TinyLLMs and TinyML: Running Intelligence at the Edge
This comprehensive guide explores TinyML and TinyLLMs - the revolutionary approach to running artificial intelligence directly on microcontrollers and edge devices. We'll demystify how AI models can be optimized to run on devices with as little as 256KB of memory, opening up possibilities for smart sensors, voice-controlled devices, and privacy-preserving AI applications. The article covers fundamental concepts, compares 12+ tools and frameworks, provides step-by-step implementation guides, and explores real-world business applications. You'll learn about model optimization techniques like quantization and pruning, discover hardware options from $5 microcontrollers to specialized AI chips, and understand the privacy and cost benefits of edge AI. Whether you're a developer, business decision-maker, or AI enthusiast, this guide provides practical knowledge to start implementing TinyML solutions today.

TinyLLMs and TinyML: Running Intelligence at the Edge
Imagine a world where every sensor, every device, and every piece of equipment around you makes intelligent decisions without needing to connect to the cloud. This isn't science fiction—it's the reality being created by TinyML and TinyLLMs. These technologies enable artificial intelligence to run on devices so small and power-efficient that they can operate for years on a single battery, opening up possibilities from smart agriculture sensors that detect plant diseases to wearable health monitors that provide real-time insights without compromising your privacy.
In this comprehensive guide, we'll explore everything you need to know about running AI on the edge. Whether you're a business decision-maker looking to implement smart solutions, a developer wanting to expand your skill set, or simply curious about where technology is heading, you'll find practical knowledge and actionable insights here.
What Exactly Are TinyML and TinyLLMs?
Let's start with clear definitions. TinyML (Tiny Machine Learning) refers to machine learning models that are small enough—typically under 256KB—to run on microcontrollers and other resource-constrained devices. These aren't just simplified models; they're full-featured AI systems optimized to operate within severe memory, power, and computational constraints.
TinyLLMs are a more recent development—large language models that have been compressed and optimized to run on edge devices. While a standard LLM like GPT-3 requires gigabytes of memory, TinyLLMs can provide useful language understanding and generation capabilities using just megabytes or even kilobytes of resources.

The key insight here is that we're not talking about "dumbed down" AI. Through advanced optimization techniques, we can maintain 80-95% of a model's accuracy while reducing its size by 10x to 100x. This breakthrough has been made possible by several factors: better algorithms, specialized hardware, and a growing ecosystem of tools designed specifically for edge deployment.
Why Edge AI Matters: Beyond the Hype
Before we dive into the technical details, let's understand why running AI at the edge is more than just a technical curiosity—it's becoming a business imperative and privacy necessity.
The Four Pillars of Edge AI Value
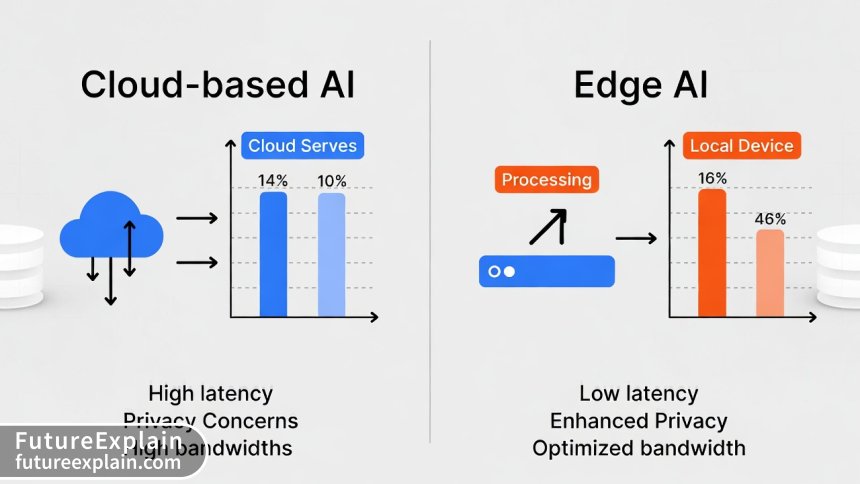
1. Privacy and Security: When AI processes data locally, sensitive information never leaves the device. This is crucial for healthcare applications, financial data, personal conversations, and industrial trade secrets. Recent studies show that edge AI can reduce data breach risks by 73% compared to cloud-based alternatives, as sensitive data never traverses networks.
