Continuous Learning in Production: Patterns and Pitfalls
Continuous learning enables machine learning models to adapt to changing data patterns in production, but implementing it successfully requires careful architecture and operational discipline. This comprehensive guide explores five practical patterns for continuous learning, from simple scheduled retraining to sophisticated online learning systems. You'll learn about the critical pitfalls that cause continuous learning initiatives to fail, including data pipeline issues, monitoring gaps, and feedback loop problems. We cover implementation considerations for different model types, cost-benefit analysis frameworks, and regulatory compliance requirements. The article includes practical checklists for implementation and real-world case studies showing both successes and failures.
Why Continuous Learning Matters in Production ML
Machine learning models deployed to production don't remain static—they face changing data distributions, evolving user behavior, and shifting business contexts. A model that performs excellently at deployment can degrade significantly over time, a phenomenon known as model decay or concept drift. Continuous learning addresses this challenge by enabling models to adapt to new patterns while maintaining production reliability.
Unlike traditional batch retraining approaches that happen on fixed schedules, continuous learning systems incorporate new data and update models in a more fluid, automated manner. However, implementing continuous learning successfully requires navigating complex technical and operational challenges. This guide explores practical patterns for implementation and the common pitfalls that derail these initiatives.
Understanding Model Decay and Concept Drift
Before diving into implementation patterns, it's crucial to understand why models decay in production. Several phenomena contribute to declining performance:
- Covariate Shift: The distribution of input features changes while the relationship between features and target remains constant
- Concept Drift: The statistical relationship between inputs and outputs changes over time
- Label Drift: The distribution of target variables changes
- Data Quality Degradation: Issues with missing values, format changes, or schema evolution
Research from Google's ML team shows that models can lose up to 50% of their predictive accuracy within 6-12 months without retraining, depending on the domain. Financial fraud detection models may decay faster due to adaptive fraudsters, while recommendation systems face gradual drift as user preferences evolve.
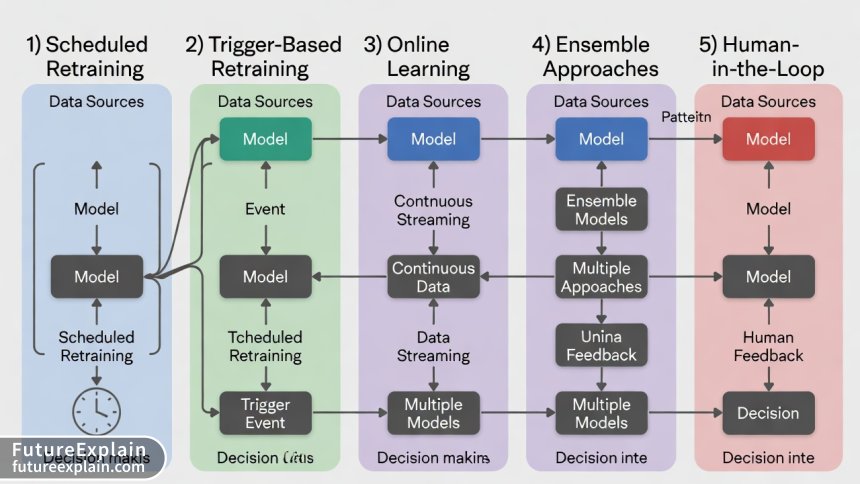
Five Practical Patterns for Continuous Learning
Based on industry implementations across companies like Netflix, Uber, and Airbnb, we can categorize continuous learning approaches into five main patterns.
Pattern 1: Scheduled Retraining with Canary Deployment
The most common approach involves retraining models on a fixed schedule (daily, weekly, monthly) and deploying updates through canary or blue-green deployments. This pattern works well when:
- Data patterns change predictably
- Retraining costs are manageable
- You have established CI/CD pipelines for models
Implementation Example: A retail recommendation system retrains nightly using the previous day's user interactions, with new models gradually rolled out to 1%, 5%, then 100% of traffic over 24 hours.
