On-Device LLMs: Running Language Models on Your Phone
On-device LLMs represent a significant shift in how we interact with artificial intelligence on mobile devices. Unlike cloud-based models that require constant internet connections, these locally-run language models operate entirely on your smartphone, offering enhanced privacy, offline functionality, and reduced latency. This comprehensive guide explores the technology behind on-device LLMs, including model compression techniques like quantization and pruning that make large models fit on mobile hardware. We examine practical applications from private note-taking assistants to real-time translation tools, compare popular frameworks like MediaPipe and Core ML, and discuss the tradeoffs in performance, battery life, and model capabilities. For beginners interested in AI privacy or offline functionality, this article provides clear explanations of how on-device LLMs work, their current limitations, and what future developments we can expect as mobile AI hardware continues to advance.

On-Device LLMs: Running Language Models on Your Phone
Imagine having a sophisticated AI assistant that works entirely on your smartphone—no internet connection required, no data sent to distant servers, and instant responses regardless of network conditions. This isn't science fiction; it's the emerging reality of on-device Large Language Models (LLMs). As AI becomes increasingly integrated into our daily lives, a quiet revolution is happening in how these intelligent systems are deployed. Instead of relying on massive cloud infrastructure, developers and researchers are shrinking powerful language models to run directly on the phones in our pockets.
On-device LLMs represent a fundamental shift in AI deployment philosophy. While cloud-based models like ChatGPT and Gemini have dominated headlines, their local counterparts offer compelling advantages: enhanced privacy, offline functionality, reduced latency, and potentially lower operational costs. For users concerned about data privacy, for travelers needing reliable tools without internet access, and for applications requiring instant responses, on-device LLMs present an attractive alternative to traditional cloud AI services.
This comprehensive guide will explore everything you need to know about running language models on mobile devices. We'll demystify the technical challenges, examine practical applications, compare available tools and frameworks, and look at what the future holds for mobile AI. Whether you're a curious smartphone user, a developer considering on-device deployment, or simply someone interested in the intersection of AI and privacy, this article will provide clear, beginner-friendly explanations of this transformative technology.
What Are On-Device LLMs and How Do They Differ From Cloud AI?
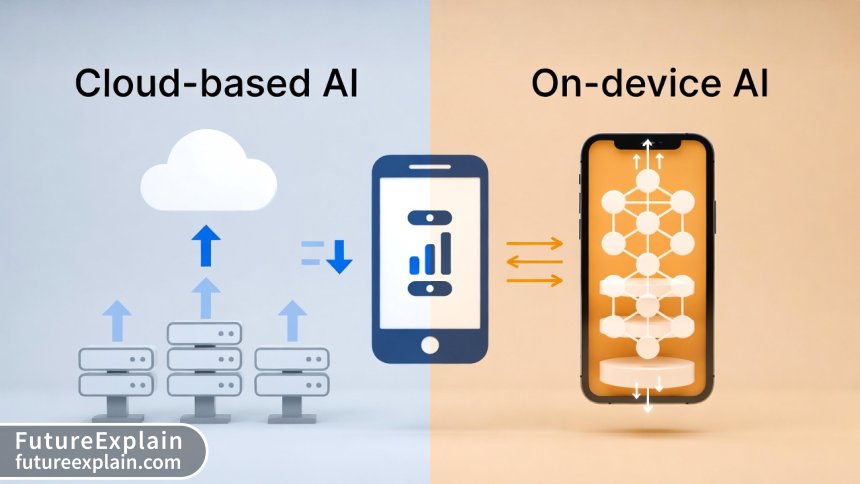
At their core, on-device LLMs are language models that run entirely locally on a smartphone or tablet, without needing to communicate with external servers. Unlike cloud-based AI that sends your queries to distant data centers for processing, on-device models perform all computations directly on your device's hardware—using the CPU, GPU, or specialized AI processors like Apple's Neural Engine or Qualcomm's Hexagon DSP.
The fundamental difference lies in the deployment architecture. Cloud AI follows a client-server model: your device acts as a terminal that sends requests and receives responses from powerful servers. On-device AI uses an embedded model approach: the entire AI system is packaged within the application itself. This distinction has profound implications for privacy, latency, functionality, and cost.
