Serverless Inference: Pros, Cons, and How to Start
Serverless inference represents a paradigm shift in how AI models are deployed and served. This comprehensive guide explains what serverless inference is, how it differs from traditional model hosting, and why it's becoming increasingly popular for AI applications. We cover the key advantages including automatic scaling, reduced operational overhead, and pay-per-use pricing models, as well as important limitations like cold starts and vendor lock-in. The article provides practical step-by-step guidance for getting started with serverless inference on major platforms, compares different service offerings, and includes real-world use cases. Whether you're a developer looking to deploy your first model or a business seeking cost-effective AI solutions, this guide offers actionable insights and best practices for leveraging serverless architecture for AI inference.

Serverless Inference: Pros, Cons, and How to Start
In the rapidly evolving world of artificial intelligence, how we deploy and serve models has become just as important as how we build them. Traditional approaches to model hosting often involve managing servers, worrying about scalability, and dealing with significant upfront costs. Enter serverless inference – a paradigm shift that promises to simplify AI deployment while making it more cost-effective and scalable. This comprehensive guide will walk you through everything you need to know about serverless inference, from fundamental concepts to practical implementation.
What is Serverless Inference?
At its core, serverless inference is a cloud computing execution model where the cloud provider dynamically manages the allocation and provisioning of servers to run AI model inference. The term "serverless" is somewhat misleading – there are still servers involved, but developers don't need to think about them. You simply upload your trained model, and the platform handles everything else: scaling, maintenance, patching, and availability.
Think of serverless inference as the equivalent of renting a car versus owning one. With traditional model hosting (owning), you're responsible for maintenance, insurance, parking, and what happens when it breaks down. With serverless (renting), you pay for what you use, and someone else handles all the operational overhead. This approach has gained tremendous popularity as AI applications have moved from experimental projects to production systems requiring reliable, scalable, and cost-effective serving.
How Serverless Inference Differs from Traditional Hosting
To understand why serverless inference matters, we need to contrast it with traditional model deployment approaches. Traditional hosting typically involves:
- Provisioning dedicated servers or containers: You rent or own physical or virtual machines
- Managing infrastructure: Operating system updates, security patches, network configuration
- Handling scaling manually: Predicting traffic patterns and provisioning capacity accordingly
- Paying for idle time: Servers cost money whether they're processing requests or sitting idle
- Maintaining redundancy: Setting up failover systems and backup infrastructure
Serverless inference flips this model on its head. Instead of paying for and managing servers, you deploy your model to a serverless platform that:
- Automatically scales: From zero to thousands of requests per second without manual intervention
- Charges only for actual usage: You pay per inference request or compute time, not for idle capacity
- Handles all infrastructure management: The provider manages servers, security, updates, and monitoring
- Provides built-in high availability: Automatic failover and redundancy across multiple zones
- Offers simplified deployment: Often just requiring a model file and a configuration
The Architecture Behind Serverless Inference
Understanding serverless inference requires looking under the hood at how these systems work. While implementations vary across providers, most follow a similar architectural pattern:
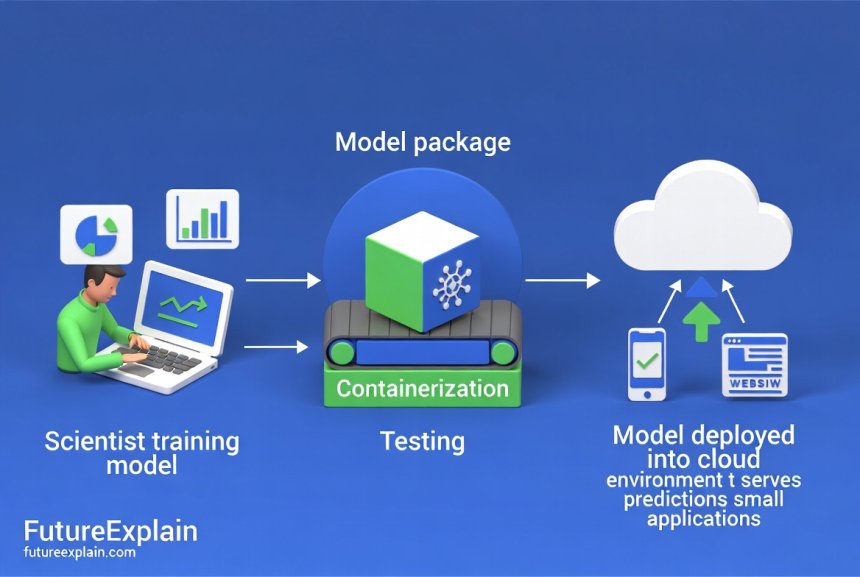
1. Model Packaging and Registration
Your trained model (TensorFlow, PyTorch, ONNX, etc.) is packaged with any necessary dependencies and registered with the serverless platform. This often involves containerizing the model or using platform-specific packaging formats.