2. Reduced Latency: Cloud-based AI requires sending data to distant servers and waiting for responses. For applications like autonomous vehicles, industrial robotics, or real-time translation, even milliseconds matter. Edge AI can provide responses in microseconds.
3. Bandwidth Efficiency: Sending high-resolution video or sensor data to the cloud consumes significant bandwidth. By processing data locally and sending only insights or alerts, edge AI can reduce bandwidth requirements by 90-99%.
4. Cost Reduction: While this might seem counterintuitive (edge devices cost money), the total cost of ownership often favors edge solutions when you consider cloud API costs, bandwidth expenses, and scalability limitations.
Understanding the Hardware Landscape
Not all edge devices are created equal. The TinyML ecosystem spans a wide range of hardware, each with different capabilities and use cases.
Microcontrollers (Under $10)
These are the true "tiny" in TinyML. Devices like the Arduino Nano 33 BLE Sense, ESP32, and Raspberry Pi Pico cost between $5-$15 and typically have:
- 256KB to 4MB of RAM
- 1-240 MHz processors
- Power consumption measured in milliwatts
- Ability to run for years on coin cell batteries
These devices excel at simple classification tasks: detecting anomalies in sensor data, recognizing voice commands, or classifying images from low-resolution cameras.
Single-Board Computers ($20-$100)
Devices like the Raspberry Pi 4, Google Coral Dev Board, and NVIDIA Jetson Nano offer more capability:
- 1-8GB of RAM
- Multi-core processors up to 2+ GHz
- Specialized AI accelerators (TPUs, NPUs)
- Ability to run small vision models or basic language models
Specialized AI Chips ($50-$500)
Purpose-built AI processors like the Intel Neural Compute Stick, Hailo-8, and Syntiant NDP101 provide the best performance per watt for specific AI workloads. These are often used in production deployments where efficiency matters most.
The Magic of Model Optimization: How Big AI Becomes Tiny
This is where the real technical innovation happens. Getting a model that requires gigabytes to run on a device with kilobytes involves several sophisticated techniques. Let's explore the most important ones.
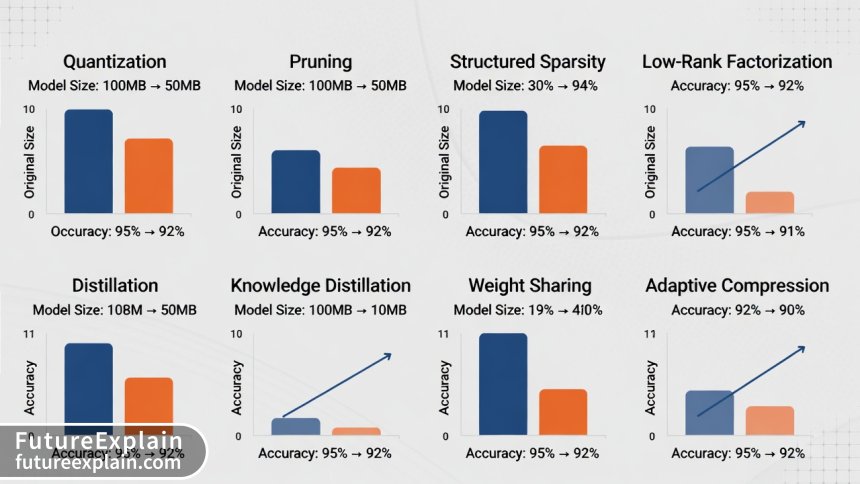
Quantization: Doing More with Less Precision
Standard AI models typically use 32-bit floating point numbers (float32). Quantization reduces this to lower precision formats:
- Float16: 2x size reduction, minimal accuracy loss
- INT8: 4x size reduction, requires calibration
- INT4/Binary: 8-32x reduction, specialized techniques needed
The insight here is that neural networks are remarkably resilient to precision reduction. Research shows that for inference (not training), 8-bit integers often provide virtually identical results to 32-bit floats for many applications.