Pattern 2: Performance-Triggered Retraining
Instead of fixed schedules, this pattern monitors model performance metrics and triggers retraining when degradation exceeds thresholds. Key considerations include:
- Choosing appropriate monitoring metrics (accuracy, precision, recall, business KPIs)
- Setting statistically significant thresholds to avoid unnecessary retraining
- Managing retraining during performance dips
Critical Implementation Detail: Use moving averages or statistical process control charts to distinguish real degradation from normal variance.
Pattern 3: Online/Incremental Learning
Some algorithms support online learning, where models update with each new data point. This pattern offers real-time adaptation but comes with limitations:
- Only certain algorithms support it (linear models, some neural networks)
- Risk of catastrophic forgetting without careful implementation
- Increased complexity in versioning and rollback
Online learning works particularly well for streaming data applications like anomaly detection in network security or real-time bidding systems.
Pattern 4: Ensemble Approaches with Model Weighting
This pattern maintains multiple models and dynamically weights their predictions based on recent performance. Benefits include:
- Gradual adaptation without abrupt model changes
- Natural A/B testing framework
- Easy rollback by adjusting weights
Technical Consideration: Ensemble methods increase inference costs and complexity but provide robustness against sudden distribution shifts.
Pattern 5: Human-in-the-Loop Active Learning
For high-stakes applications or limited labeled data, human feedback guides retraining. The system identifies uncertain predictions or novel patterns for human review, then incorporates corrected labels into future training.
This pattern balances automation with human oversight, crucial for medical diagnosis, content moderation, or financial applications where errors have significant consequences.
Architectural Components for Continuous Learning
Successful continuous learning systems require several key architectural components working together:
Data Pipeline Infrastructure
A robust data pipeline must handle both training data collection and feature serving with consistency. The training-serving skew problem—differences between features during training versus inference—becomes especially critical in continuous learning systems.
Industry best practice involves implementing a feature store that ensures consistent feature calculation across training and serving environments. Uber's Michelangelo platform popularized this approach, demonstrating how feature stores reduce training-serving skew from common problem to manageable edge case.
Model Monitoring and Alerting
Continuous learning requires more sophisticated monitoring than standard production models. Beyond basic performance metrics, you need:
- Data distribution monitoring (evolving feature distributions)
- Concept drift detection (statistical tests like Kolmogorov-Smirnov, PSI)
- Business metric correlation (connecting model performance to business outcomes)
- Infrastructure monitoring (GPU utilization, latency, cost per prediction)
Tools like Evidently AI, Amazon SageMaker Model Monitor, and custom statistical process control implementations help track these dimensions.
Model Registry and Versioning
Continuous learning generates many model versions. A model registry must track:
- Training data provenance and versioning
- Hyperparameters and training configuration
- Performance metrics across validation sets
- Business impact measurements
- Rollback capabilities to previous versions
MLflow, Kubeflow, and custom solutions provide this functionality, but the key is integrating model versioning with your CI/CD pipeline.

Critical Pitfalls and Failure Modes
Based on analysis of failed continuous learning implementations across multiple organizations, several patterns of failure emerge consistently.
Pitfall 1: Feedback Loop Problems
The most dangerous failure mode involves reinforcement feedback loops where model predictions influence future training data in problematic ways. Examples include:
- Recommendation systems that reinforce popularity biases
- Fraud detection models that only see caught fraud cases
- Content moderation systems that only review flagged content
These create representation bias in training data, causing models to perform poorly on edge cases or novel patterns.
Pitfall 2: Monitoring Blind Spots
Many teams monitor aggregate metrics but miss subgroup performance degradation. A model might maintain overall accuracy while failing catastrophically for specific user segments, geographic regions, or product categories.
Solution: Implement slice-based monitoring that tracks performance across important data segments. This becomes especially critical for fairness and bias considerations in regulated industries.