2. Endpoint Creation
The platform creates an API endpoint that can receive inference requests. This endpoint is automatically load-balanced and may be distributed across multiple geographic regions.
3. Cold Start Initialization
When the first request arrives (or after a period of inactivity), the platform initializes a runtime environment, loads your model into memory, and prepares it for inference. This "cold start" phase is a critical consideration in serverless systems.
4. Request Processing
Incoming requests are routed to available instances, processed through your model, and responses are returned. The platform automatically scales the number of instances based on traffic.
5. Auto-scaling and Management
The platform continuously monitors load and adjusts capacity. It also handles health checks, logging, metrics collection, and failure recovery.
Key Advantages of Serverless Inference
The growing popularity of serverless inference isn't accidental. It offers several compelling advantages that address common pain points in AI deployment:
1. Cost Efficiency and Pay-Per-Use Pricing
Traditional hosting requires paying for servers 24/7, regardless of whether they're processing requests. With serverless inference, you only pay when your model is actually doing work. This can lead to dramatic cost savings, especially for applications with:
- Variable or unpredictable traffic patterns
- Periodic or batch processing needs
- Low-to-medium volume usage
- Development and testing environments
2. Automatic and Instant Scalability
Serverless platforms handle scaling automatically and near-instantly. If your application goes viral or experiences sudden traffic spikes, the platform spins up additional instances without any manual intervention. This eliminates the need for capacity planning and prevents service disruption during traffic surges.
3. Reduced Operational Overhead
By abstracting away infrastructure management, serverless inference significantly reduces the operational burden on development teams. No more:
- Server maintenance and patching
- Capacity planning and scaling operations
- Infrastructure monitoring and alert setup
- Disaster recovery planning and testing
4. Faster Time to Market
With simplified deployment processes and no infrastructure to configure, teams can move from model development to production deployment in hours rather than days or weeks. This accelerated timeline is particularly valuable in competitive markets where being first matters.
5. Built-in High Availability and Fault Tolerance
Major serverless platforms are designed with redundancy and fault tolerance as core principles. They typically distribute your model across multiple availability zones, automatically handle instance failures, and provide service level agreements (SLAs) for uptime.
6. Environmental Efficiency
By maximizing resource utilization and minimizing idle compute, serverless inference can be more environmentally friendly than traditional hosting. Cloud providers can pack multiple serverless functions onto physical servers, achieving higher density and better energy efficiency.
Important Limitations and Considerations
While serverless inference offers significant benefits, it's not a universal solution. Understanding its limitations is crucial for making informed architectural decisions:
1. Cold Start Latency
The most significant limitation of serverless inference is "cold starts" – the delay when initializing a new instance to handle requests after a period of inactivity. This latency can range from a few hundred milliseconds to several seconds, depending on:
- Model size and complexity
- Runtime initialization requirements
- Platform implementation
- Concurrency settings
2. Limited Control and Customization
Serverless platforms abstract away the underlying infrastructure, which means you have limited control over:
- Specific hardware configurations (GPU type, memory allocation)
- Low-level optimization settings
- Networking configuration
- Runtime environment customization
3. Vendor Lock-in Concerns
Each cloud provider has its own serverless implementation with proprietary APIs, tools, and workflows. Migrating from one provider to another can be challenging and time-consuming, creating potential vendor lock-in.
4. Cost Predictability Challenges
While pay-per-use can save money, it can also make costs less predictable. Unexpected traffic spikes can lead to unexpectedly high bills, making budgeting and forecasting more difficult.
5. Execution Time and Resource Limits
Serverless platforms typically impose limits on:
- Maximum execution time per request (usually 15-30 minutes)
- Memory allocation (typically up to 10GB)
- Package/deployment size
- Concurrent executions
6. Debugging and Monitoring Complexity
Troubleshooting issues in serverless environments can be more challenging than in traditional setups. Distributed tracing, logging aggregation, and performance monitoring require specialized tools and approaches.