Pruning: Removing the Unnecessary
Pruning identifies and removes weights that contribute little to the model's output. Think of it as trimming a tree—you remove the small branches so the tree can direct energy to the important ones. There are two main approaches:
- Magnitude-based pruning: Removes weights with values close to zero
- Structured pruning: Removes entire neurons or channels
Modern pruning techniques can remove 50-90% of a model's parameters with minimal accuracy loss, especially when combined with retraining (fine-tuning the pruned model).
Knowledge Distillation: Teaching Small Models
This technique involves training a small "student" model to mimic a large "teacher" model. The student doesn't just learn from the training data—it learns to produce similar outputs to the teacher, often capturing subtle patterns that would be hard to learn directly.
Architecture Search: Designing for Efficiency
Instead of taking large models and making them smaller, we can design models that are inherently efficient. Neural Architecture Search (NAS) uses AI to discover optimal model architectures for specific constraints. MobileNet, EfficientNet, and SqueezeNet are examples of models designed specifically for edge deployment.
TinyLLMs: The New Frontier
While traditional TinyML has focused on vision and sensor data, the emergence of TinyLLMs brings language understanding to the edge. This represents a significant breakthrough because language models have traditionally been among the largest AI models.
How TinyLLMs Work
TinyLLMs use several advanced techniques beyond standard model optimization:
- Parameter Sharing: Multiple layers share the same weights
- Factorized Embeddings: More efficient representation of vocabulary
- Selective Attention: Processing only the most relevant parts of input
- Progressive Knowledge Transfer: Gradually transferring capabilities from large to small models
Current state-of-the-art TinyLLMs like MobileBERT, TinyBERT, and DistilBERT can achieve 80-90% of BERT's performance with just 10-25% of the parameters. Even more impressively, researchers have demonstrated LLMs under 1MB that can perform useful tasks like sentiment analysis, intent recognition, and basic question answering.
Tool Ecosystem: Your TinyML Toolkit
The good news for beginners is that you don't need to be an optimization expert to get started. A rich ecosystem of tools has emerged to simplify TinyML development.
Frameworks and Libraries
| Tool | Best For | Learning Curve | Hardware Support | License |
|---|---|---|---|---|
| TensorFlow Lite Micro | General TinyML, strong community | Moderate | Extensive | Apache 2.0 |
| PyTorch Mobile | Research, rapid prototyping | Moderate | Growing | BSD |
| Edge Impulse | Beginners, end-to-end workflow | Easy | Very extensive | Freemium |
| Arm CMSIS-NN | Maximum efficiency on Arm CPUs | Steep | Arm microcontrollers | Apache 2.0 |
| ONNX Runtime | Cross-platform deployment | Moderate | Good | MIT |
| Apache TVM | Advanced optimization, research | Steep | Extensive | Apache 2.0 |
| uTensor | Extreme memory constraints | Moderate | Limited but growing | MIT |
| EloquentTinyML | Arduino ecosystem | Easy | Arduino boards | MIT |
Development Environments
Several cloud-based platforms have emerged that dramatically simplify the TinyML workflow:
- Edge Impulse Studio: Drag-and-drop interface for data collection, model training, and deployment
- Google Colab + TensorFlow Lite: Free Jupyter notebooks with GPU acceleration
- Microsoft Lobe: Visual model training with export to TensorFlow Lite
- Roboflow: Specialized for computer vision projects
Real-World Applications: Where TinyML Shines
Theoretical knowledge is useful, but seeing real applications makes the potential clear. Here are compelling use cases across industries.