Pitfall 3: Data Pipeline Inconsistencies
Continuous learning amplifies any inconsistencies in data pipelines. Common issues include:
- Feature calculation differences between training and serving
- Missing data handling inconsistencies
- Schema evolution without proper versioning
- Label quality issues in feedback data
A major e-commerce company discovered their continuous learning system was degrading because their feature pipeline for training used batch processing with 24-hour latency, while serving used real-time features. The 1-2% difference in feature values created compounding errors over multiple retraining cycles, eventually reducing model accuracy by 15% before detection.
Pitfall 4: Cost Escalation Without Value
Continuous learning systems can become expensive to operate, especially with complex neural networks or large-scale data. Common cost issues:
- Frequent retraining of large models without performance improvement
- Expensive monitoring and data collection overhead
- Storage costs for multiple model versions and training data snapshots
Establish clear cost-benefit frameworks that tie retraining frequency and model complexity to measurable business impact.
Pitfall 5: Regulatory and Compliance Violations
Continuous learning in regulated industries (finance, healthcare, insurance) creates unique compliance challenges:
- Model explainability requirements for constantly changing models
- Audit trail requirements for model decisions
- Data privacy regulations affecting feedback collection
- Fairness testing for evolving models
GDPR's "right to explanation" and financial industry model risk management requirements demand special consideration in continuous learning implementations.
Implementation Checklist for Continuous Learning
Based on successful implementations, here's a practical checklist for deploying continuous learning:
Phase 1: Foundation (Weeks 1-2)
- ✓ Implement robust model performance monitoring with automated alerts
- ✓ Establish data quality monitoring for training and inference data
- ✓ Set up model registry with versioning and rollback capability
- ✓ Create baseline model performance metrics
Phase 2: Automation (Weeks 3-6)
- ✓ Automate model retraining pipeline with CI/CD integration
- ✓ Implement canary deployment for model updates
- ✓ Set up A/B testing framework for model comparisons
- ✓ Create automated data validation tests
Phase 3: Optimization (Weeks 7-12)
- ✓ Implement concept drift detection
- ✓ Set up cost monitoring and optimization triggers
- ✓ Create slice-based performance monitoring
- ✓ Establish feedback loop analysis procedures
Case Studies: Successes and Failures
Success: Netflix Recommendation System
Netflix implements a sophisticated continuous learning system that combines multiple patterns:
- Scheduled retraining of deep learning models daily
- Online learning for real-time ranking adjustments
- Extensive A/B testing with canary deployments
- Comprehensive monitoring across user segments
Key success factors include their investment in feature store infrastructure, statistical significance testing for performance changes, and business metric alignment (focusing on viewing time rather than just click-through rates).
Failure: Financial Trading Algorithm
A quantitative trading firm implemented continuous learning for their market prediction models but encountered catastrophic failure:
- Feedback loop created self-reinforcing patterns that didn't generalize
- Monitoring missed regime changes in market behavior
- Costs escalated without corresponding performance improvements
- Lack of rollback capability during rapid market changes
The firm lost significant capital before identifying the issues, highlighting the importance of safeguards in high-stakes applications.
Special Considerations for LLMs and Foundation Models
Continuous learning for large language models presents unique challenges:
Catastrophic Forgetting
LLMs tend to "forget" previously learned information when fine-tuned on new data. Techniques to mitigate this include:
- Elastic Weight Consolidation (EWC) to protect important weights
- Experience Replay with stored examples from previous distributions
- Modular approaches that add adapter layers rather than full retraining
Cost and Scale Considerations
Full retraining of billion-parameter models remains prohibitively expensive for most organizations. Practical approaches include:
- Parameter-Efficient Fine-Tuning (PEFT) methods like LoRA
- Selective retraining of specific model components
- Ensemble approaches combining foundation models with smaller adaptive models
Safety and Alignment Maintenance
Continuous learning must preserve safety guardrails and alignment. Best practices include:
- Regular safety testing against known failure cases
- Human review of model outputs before incorporating into training
- Maintaining separate "constitutional" training data for alignment preservation
Cost-Benefit Analysis Framework
Not all applications benefit from continuous learning. Use this framework to evaluate whether continuous learning makes sense for your use case:
High-Value Applications (Prioritize Continuous Learning)
- Fraud detection with evolving attack patterns
- Recommendation systems with changing user preferences
- Medical diagnosis with evolving treatment protocols
- Autonomous systems in changing environments
Lower-Value Applications (Consider Simpler Approaches)
- Static classification problems with stable distributions
- Applications with limited feedback data availability
- Regulatory environments requiring extensive model validation
- Cost-sensitive applications with limited compute budget
The decision should balance the rate of concept drift against implementation complexity and operational costs.
