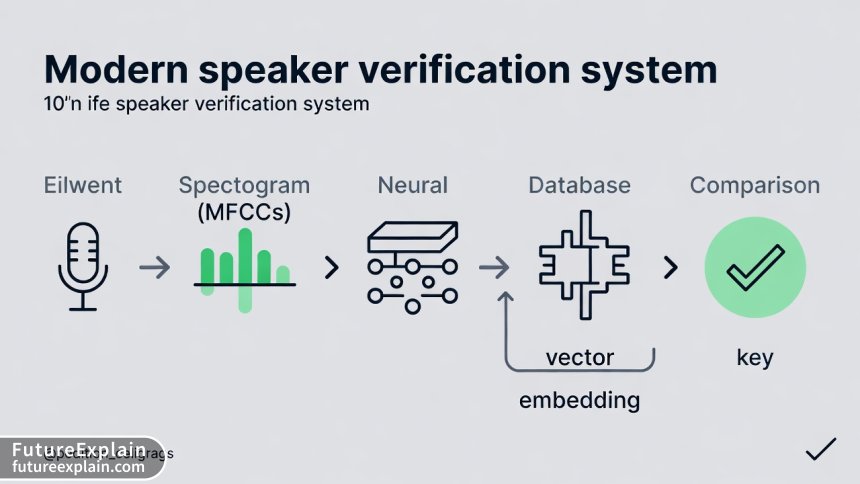
To understand how it all fits together, let's walk through the main components of a typical modern system:
- 1. Preprocessing & Feature Extraction: The raw audio waveform is first cleaned (noise reduction) and converted into a more informative representation. The most common features are Mel-Frequency Cepstral Coefficients (MFCCs), which roughly mimic human hearing and capture the timbral qualities of the voice. In deep learning systems, this step is often integrated into the first layers of the neural network[citation:1].
- 2. Speaker Modeling (Deep Feature Extraction): This is where the core AI model (like ECAPA-TDNN) works. It processes the features to produce the unique speaker embedding/vector.
- The new speaker embedding is compared to the stored reference embedding. A similarity score is calculated. This score is checked against a pre-set
- . Score above threshold = verified/accepted. Score below threshold = rejected[citation:1].
Practical Challenges and Real-World Considerations
Building a robust system isn't just about model accuracy on a clean dataset. Real-world deployment faces significant hurdles that developers must address[citation:1]:
• Noise and Audio Quality: Background chatter, wind, or poor microphone quality can distort the voice signal. Systems use noise suppression algorithms and are trained on noisy data to become more robust.
• Vocal Variability: Your own voice changes with a cold, with age, with emotional state, or even when you're tired. The system must be flexible enough to handle these natural variations without being so loose that it lets impostors in.
• Spoofing Attacks: This is the biggest security threat. Attackers may use high-quality recordings, voice synthesis, or even voice conversion technology to mimic a target's voice. A critical sub-field, anti-spoofing or presentation attack detection, uses separate AI models to detect these fakes by looking for artifacts not present in genuine live speech.
• Data Scarcity and Privacy: Training the best models requires vast amounts of voice data, which raises privacy concerns. Techniques like federated learning (training a model across decentralized devices without sharing raw data) and using privacy-preserving features are active research areas[citation:1][citation:2].
Where is This Technology Used? Real-World Applications
Speaker verification is moving out of the lab and into daily life. Key applications include:
• Consumer Device Security: Unlocking smartphones or personal computers.
• Financial Services and Tele-banking: Providing a secure layer for phone-based customer service, replacing or augmenting knowledge-based security questions.
• Healthcare: Securely accessing patient records over the phone or in telehealth applications. Research is also exploring integrating voice verification with blockchain technology to create an immutable, consent-based log of who accessed sensitive health data, enhancing both security and patient privacy[citation:2].
• Enterprise and Physical Access: Controlling access to secure buildings, server rooms, or confidential digital files.
• Forensics and Law Enforcement: Analyzing recorded evidence.
The Future and Responsible Development
The field continues to advance rapidly. Key trends for the near future include:
• On-Device AI: Running verification directly on your phone or smart speaker for greater speed and privacy, without sending voice data to the cloud. You can learn more about this trend in our article on On-Device LLMs.
• Multimodal Fusion: Combining voice with other biometrics (like face or behavior) for ultra-secure, multi-factor authentication. Our guide on Multimodal AI dives deeper into this concept.
• Few-Shot and Zero-Shot Learning: Developing models that can reliably verify a speaker with just a few seconds of enrollment audio, or even from a single example.
As with all powerful biometric technology, responsible development is paramount. Key ethical considerations include:
• Bias and Fairness: Systems must perform equally well across different accents, ages, genders, and ethnicities. This requires diverse, representative training data.
• Transparency and Consent: Users should know when their voiceprint is being captured, how it will be used, and for how long it will be stored. Clear policies are essential. For a broader look at these issues, read Ethical AI Explained: Why Fairness and Bias Matter.
• Security First: Continuous research into anti-spoofing and resilience against evolving attacks is a non-negotiable part of the development cycle.
Conclusion: A Powerful Tool in the Security Toolkit
Voice and speaker verification represents a significant leap forward in making authentication more secure and convenient. By understanding its journey from statistical models to deep learning powerhouses, and by acknowledging its real-world challenges, we can better appreciate both its potential and its limitations. It is not a silver bullet, but a highly effective component of a layered security strategy. As AI models become more efficient and privacy-conscious, your unique voice is poised to become an even more trusted key to your digital and physical world.
Further Reading
- AI Agents Explained: What They Are and Why They Matter - Learn how autonomous AI systems work.
- AI for Accessibility: Making Content Inclusive - Explore how AI, including speech technology, is breaking down barriers.
- Privacy-Preserving AI: Differential Privacy & Federated Learning - Dive deeper into the techniques that keep your data safe while training AI models.
Share
What's Your Reaction?
 Like
15210
Like
15210
 Dislike
85
Dislike
85
 Love
2200
Love
2200
 Funny
310
Funny
310
 Angry
120
Angry
120
 Sad
65
Sad
65
 Wow
460
Wow
460

















Solid, responsible overview. Glad it didn't fall into the hype trap and actually discussed challenges like spoofing and bias. More tech writing should be like this.
The comparison table of model evolution was excellent. It really highlights how fast this field is moving. Makes you wonder what the "Transformer" equivalent will be in 5 years.
The article mentions variability with a cold. I never thought about that! What happens if you enroll while healthy but try to verify while sick? Does it just fail?
From my experience, it might lower your similarity score but not necessarily cause a fail if the threshold has some tolerance. The best systems are trained on data that includes such variations to be robust. It's a good practice to re-enroll if you have a prolonged voice change!
This demystified so much! I'm sharing this with my non-technical team at the small business I run. We're considering voice auth for our internal systems.
As someone who works in audio production, I'm curious about the impact of high-quality studio microphones vs. smartphone mics on the system's accuracy during enrollment. Does a "better" recording make a more secure voiceprint?
Clear and well-structured. I would have liked a bit more detail on the "threshold" setting. How is that decision made? Is it a universal setting or does it adapt per user?
Excellent technical question, Adam. Threshold setting is critical. It's often tuned on a development dataset to balance False Acceptance and False Rejection rates, targeting a specific Equal Error Rate (EER). In some advanced systems, thresholds can be user-specific or even adaptive, changing based on the perceived risk of the transaction (e.g., accessing a public forum vs. a bank account).