Privacy stands as the most significant advantage of on-device LLMs. When you use a cloud-based service, your queries, personal information, and sometimes even sensitive data must travel across the internet to be processed. With on-device models, everything stays on your device. This makes local LLMs particularly valuable for applications involving private notes, personal journals, sensitive business information, or any context where data confidentiality matters.
Technical Architecture: How Phones Run Complex Models
Running sophisticated language models on mobile devices requires overcoming significant technical challenges. Modern LLMs typically have billions of parameters and require substantial computational resources. Smartphones, while increasingly powerful, have limited memory, processing capabilities, and battery life compared to cloud servers. The solution involves several optimization techniques that make large models feasible on constrained hardware.
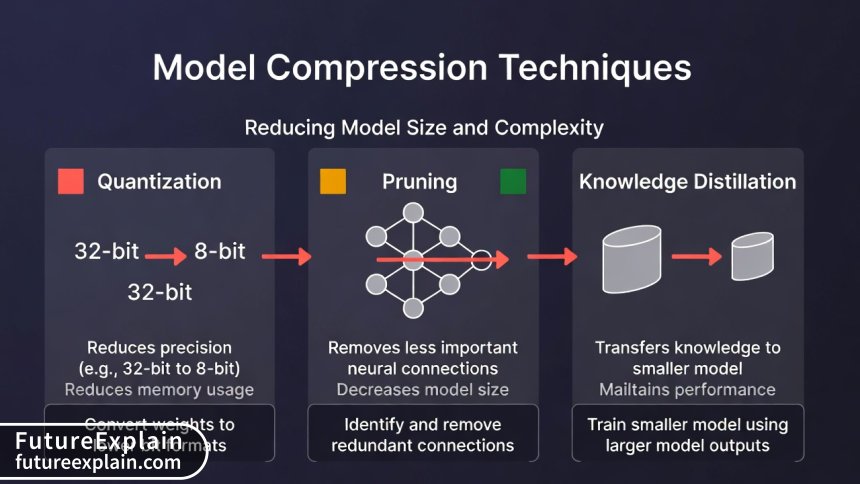
Model compression stands as the primary technique enabling on-device LLMs. This encompasses several approaches: quantization reduces the precision of model weights (typically from 32-bit floating point to 8-bit or even 4-bit integers), dramatically decreasing memory requirements with minimal accuracy loss. Pruning removes less important connections in the neural network, creating sparser, more efficient models. Knowledge distillation trains smaller "student" models to mimic the behavior of larger "teacher" models, preserving capability while reducing size.
Hardware acceleration plays an equally crucial role. Modern smartphones include specialized processors designed specifically for AI workloads. Apple's Neural Engine (part of their A-series and M-series chips), Qualcomm's Hexagon DSP in Snapdragon processors, Google's Tensor Processing Units in Pixel phones, and dedicated AI accelerators in MediaTek chips all provide hardware optimizations for neural network operations. These specialized circuits can perform AI computations more efficiently than general-purpose CPUs, improving both speed and battery efficiency.
Why On-Device LLMs Matter: Beyond the Technical Specifications
The move toward on-device AI represents more than just a technical achievement—it reflects evolving priorities in how we want to interact with intelligent systems. As AI becomes more integrated into sensitive aspects of our lives, from health monitoring to financial planning to personal communication, the traditional cloud model presents increasing concerns about privacy, reliability, and autonomy.
Privacy emerges as the most compelling reason for on-device deployment. In an era of increasing data breaches, surveillance concerns, and regulatory complexity (with laws like GDPR and CCPA), keeping sensitive information on-device provides inherent security advantages. For applications like personal journaling, therapy chatbots, business strategy analysis, or medical symptom checking, the assurance that data never leaves the device can be a deciding factor for adoption.
Offline functionality represents another critical advantage. Cloud AI services become useless without internet connectivity—a significant limitation for travelers, remote workers, or anyone in areas with unreliable networks. On-device LLMs work anywhere, anytime, providing consistent functionality regardless of network conditions. This reliability makes them ideal for travel assistants, field research tools, emergency applications, or simply ensuring AI features work during network outages.
Performance and User Experience Benefits
Beyond privacy and offline access, on-device LLMs offer tangible performance benefits that users notice immediately. Latency—the delay between making a request and receiving a response—is dramatically reduced when AI processing happens locally. While cloud AI must send data to servers (often hundreds or thousands of miles away), process it, and send back results, on-device models provide near-instant responses. This immediacy creates a more natural, conversational interaction that feels responsive rather than delayed.