When to Choose Serverless Inference
Serverless inference shines in specific scenarios. Consider it when:
- Traffic is unpredictable or spiky: Automatic scaling handles variations seamlessly
- You have infrequent or periodic workloads: Pay-per-use pricing is cost-effective
- Development velocity is a priority: Reduced operational overhead speeds up iteration
- You lack dedicated DevOps resources: Infrastructure management is handled by the platform
- Cost optimization is critical: Especially for low-to-medium volume applications
- You need rapid prototyping or proof-of-concept development: Fast deployment cycles
When to Avoid Serverless Inference
Traditional or container-based approaches may be better when:
- Ultra-low latency is non-negotiable: Cold starts may violate SLA requirements
- You have consistently high, predictable traffic: Reserved instances may be more cost-effective
- Specialized hardware is required: Specific GPU models or custom accelerators
- Strict compliance or data residency requirements: Limited deployment location options
- Extensive customization is needed: Unusual runtime or networking requirements
- Long-running inference tasks: Exceeding platform time limits
Major Serverless Inference Platforms Compared
Several cloud providers offer serverless inference solutions. Here's a comparison of the leading options:
AWS SageMaker Serverless Inference
Amazon's offering integrates tightly with their broader AI/ML ecosystem. Key features include:
- Support for popular ML frameworks (TensorFlow, PyTorch, XGBoost, etc.)
- Automatic scaling from zero
- Pay-per-millisecond pricing
- Integration with SageMaker pipelines and features
- Cold start optimization options
Google Cloud AI Platform Predictions
Google's serverless inference solution emphasizes ease of use and integration with their AI services:
- Automated resource scaling
- Built-in monitoring and logging
- Support for custom containers
- Tight integration with Vertex AI
- Regional deployment options
Azure Machine Learning Online Endpoints
Microsoft's serverless offering focuses on enterprise integration and MLOps:
- Automatic scaling and load balancing
- Blue-green deployment support
- Integration with Azure DevOps and GitHub Actions
- Managed virtual network isolation
- Multi-model deployment support
Specialized Platforms
Beyond the major clouds, several specialized platforms offer unique advantages:
- Modal: Focus on Python-centric development with simple abstractions
- Banana Dev: Simplified deployment with focus on developer experience
- Replicate: Open model hosting with community sharing features
- Hugging Face Inference Endpoints: Specialized for transformer models
Getting Started: A Step-by-Step Guide
Now let's walk through a practical example of deploying a model using serverless inference. We'll use AWS SageMaker Serverless Inference as our example, but the concepts apply broadly.
Step 1: Prepare Your Model
First, ensure your model is properly packaged. Most platforms support common formats:
For TensorFlow Models:
Save your model in the SavedModel format:
For PyTorch Models:
Use TorchScript or export to ONNX format for better compatibility:
For Scikit-Learn Models:
Use joblib or pickle serialization with version compatibility:
Step 2: Choose Your Deployment Platform
Evaluate platforms based on:
- Pricing model and estimated costs
- Supported frameworks and versions
- Geographic availability
- Integration with your existing tools
- Specific feature requirements
Step 3: Set Up Authentication and Permissions
Most cloud platforms require:
- Account creation and billing setup
- API keys or IAM role configuration
- Resource quota requests if needed
- Network and security group configuration
Step 4: Package and Upload Your Model
Create a deployment package containing:
Step 5: Configure Serverless Endpoint
Set up your serverless endpoint with appropriate configuration:
Step 6: Test Your Deployment
Thoroughly test your endpoint with:
- Sample inference requests
- Load testing (gradually increasing traffic)
- Error case testing
- Latency and performance validation
Step 7: Implement Monitoring and Alerting
Configure monitoring for:
- Request rates and error percentages
- Latency percentiles (P50, P90, P99)
- Cost tracking and budget alerts
- Model performance drift detection
Cost Optimization Strategies
While serverless inference can be cost-effective, optimization is still important. Here are key strategies:
1. Right-Size Your Memory Allocation
Memory allocation directly impacts both performance and cost. Too little causes out-of-memory errors; too much wastes money. Test different allocations to find the sweet spot.
2. Implement Intelligent Batching
Where possible, batch multiple requests together. This improves throughput and reduces per-request overhead. However, balance batching with latency requirements.