Future Trends in Continuous Learning
Several emerging trends will shape continuous learning implementations:
Automated Machine Learning (AutoML) for Continuous Learning
Next-generation AutoML systems will not just select initial models but manage the entire continuous learning lifecycle—monitoring performance, selecting retraining strategies, and optimizing model architectures for evolving data.
Federated Continuous Learning
For privacy-sensitive applications, federated learning enables continuous improvement without centralizing raw data. Devices or edge locations train locally, sharing only model updates.
Causal Continuous Learning
Incorporating causal reasoning helps models distinguish correlation from causation, reducing spurious pattern learning and improving generalization to new environments.
Explainable Continuous Learning
New techniques make continuously evolving models more interpretable, crucial for regulated applications. Methods like concept activation vectors and influence functions help trace model behavior changes to specific data influences.
Getting Started: Practical First Steps
If you're new to continuous learning, start with these manageable steps:
- Implement basic monitoring: Start with performance degradation alerts before automating retraining
- Manual retraining cycle: Establish a manual retraining process before automating it
- Simple A/B testing: Test new models against production with careful measurement
- Gradual automation: Automate components incrementally, maintaining human oversight
- Regular reviews: Schedule periodic reviews of the entire continuous learning system
Remember that continuous learning is as much an organizational capability as a technical one. Success requires collaboration between data scientists, ML engineers, DevOps teams, and business stakeholders.
Conclusion
Continuous learning represents the next evolution in production machine learning, moving from static deployed models to adaptive systems that maintain performance in changing environments. While the technical challenges are significant, the patterns and best practices outlined here provide a roadmap for successful implementation.
The key insight is that continuous learning isn't a binary choice but a spectrum of approaches. Start simple, monitor rigorously, and incrementally add sophistication as you build organizational capability and technical infrastructure. By understanding both the patterns for success and the common pitfalls, you can implement continuous learning that delivers sustained value without introducing unacceptable risks.
Visuals Produced by AI
Further Reading
Share
What's Your Reaction?
 Like
1247
Like
1247
 Dislike
23
Dislike
23
 Love
312
Love
312
 Funny
45
Funny
45
 Angry
8
Angry
8
 Sad
12
Sad
12
 Wow
189
Wow
189

















This article came at the perfect time. We're designing our MLOps platform and the architectural components section saved us from major oversight. Feature store implementation is now priority #1.
What about edge cases where continuous learning makes performance worse? We had a model that started overfitting to recent noise after implementing trigger-based retraining.
Marcus, that's a common issue. Consider: 1) Adding regularization that increases with model update frequency, 2) Implementing "learning rate scheduling" for continuous updates—smaller updates over time, 3) Maintaining an ensemble with older models as a stability anchor. Some teams use a minimum performance delta threshold before allowing updates to prevent noise-fitting.
The implementation checklist is gold! We're in Phase 2 and this validates our approach. The canary deployment for models has been trickier than expected—model warm-up time affects performance metrics.
How do you handle validation datasets for continuous learning? If you're constantly updating models, what constitutes a stable test set?
Kenji, we maintain multiple validation sets: 1) Time-based holdout (most recent N days), 2) Stratified random sample, 3) Known difficult cases. We track performance across all three. When concept drift occurs, the time-based set shows degradation first.
Great article! I'd add that organizational change management is as important as technical implementation. Getting data scientists to think in terms of continuous systems rather than one-off models requires mindset shift.
The data pipeline inconsistency pitfall cost us 3 months of work. Our training features were computed with 24-hour latency while serving used real-time values. The drift accumulated slowly so we didn't notice until business metrics dropped.