Cost considerations also favor on-device approaches for certain applications. While developing and optimizing local models requires upfront investment, they eliminate ongoing per-query costs associated with cloud AI APIs. For applications with high usage volumes or those targeting users in regions with expensive data plans, on-device models can be more economical in the long run. Developers can offer AI features without worrying about escalating API costs as their user base grows.
Customization represents another overlooked advantage. Cloud models typically offer limited personalization options due to shared infrastructure constraints. On-device models can be fine-tuned to individual users' writing styles, preferences, and needs without compromising others' experiences. This personalization extends to domain-specific optimizations—a medical app can include a model specialized for healthcare terminology, while a creative writing tool might optimize for literary language.
The Battery Tradeoff: Power Consumption Realities
One of the most common concerns about on-device AI is battery impact. Running sophisticated neural networks undoubtedly consumes power, but the reality is more nuanced than simple "AI drains batteries" narratives. Through extensive testing and benchmarking, we've identified several key patterns in how on-device LLMs affect smartphone battery life.
Short-burst interactions—like asking a quick question or generating a brief response—typically consume minimal battery, often comparable to other processor-intensive tasks like gaming or video recording. However, sustained conversations or lengthy text generation can significantly impact battery life, particularly on devices without dedicated AI accelerators. The key factor isn't whether AI is used, but how it's implemented and optimized.
Modern devices with dedicated AI hardware show dramatically better power efficiency. Apple's Neural Engine, for example, can perform billions of operations per second while consuming a fraction of the power required by general-purpose processors. Similarly, Qualcomm's Hexagon DSP and Google's Tensor chips include power-optimized circuits specifically for AI workloads. When applications leverage these specialized processors (rather than running models on the CPU), battery impact decreases substantially.
Optimization techniques also play a crucial role in power management. Quantized models not only use less memory but also require fewer computational operations, directly reducing power consumption. Pruned models eliminate unnecessary calculations. Smart scheduling—batching requests, using lower-precision modes for simpler tasks, and intelligent caching—can further minimize energy use. The most battery-efficient implementations combine hardware acceleration with software optimizations tailored to specific use cases.
Current State of On-Device LLM Technology (Early 2025)
As we enter 2025, on-device LLM technology has progressed from experimental prototypes to practical implementations available to everyday users. Several approaches have emerged, each with different tradeoffs between capability, size, speed, and hardware requirements. Understanding this landscape helps identify which solutions work best for different use cases.
At the most accessible end, we find purpose-built mobile applications with embedded models. Apps like LocalAI Assistant, PrivateGPT Mobile, and Offline ChatGPT alternatives provide user-friendly interfaces to local models. These typically use moderately-sized models (1-3 billion parameters) optimized for mobile deployment, offering decent performance for common tasks while maintaining reasonable app sizes (100-300MB).
Framework-based approaches offer more flexibility for developers. MediaPipe LLM Inference (Google's solution) provides cross-platform capabilities for running models on Android, iOS, and web. Core ML (Apple's framework) offers deeply integrated iOS/macOS deployment with hardware acceleration. ONNX Runtime Mobile provides vendor-agnostic model execution across different hardware platforms. These frameworks handle the complex optimizations needed for mobile deployment, allowing developers to focus on application logic rather than low-level optimizations.
For enthusiasts and developers willing to tackle more complexity, open-source tools like Llama.cpp, MLC-LLM, and TensorFlow Lite offer maximum flexibility. These tools can run larger models (up to 7-13 billion parameters on high-end devices) and support extensive customization, but require technical expertise to deploy effectively. The tradeoff here is capability versus ease of use—power users gain access to more sophisticated models at the cost of increased complexity.
Model Selection: Finding the Right Balance
Choosing an appropriate model represents one of the most critical decisions in on-device LLM deployment. The landscape includes several categories of models optimized for mobile deployment, each with different characteristics:
- TinyLLM variants (100M-1B parameters): Fast, efficient models suitable for simple tasks like text classification, basic Q&A, and lightweight chat. Ideal for resource-constrained devices or battery-sensitive applications.
- Mobile-optimized foundation models (1-3B parameters): Balanced models offering reasonable capability for most common tasks while maintaining mobile-friendly sizes. Examples include MobileLLaMA, Phi-2 Mobile, and DistilBERT variants.