3. Use Provisioned Concurrency Wisely
Some platforms offer "provisioned concurrency" to keep instances warm, eliminating cold starts for predictable traffic. Use this selectively for critical endpoints.
4. Implement Caching Where Appropriate
Cache common inference results when possible. This reduces compute costs and improves response times for repeated requests.
5. Monitor and Clean Up Unused Endpoints
Regularly review and decommission endpoints that are no longer needed. Even idle endpoints may incur minimal costs in some platforms.
6. Leverage Spot/Preemptible Instances When Available
Some platforms offer discounted pricing for interruptible capacity. This can significantly reduce costs for non-critical workloads.
Performance Optimization Techniques
Beyond cost, optimizing serverless inference performance is crucial for user experience:
1. Model Optimization
Before deployment, optimize your model:
- Quantization (reducing precision from FP32 to INT8)
- Pruning (removing unimportant weights)
- Knowledge distillation (training smaller models)
- Architecture optimization for inference
2. Cold Start Mitigation
Several strategies can help minimize cold start impact:
- Keep-alive pings for frequently used endpoints
- Warm-up scripts before peak periods
- Smaller model sizes load faster
- Platform-specific optimization features
3. Efficient Serialization
Optimize how data moves between components:
- Use binary formats instead of JSON for large payloads
- Implement compression for input/output data
- Minimize payload size through intelligent design
4. Concurrent Execution Optimization
Configure concurrency settings based on your workload pattern:
- Higher concurrency for many small requests
- Lower concurrency for fewer large requests
- Adaptive concurrency based on time of day
Security Best Practices
Security is paramount when deploying AI models. Serverless inference introduces both challenges and opportunities:
1. Authentication and Authorization
Implement robust access controls:
- API keys with rotation policies
- OAuth2 or JWT-based authentication
- Fine-grained IAM policies
- Request signing and validation
2. Data Protection
Protect data in transit and at rest:
- Always use TLS/SSL encryption
- Implement input validation and sanitization
- Consider data anonymization for sensitive inputs
- Compliance with data residency requirements
3. Model Protection
Secure your intellectual property:
- Model encryption where supported
- Obfuscation techniques for sensitive models
- License enforcement mechanisms
- Watermarking for generated content
4. Monitoring and Auditing
Maintain visibility into your deployment:
- Comprehensive logging of all requests
- Anomaly detection for unusual patterns
- Regular security audits and penetration testing
- Compliance reporting capabilities
Real-World Use Cases and Examples
Serverless inference powers a wide range of applications. Here are practical examples:
1. E-commerce Product Recommendations
An online retailer uses serverless inference to provide personalized product recommendations. Traffic spikes during sales events are handled automatically, while costs remain low during off-peak hours.
2. Content Moderation System
A social media platform employs serverless inference for image and text moderation. The pay-per-use model aligns costs with actual content volume, which varies throughout the day.
3. Document Processing Pipeline
A financial institution processes loan applications using serverless inference for document analysis. Batch processing overnight utilizes cost-effective serverless capacity without maintaining 24/7 infrastructure.
4. Chatbot and Customer Service
A customer support chatbot uses serverless inference for natural language understanding. Automatic scaling handles unpredictable conversation volumes during product launches or outages.
5. IoT Sensor Analytics
Smart devices send sensor data for real-time anomaly detection using serverless inference. The system scales with device deployments without manual intervention.
Common Pitfalls and How to Avoid Them
Learning from others' mistakes can save time and money. Here are common pitfalls:
1. Underestimating Cold Start Impact
Problem: Assuming all requests will have consistent latency, then encountering unpredictable delays during low-traffic periods.
Solution: Implement comprehensive load testing across different traffic patterns. Use provisioned concurrency or keep-alive mechanisms for latency-sensitive applications.
2. Ignoring Cost Monitoring
Problem: Unexpected bills from unanticipated traffic spikes or inefficient configurations.
Solution: Implement budget alerts and cost monitoring from day one. Use cost estimation tools before deployment.
3. Overlooking Vendor Lock-in
Problem: Becoming so dependent on platform-specific features that migration becomes prohibitively expensive.
Solution: Abstract platform-specific code behind interfaces. Consider multi-cloud strategies for critical applications.
4. Neglecting Monitoring and Observability
Problem: Difficulty debugging issues in production due to limited visibility into the serverless environment.