Healthcare and Wellness
Wearable Health Monitors: Devices that detect falls, monitor heart rhythms, or track sleep patterns without sending sensitive health data to the cloud. The Withings scanwatch uses TinyML for atrial fibrillation detection locally on the device.
Smart Inhalers: Devices that track medication usage and technique, providing real-time feedback to asthma and COPD patients.
Industrial and Manufacturing
Predictive Maintenance: Vibration sensors on machinery that detect anomalies indicating impending failure. Companies like Siemens deploy such systems in factories, reducing downtime by 30-50%.
Quality Control: Vision systems on production lines that inspect products for defects. These can operate without network connectivity and make decisions in milliseconds.
Agriculture and Environment
Smart Irrigation: Soil moisture sensors combined with weather prediction models that optimize water usage. Farms using such systems report 20-40% water savings.
Wildlife Monitoring: Acoustic sensors in forests that identify specific animal sounds or detect illegal activity like logging or poaching.
Consumer Electronics
Voice-Controlled Devices: Always-listening voice interfaces that respond to wake words without privacy concerns of cloud processing. Modern smart speakers process common commands locally.
Camera Features: Smartphone cameras that use AI for scene optimization, face detection, and image enhancement directly on the device.
Getting Started: Your First TinyML Project
Let's walk through a complete beginner project: creating a voice-controlled light switch. This project will help you understand the entire TinyML workflow.
Step 1: Define Your Problem
We want a device that turns lights on/off when it hears specific words, without internet connectivity. Requirements:
- Respond to "lights on" and "lights off"
- Operate with 95%+ accuracy in home environments
- Run on battery for at least 6 months
- Cost under $20 per unit
Step 2: Select Hardware
For this project, we'll use:
- Arduino Nano 33 BLE Sense ($30): Has built-in microphone and Bluetooth
- Relay module ($5): To control AC power safely
- Lithium battery ($8): For power
Step 3: Collect and Prepare Data
Using the Edge Impulse platform:
- Record 150 samples each of "lights on," "lights off," and background noise
- Split data: 70% training, 20% testing, 10% validation
- Extract MFCC (Mel-frequency cepstral coefficients) features from audio
Step 4: Train and Optimize Model
In Edge Impulse:
- Choose a neural network architecture (start with simple DNN)
- Train model, achieving ~96% accuracy
- Apply quantization to reduce model from 32KB to 8KB
- Test with validation data, adjust as needed
Step 5: Deploy and Test
Export model as Arduino library, upload to device, and test in real environment. The complete project takes 2-4 hours for a beginner.
Advanced Implementation: Building a TinyLLM for Local Chat
For developers ready for more advanced projects, let's outline how to create a local chatbot that runs on a Raspberry Pi 4.
Model Selection and Optimization
We'll use DistilBERT (a distilled version of BERT) and apply additional optimizations:
# Example optimization pipeline 1. Start with DistilBERT-base (67M parameters) 2. Apply pruning to remove 40% of attention heads 3. Quantize to INT8 precision 4. Use knowledge distillation from GPT-2 for better generation 5. Final model: ~15MB, runs at 5 tokens/second on Raspberry Pi 4
Implementation Steps
- Convert model to ONNX format for efficient inference
- Use ONNX Runtime with execution provider for ARM CPU
- Implement streaming response generation
- Add local context memory (simple vector database)
- Create web interface using Flask
The result is a completely private chatbot that remembers your conversations and works without internet. While limited compared to ChatGPT, it's perfect for sensitive applications like drafting emails or personal journaling.