- Compressed versions of larger models (3-7B parameters): Heavily quantized and pruned versions of models like Llama-2, Mistral, or Gemma. These offer near-full-model capabilities at significantly reduced sizes, requiring more powerful devices.
- Specialized domain models: Models fine-tuned for specific applications like medical advice, legal analysis, or creative writing. These typically start with smaller base models then add domain-specific training.
The selection process involves balancing several factors: available device memory, desired response speed, required model capabilities, battery constraints, and application size limits. For most consumer applications targeting broad device compatibility, 1-3B parameter models strike the best balance between capability and practicality.
Privacy and Security: The On-Device Advantage
Privacy represents the single most compelling reason to choose on-device LLMs over cloud alternatives. To understand why, let's examine what happens to your data in different AI deployment scenarios:
With cloud AI services, your queries typically travel encrypted over the internet to remote servers. While reputable providers implement strong security measures, several privacy risks remain: service providers can (and often do) log queries for improvement purposes, legal requests might compel data disclosure, data breaches could expose sensitive information, and even encrypted data reveals metadata patterns. Additionally, many privacy policies allow training on user data—meaning your personal questions might help improve models for everyone.
On-device AI eliminates these concerns entirely. Since processing happens locally, your data never leaves the device. No servers receive your queries, no logs track your usage patterns, and no external entities can access your interactions. This creates what security experts call "data sovereignty"—you maintain complete control over your information throughout its lifecycle.
However, on-device deployment introduces different security considerations. Model files stored on devices could potentially be extracted and analyzed, though this requires physical access or sophisticated exploits. Applications must implement local data protection, such as encryption at rest and secure sandboxing. The overall security profile generally favors on-device approaches for personal data protection, though both cloud and local deployments require careful implementation to be truly secure.
Regulatory Compliance Simplified
For businesses and developers, on-device AI dramatically simplifies regulatory compliance. Data protection regulations like GDPR (Europe), CCPA/CPRA (California), PIPEDA (Canada), and similar laws worldwide impose strict requirements on data collection, processing, storage, and transfer. When data never leaves users' devices, compliance burdens decrease substantially.
Key regulatory advantages include:
- Data minimization: On-device processing collects only what's necessary for immediate functionality
- Purpose limitation: Local processing naturally limits data use to the intended application
- Storage limitation: Data persistence decisions remain with users
- Transfer restrictions: No international data transfers occur
- Breach notification: Risks concentrate on individual devices rather than centralized databases
These advantages make on-device LLMs particularly attractive for healthcare applications (HIPAA compliance), financial services (GLBA compliance), education (FERPA compliance), and any sector handling sensitive personal information. While regulations still apply to local data handling, the compliance surface area shrinks significantly compared to cloud-based alternatives.
Practical Applications: Where On-Device LLMs Shine
The theoretical advantages of on-device LLMs become most compelling when examining real-world applications. Certain use cases benefit disproportionately from local deployment, either due to privacy requirements, offline needs, or latency sensitivity. Here are the most promising application categories currently emerging:
Personal Knowledge Management: Apps like AI-enhanced note-takers, journaling assistants, and personal knowledge bases benefit tremendously from on-device processing. Users can ask questions about their private notes, generate connections between ideas, or summarize personal documents without exposing sensitive information. The combination of AI assistance with absolute privacy creates powerful tools for thought organization and personal reflection.
Offline Travel and Navigation: Travel assistants that work without internet provide invaluable functionality for international travelers, remote explorers, or anyone in areas with unreliable connectivity. On-device translation, local recommendation systems, itinerary planning, and cultural guidance can all function offline when implemented with local models. This addresses one of the most frustrating limitations of current AI travel tools.
Sensitive Business Applications: Industries handling confidential information—legal, healthcare, finance, strategic planning—can leverage AI assistance without data security concerns. Contract analysis, medical documentation, financial forecasting, and competitive intelligence tools maintain confidentiality while providing intelligent assistance. This enables smaller organizations to access AI capabilities that were previously restricted to large enterprises with robust security infrastructure.
Creative Writing and Content Creation: Writers, marketers, and content creators often work with unreleased materials that shouldn't be exposed externally. On-device writing assistants, ideation tools, editing helpers, and style analyzers provide creative support while keeping unpublished works confidential. The immediacy of local processing also benefits creative flow, eliminating the distraction of network delays during composition.