Solution: Implement comprehensive logging, distributed tracing, and performance monitoring from the beginning.
5. Forgetting About Model Management
Problem: Deploying models without proper versioning, rollback capabilities, or A/B testing infrastructure.
Solution: Implement proper MLOps practices including model registry, canary deployments, and performance tracking.
The Future of Serverless Inference
Serverless inference continues to evolve rapidly. Here are trends to watch:
1. Specialized Hardware Integration
Cloud providers are integrating specialized AI accelerators (TPUs, Inferentia, etc.) into serverless offerings, providing better performance and cost efficiency for specific workloads.
2. Edge Computing Convergence
Serverless principles are extending to edge locations, enabling low-latency inference closer to end-users while maintaining the operational simplicity of serverless.
3. Improved Cold Start Performance
Platforms are implementing smarter pre-warming, snapshot-based initialization, and other techniques to reduce or eliminate cold start latency.
4. Multi-Model and Ensemble Support
Native support for deploying multiple models together, enabling complex inference pipelines and ensemble methods within serverless frameworks.
5. Enhanced Observability and Debugging
Better tooling for debugging serverless inference, including improved tracing, profiling, and visualization of distributed inference workflows.
Getting Started: Practical Next Steps
Ready to try serverless inference? Here's a practical roadmap:
1. Start Small with a Non-Critical Model
Choose a simple, non-critical model for your first serverless deployment. This reduces risk while you learn the platform and workflow.
2. Set Up a Sandbox Environment
Create a separate account or project with budget limits to experiment without impacting production systems or incurring unexpected costs.
3. Follow Tutorials and Examples
Most platforms provide getting-started tutorials. Work through these to understand the basics before customizing for your needs.
4. Implement Comprehensive Monitoring Early
Set up cost monitoring, performance tracking, and alerting from the beginning. This prevents surprises and helps with optimization.
5. Join Community Forums and Discussions
Participate in platform-specific communities to learn from others' experiences, ask questions, and stay updated on best practices.
Conclusion
Serverless inference represents a significant advancement in how we deploy and serve AI models. By abstracting away infrastructure complexity, it enables faster development cycles, cost-effective scaling, and reduced operational overhead. While not suitable for every use case – particularly those with stringent latency requirements or specialized hardware needs – it offers compelling advantages for a wide range of applications.
The key to successful serverless inference adoption lies in understanding both its strengths and limitations, carefully evaluating platform options, and implementing appropriate optimization and monitoring strategies. As the technology continues to mature, with improvements in cold start performance, specialized hardware support, and developer tooling, serverless inference is poised to become an increasingly important part of the AI deployment landscape.
Whether you're deploying your first AI model or optimizing an existing production system, serverless inference offers tools and approaches worth considering. By starting with a clear understanding of your requirements, testing thoroughly, and implementing best practices from the beginning, you can leverage serverless inference to build scalable, cost-effective AI applications that meet your users' needs while minimizing operational complexity.
Visuals Produced by AI
Further Reading
Share
What's Your Reaction?
 Like
15210
Like
15210
 Dislike
87
Dislike
87
 Love
2345
Love
2345
 Funny
412
Funny
412
 Angry
23
Angry
23
 Sad
15
Sad
15
 Wow
1650
Wow
1650
















The monitoring section needs expansion. We built a custom solution combining Datadog, CloudWatch, and business metrics. Would love to see an article on serverless AI observability best practices!
I recommend this article to all my clients considering AI deployment. The balanced perspective on pros AND cons is rare to find. Most articles just hype the benefits without discussing limitations.
We're using serverless inference for real-time video analysis at the edge with AWS Wavelength. The combination of 5G and serverless is revolutionary for mobile applications. The future is here!
The environmental impact section convinced our sustainability committee! We're now tracking carbon savings from our AI infrastructure as part of our corporate responsibility report. Unexpected benefit!
Security question: How do you handle model updates in serverless? With traditional servers we have downtime during deployment. With serverless, can we do zero-downtime updates?
Marcus, great question! Serverless enables blue-green deployment: deploy new version alongside old, test it, then gradually shift traffic. Most platforms support canary deployments and A/B testing natively. Some even support traffic splitting by percentage. Zero downtime is definitely achievable!
The real-world use cases helped me pitch this to our product team. Showing concrete examples from e-commerce and IoT made the benefits tangible beyond just technical specs. More case studies please!