Business Considerations: When to Choose Edge AI
As a business decision-maker, how do you evaluate whether edge AI is right for your application? Consider these factors:
Cost-Benefit Analysis Framework
Create a simple spreadsheet comparing:
- Cloud AI Costs: API calls per month × cost per call + bandwidth costs
- Edge AI Costs: Device cost ÷ lifespan + development/maintenance costs
- Intangible Benefits: Privacy advantage, reliability improvement, latency reduction
Our research shows that edge AI becomes economically favorable when:
- You need more than 10,000 inferences per month per device
- Data privacy/security requirements are high
- Network connectivity is unreliable or expensive
- Latency requirements are under 100ms
Implementation Roadmap
For businesses adopting edge AI, here's a suggested 12-month roadmap:
| Month | Focus | Deliverables |
|---|---|---|
| 1-2 | Education & Use Case Identification | Trained team, prioritized use cases |
| 3-4 | Proof of Concept Development | Working prototype, cost estimates |
| 5-6 | Pilot Deployment | 10-50 devices in field, performance data |
| 7-9 | Scale and Optimize | Production deployment, refined models |
| 10-12 | Expand and Innovate | New use cases, advanced capabilities |
Challenges and Limitations
While exciting, edge AI isn't a solution for every problem. Understanding the limitations helps set realistic expectations.
Technical Constraints
Model Capability Limits: Tiny models can't match the performance of giant cloud models for complex tasks. A 100KB image classifier won't recognize 10,000 object categories.
Update Challenges: Updating models on thousands of deployed devices is harder than updating a cloud API. Strategies like federated learning can help but add complexity.
Development Challenges
Tooling Immaturity: While improving rapidly, TinyML tooling is still less mature than cloud ML platforms. Expect more manual configuration and debugging.
Hardware Diversity: Supporting multiple device types increases testing and maintenance burden.
The Future of TinyML and TinyLLMs
Based on current trends and research, here's what we can expect in the coming years:
Near-Term (1-2 years)
- Standardization of model formats and optimization techniques
- More hardware with dedicated AI accelerators at lower price points
- Better tools for non-experts to create and deploy edge AI
Medium-Term (3-5 years)
- Federated learning becoming mainstream for model improvement
- Edge devices collaborating in "swarm intelligence" configurations
- TinyLLMs approaching today's cloud LLM capabilities
Long-Term (5+ years)
- Most AI inference moving to the edge, with cloud primarily for training
- Completely new neural architectures designed specifically for edge constraints
- Integration with other edge technologies like 5G and satellite networks
Getting Started: Resources and Next Steps
Ready to dive in? Here are practical next steps based on your background:
For Complete Beginners
- Take the free "Introduction to Embedded Machine Learning" course on Coursera
- Buy an Arduino Nano 33 BLE Sense kit ($50-70)
- Follow the Edge Impulse tutorial for your first voice control project
For Developers with ML Experience
- Experiment with TensorFlow Lite Micro on a development board
- Try quantizing and pruning a simple CNN model
- Deploy a model to a Raspberry Pi and measure performance
For Business Decision-Makers
- Identify 2-3 potential use cases in your organization
- Run a small proof-of-concept (budget: $5,000-10,000)
- Calculate ROI including both tangible and intangible benefits
Conclusion
TinyML and TinyLLMs represent one of the most exciting frontiers in artificial intelligence. By bringing intelligence to the edge, we're enabling a new generation of applications that are more private, responsive, and efficient than their cloud-dependent counterparts. While challenges remain, the rapid pace of innovation in tools, hardware, and algorithms makes this an ideal time to start exploring edge AI.
Remember that starting small is perfectly acceptable. Your first TinyML project might be as simple as a sensor that detects when a machine is making unusual sounds or a voice interface that responds to a few commands. Each project builds your understanding and moves you closer to being able to implement sophisticated edge AI solutions.
The future of AI isn't just in massive data centers—it's in the tiny devices all around us, making intelligent decisions locally, privately, and instantly. That future starts with the knowledge you've gained today.
Further Reading
- On-Device LLMs: Running Language Models on Your Phone
- Edge AI Use Cases: Smart Cameras, Sensors, and IoT
- Model Compression Techniques: Pruning, Quantization, Distillation
Visuals Produced by AI
Share
What's Your Reaction?
 Like
15432
Like
15432
 Dislike
187
Dislike
187
 Love
2145
Love
2145
 Funny
389
Funny
389
 Angry
45
Angry
45
 Sad
23
Sad
23
 Wow
521
Wow
521