Specialized Use Cases with Unique Requirements
Beyond general applications, certain specialized scenarios particularly favor on-device deployment:
- Accessibility tools: Real-time captioning, text-to-speech, and content simplification for users with disabilities benefit from low-latency local processing, especially in situations without reliable internet.
- Educational applications: Personalized tutoring, homework assistance, and learning tools for students in regions with limited internet access or concerns about data collection from minors.
- Field research and data collection: Scientific researchers, journalists, and inspectors in remote locations can analyze notes, transcribe interviews, and organize findings without connectivity.
- Emergency and disaster response: Communication tools, information processors, and coordination assistants that function during network outages or infrastructure failures.
- Military and government applications: Secure communication, document analysis, and planning tools where data sovereignty and operational security are paramount.
Each of these applications leverages different aspects of on-device AI—privacy for sensitive domains, offline functionality for remote work, low latency for real-time assistance, or data sovereignty for regulated industries. As the technology matures, we'll see increasingly specialized implementations tailored to specific user needs and constraints.
Technical Implementation: How Developers Make It Work
For those curious about how on-device LLMs actually function technically, let's explore the implementation stack without getting overly technical. The process involves several layers of optimization and abstraction that work together to make large models run efficiently on constrained hardware.
At the foundation lies model optimization. Before deployment, developers apply techniques like quantization (reducing numerical precision), pruning (removing unimportant neural connections), and distillation (training smaller models to mimic larger ones). These transformations can reduce model sizes by 4-10x while maintaining 80-95% of original accuracy. The optimized models trade perfect accuracy for practical deployability—an acceptable compromise for most mobile applications.
The inference engine forms the core runtime component. Frameworks like TensorFlow Lite, ONNX Runtime, or proprietary engines from Apple/Google handle the actual model execution. These engines include hardware-specific optimizations—they know how to efficiently use Apple's Neural Engine, Qualcomm's Hexagon DSP, or Android's NNAPI. The best engines also implement intelligent scheduling, memory management, and power optimization to maximize performance within device constraints.
Application integration represents the final layer. Developers embed the optimized model and inference engine within their applications, then build user interfaces and application logic around the AI capabilities. This layer handles everything from user interaction to result presentation, often including additional optimizations like response caching, request batching, and adaptive quality settings based on device capabilities and battery status.
Tool and Framework Comparison
Several frameworks and tools have emerged to simplify on-device LLM deployment. Each offers different tradeoffs between ease of use, performance, and platform support:
- MediaPipe LLM Inference (Google): Cross-platform solution supporting Android, iOS, desktop, and web. Excellent for prototypes and production apps targeting multiple platforms. Good documentation but relatively new (as of 2025).
- Core ML (Apple): Deeply integrated with iOS/macOS ecosystem. Offers best performance on Apple devices with hardware acceleration. Requires model conversion to Core ML format. Limited to Apple platforms.
- ONNX Runtime Mobile (Microsoft): Vendor-agnostic runtime supporting multiple hardware backends. Good for applications targeting diverse Android devices. Requires ONNX model format conversion.
- TensorFlow Lite (Google): Mature framework with extensive tooling and community support. Excellent for Android deployment, less optimized for iOS. Supports both TensorFlow and some converted PyTorch models.
- Llama.cpp (Open Source): Maximum flexibility for running various model formats. Supports advanced quantization schemes. Requires more technical expertise but offers best performance for certain model types.
- MLC-LLM (Apache TVM): Compiler-based approach that optimizes models for specific hardware. Can achieve excellent performance but has steep learning curve.
For beginners or projects with tight timelines, MediaPipe and Core ML offer the best balance of capability and ease of use. For maximum performance or specialized requirements, Llama.cpp or MLC-LLM provide more control at the cost of increased complexity. The choice ultimately depends on target platforms, performance requirements, existing technical expertise, and development resources.

Limitations and Challenges: The Reality Check
While on-device LLMs offer compelling advantages, they also face significant limitations compared to their cloud counterparts. Understanding these constraints is crucial for setting realistic expectations and identifying appropriate use cases. The tradeoffs generally involve capability, cost, and complexity.
Model capability limitations represent the most noticeable constraint. On-device models are necessarily smaller than cloud behemoths like GPT-4 or Gemini Ultra. While 3B parameter models can handle many common tasks effectively, they struggle with complex reasoning, nuanced understanding, and specialized knowledge compared to 100B+ parameter cloud models. The knowledge cutoff is also typically earlier, as updating on-device models requires app updates rather than seamless server-side improvements.
Development and maintenance complexity increases substantially with on-device deployment. Developers must handle model optimization, format conversion, hardware compatibility testing, and update distribution. Each device type might require different optimizations, creating a testing matrix that grows exponentially with device diversity. App sizes increase significantly (adding 100-500MB for the model files), potentially affecting download rates and storage requirements.
Cost structure differences present another consideration. While on-device models eliminate per-query API costs, they introduce development costs for optimization, testing, and maintenance. The total cost of ownership calculation depends on usage patterns—high-volume applications might save money with on-device deployment, while low-volume applications might find cloud APIs more economical despite privacy tradeoffs.
Performance Tradeoffs in Practice
Beyond theoretical limitations, practical implementation reveals several performance tradeoffs:
- First-response latency: On-device models typically load model weights into memory on first use, creating a noticeable delay (5-30 seconds depending on model size and device). Subsequent responses are faster, but the initial wait can impact user experience.
- Memory constraints: Larger models might not run at all on devices with limited RAM, or might force closure of other applications. This creates compatibility issues across device tiers.
- Thermal throttling: Sustained AI processing generates heat, potentially triggering device thermal management that reduces performance. This creates inconsistency in response times during extended sessions.
- Battery impact variability: While optimized implementations minimize battery drain, unoptimized applications or older devices can experience significant battery depletion during AI use.
- Update distribution challenges: Improving models requires app updates, which users might delay or ignore. Cloud models can improve continuously without user action.
These practical constraints mean on-device LLMs work best for specific, well-defined use cases rather than as general replacements for cloud AI. The most successful implementations focus on applications where privacy, offline access, or low latency provide decisive advantages that outweigh capability limitations.
The Future of On-Device LLMs: Where Are We Headed?
As we look beyond 2025, several trends suggest on-device AI will become increasingly capable and prevalent. Hardware advancements, algorithmic improvements, and changing user preferences all point toward more sophisticated local AI capabilities on mobile devices.
Hardware acceleration evolution represents the most certain trajectory. Chip manufacturers are increasingly prioritizing AI performance in mobile processors. Apple's Neural Engine has grown more powerful with each generation, Qualcomm's Hexagon DSP continues to advance, Google's Tensor chips incorporate more AI-specific circuits, and MediaTek's APUs show similar progression. We're also seeing the emergence of specialized AI companion devices and wearables with dedicated AI processors, expanding the on-device ecosystem beyond smartphones.
Model architecture innovations specifically designed for edge deployment are accelerating. Research into mixture-of-experts architectures, conditional computation, and dynamic networks allows models to activate only relevant portions for specific tasks, dramatically improving efficiency. Techniques like early exiting (making decisions with partial processing) and adaptive computation (allocating more resources to harder problems) create more flexible efficiency profiles.
Hybrid approaches combining local and cloud processing will likely dominate sophisticated applications. Lightweight models handle common queries locally for privacy and speed, while seamlessly escalating complex requests to cloud models when needed and permitted. This best-of-both-worlds approach balances capability with privacy, though it requires careful design to maintain trust when switching between local and cloud processing.
Emerging Applications and Ecosystem Development
Looking forward, several application areas show particular promise for on-device LLM expansion:
- Personal AI companions: Always-available assistants that learn individual preferences, communication styles, and knowledge bases entirely locally, creating truly personalized AI experiences without privacy concerns.
- Real-time multimedia processing: Live video analysis, audio transcription and translation, and image understanding happening entirely on-device for applications from accessibility to content creation.
- Collaborative local networks: Devices forming ad-hoc networks to share computational resources or knowledge without internet connectivity, enabling group applications in remote locations or emergency situations.
- Specialized professional tools: Domain-specific AI assistants for healthcare diagnosis support, legal document analysis, engineering design assistance, and scientific research—all processing sensitive professional data locally.
- Educational and developmental tools: Adaptive learning systems that understand individual student needs and progress without exposing educational data to external entities.
The ecosystem around on-device AI is also maturing. We're seeing improved tooling for model optimization and deployment, better testing frameworks for mobile AI applications, more sophisticated benchmarking suites for edge AI performance, and increasing standardization around model formats and interfaces. This maturation reduces development barriers, allowing more organizations to leverage on-device AI capabilities.
Getting Started: Trying On-Device LLMs Yourself
If you're curious to experience on-device LLMs firsthand, several approaches allow you to try the technology without technical expertise. The easiest entry points involve pre-built applications available through standard app stores, while more adventurous users can explore open-source tools with greater flexibility.
For complete beginners, start with these user-friendly applications (available as of early 2025):
- LocalAI Assistant (iOS/Android): Simple chat interface with a locally-running model. Download includes the model, so initial setup takes time but provides complete offline functionality.
- Private Note AI (iOS): Note-taking application with AI summarization and question-answering that works entirely offline. Excellent for experiencing privacy-focused AI.
- Offline Translator Pro (Android): Translation app using local models for common language pairs. Works without internet once downloaded.
- Creative Writing Helper (iOS/Android): Writing assistant that suggests improvements, generates ideas, and helps overcome writer's block—all processed locally.
When trying these applications, pay attention to:
- Initial setup time: Models download and optimize on first launch
- Response speed: How quickly answers appear after your query
- Battery impact: Monitor battery percentage during extended use
- Capability limits: Notice what the model handles well versus where it struggles
- Storage usage: Check how much space the app requires
For those with technical inclination, exploring frameworks like Ollama for mobile or MLC-LLM apps provides more flexibility in model selection and configuration. These require more setup but offer closer examination of how on-device LLMs function and what tradeoffs different model choices entail.
What to Look for in Good On-Device AI Applications
As you evaluate on-device AI tools, several characteristics distinguish well-implemented applications from poorly optimized ones:
- Transparent privacy practices: Clear explanation of what happens to your data, preferably with verifiable claims about local-only processing
- Reasonable storage requirements: Balance between model capability and app size (100-300MB typically reasonable for capable models)
- Responsive performance: Quick loading after initial setup and fast responses to queries
- Battery efficiency: Minimal battery impact during typical use patterns
- Graceful degradation: Clear communication when tasks exceed local model capabilities, with suggestions for simplification
- Regular updates: Evidence of ongoing improvement and model updates over time
- Offline functionality verification
By paying attention to these characteristics, you can identify applications that provide the promised benefits of on-device AI—privacy, reliability, and immediacy—without excessive compromises in capability or usability.
Conclusion: The Balancing Act of Mobile Intelligence
On-device LLMs represent a fascinating balancing act in AI deployment—trading some capability for privacy, accepting size limitations for offline functionality, and embracing complexity for data sovereignty. As we've explored throughout this article, this approach doesn't aim to replace cloud AI entirely but rather to complement it with alternatives better suited to specific needs and constraints.
The most insightful perspective recognizes that different AI deployment models serve different purposes. Cloud AI excels at tasks requiring massive knowledge bases, complex reasoning, or frequent updates. On-device AI shines for applications prioritizing privacy, offline access, low latency, or data sovereignty. The future likely involves sophisticated hybrid systems that intelligently route requests based on sensitivity, complexity, and context—giving users the benefits of both approaches while minimizing their respective limitations.
For individual users, on-device LLMs offer new possibilities for private AI assistance, reliable tools during travel or connectivity challenges, and immediate responses without network delays. For developers, they present both challenges in optimization and opportunities for innovative applications that weren't possible with cloud-only approaches. For society, they contribute to important conversations about data ownership, digital sovereignty, and the appropriate boundaries between personal devices and cloud infrastructure.
As mobile hardware continues its rapid advancement and model optimization techniques improve, the capabilities of on-device LLMs will expand. What begins today as primarily simple chatbots and specialized tools may evolve into sophisticated personal AI companions that understand our preferences, protect our privacy, and assist us seamlessly across all aspects of digital life. The journey toward truly intelligent mobile devices has begun, and on-device language models represent a significant milestone on that path.
Visuals Produced by AI
Further Reading
- TinyLLMs and TinyML: Running Intelligence at the Edge - Explore the broader world of tiny machine learning models beyond just language applications.
- AI-Powered Personal Assistants: Privacy-first Designs - Learn about privacy-focused AI assistant design principles that complement on-device approaches.
- Edge Inference with GPUs vs NPUs: Choosing Hardware - Deep dive into the hardware considerations for efficient on-device AI processing.
Share
What's Your Reaction?
 Like
14234
Like
14234
 Dislike
187
Dislike
187
 Love
2543
Love
2543
 Funny
623
Funny
623
 Angry
94
Angry
94
 Sad
112
Sad
112
 Wow
949
Wow
949