Cost Optimization for AI: Saving Money on Inference
This comprehensive guide explains how to significantly reduce AI inference costs without compromising performance. We cover the complete cost breakdown of AI inference, including compute, storage, networking, and API expenses. You'll learn practical strategies like model selection optimization, infrastructure right-sizing, advanced serving techniques like continuous batching and quantization, and effective caching strategies. The article includes a step-by-step cost audit methodology, comparison tables of optimization techniques with ROI estimates, and real-world case studies showing 40-80% cost reductions. Whether you're using cloud services, on-premise hardware, or hybrid setups, this guide provides actionable insights for beginners and professionals alike to manage AI budgets effectively.
Cost Optimization for AI: Saving Money on Inference
As artificial intelligence moves from experimentation to production, one challenge consistently emerges: managing the costs of running AI models. Unlike training costs which are often one-time investments, inference costs—the expense of actually using trained models—are ongoing and can quickly spiral out of control. A poorly optimized AI inference pipeline can cost 3-5 times more than necessary, draining budgets and limiting scalability.
This comprehensive guide will walk you through practical, actionable strategies to reduce your AI inference costs by 40-80% without compromising performance. Whether you're a startup running your first AI feature, a mid-sized business scaling AI applications, or an enterprise managing multiple AI services, these cost optimization techniques will help you get more value from your AI investments.
Understanding AI Inference Costs: The Complete Breakdown
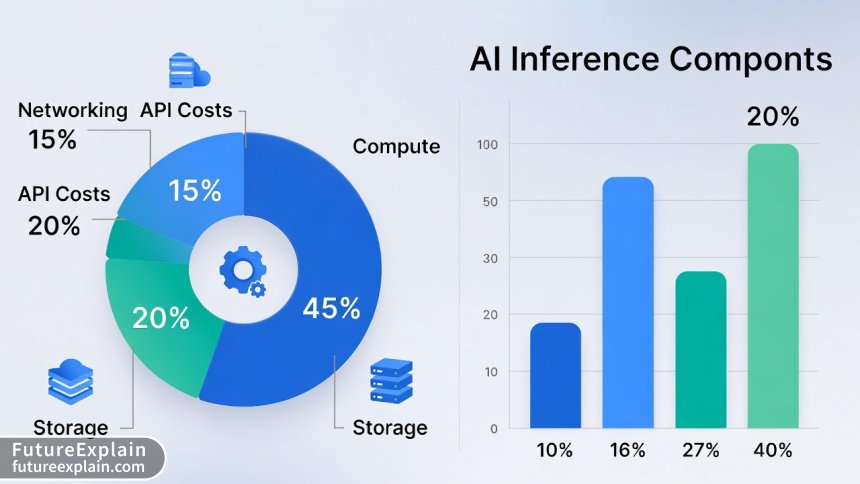
Before diving into optimization strategies, it's crucial to understand where your money is actually going. AI inference costs typically break down into four main categories:
1. Compute Costs (45-70% of Total)
Compute represents the largest portion of inference costs. This includes:
- GPU/TPU Costs: The most expensive component, especially for large language models (LLMs) and computer vision models
- CPU Costs: Often overlooked but significant for pre/post-processing and smaller models
- Memory Costs: GPU memory (VRAM) and system RAM requirements
2. Storage Costs (10-25% of Total)
Storage expenses include:
- Model Storage: Storing model weights and checkpoints
- Data Storage: Input/output data, cached results, and logs
- Backup Storage: Disaster recovery and versioning
3. Networking Costs (5-20% of Total)
Network-related expenses:
- Data Transfer: Ingress and egress fees, especially in cloud environments
- Load Balancer Costs: Distributing traffic across inference endpoints
- API Gateway Costs: Managing and routing API requests
4. API and Service Costs (15-40% of Total)
When using managed services:
- Per-Token/Request Charges: Common with OpenAI, Anthropic, and other API providers
- Platform Fees: Base costs for using inference platforms
- Support and SLA Costs: Premium support and service level agreements
The Cost Optimization Framework: A Systematic Approach
Effective cost optimization requires a systematic approach. Follow this four-phase framework:
Phase 1: Assessment and Benchmarking
Begin by conducting a thorough cost audit. Map your current inference pipeline and identify:
- Peak vs. average utilization rates
- Cost per request/transaction
- Most expensive model endpoints
- Inefficient resource allocation patterns
Phase 2: Model-Level Optimizations
Optimize at the model level before infrastructure:
- Model selection and architecture choices
- Precision reduction and quantization
- Model pruning and distillation
- Prompt optimization for LLMs
Phase 3: Infrastructure Optimizations
Optimize the deployment environment:
- Right-sizing compute resources
- Efficient scaling strategies
- Geographic optimization
- Caching and content delivery networks
Phase 4: Continuous Monitoring and Improvement
Establish ongoing optimization practices:
- Cost monitoring and alerting
- Regular optimization reviews
- Experimenting with new techniques
- Team education and best practices
Model Selection and Architecture Optimization
The most impactful cost optimization happens at the model selection stage. Choosing the right model architecture can reduce inference costs by 10-50x.
Choosing the Right Model Size
Bigger isn't always better. Consider these factors:
- Accuracy vs. Cost Trade-off: Does your application need 95% accuracy or will 90% suffice at 1/10th the cost?
- Latency Requirements: Real-time applications may need smaller, faster models
- Hardware Constraints
Specialized vs. General Models
Specialized models trained for specific tasks often outperform larger general models while being significantly cheaper to run. For example:
- A specialized sentiment analysis model (50M parameters) vs. GPT-4 (1.7T parameters)
- A custom object detection model vs. general vision transformer
Open Source vs. Proprietary Models
The open-source ecosystem offers compelling cost advantages:
- No per-token fees: Predictable costs based on infrastructure
- Custom optimization: Ability to apply advanced optimization techniques
- No vendor lock-in: Flexibility to switch providers
Advanced Model Optimization Techniques
Once you've selected an appropriate model, these techniques can further reduce inference costs:
Quantization: Reducing Precision
Quantization reduces the numerical precision of model weights, dramatically decreasing memory and compute requirements:
- FP32 to FP16: 2x memory reduction, 1.5-2x speedup
- FP16 to INT8: Another 2x memory reduction, 2-3x speedup
- INT8 to INT4: 4x memory reduction, specialized hardware required
Most models can be quantized to INT8 with minimal accuracy loss (typically 1-3%). Tools like TensorRT, OpenVINO, and ONNX Runtime make quantization accessible.
Model Pruning: Removing Unnecessary Weights
Pruning identifies and removes weights that contribute little to model performance:
- Structured Pruning: Removes entire neurons or channels
- Unstructured Pruning: Removes individual weights
- Iterative Pruning: Gradual removal with retraining
Knowledge Distillation: Teaching Smaller Models
Distillation trains a smaller "student" model to mimic a larger "teacher" model:
- 10-100x parameter reduction
- Often retains 90-95% of original accuracy
- Significantly faster inference
Infrastructure Optimization Strategies
The right infrastructure choices can make or break your cost optimization efforts.
Right-Sizing Compute Resources
Avoid over-provisioning with these strategies:
- GPU Selection: Match GPU memory to model requirements
- Spot/Preemptible Instances: 60-90% discount for fault-tolerant workloads
- Reserved Instances: 30-75% discount for predictable workloads

Efficient Scaling Strategies
Implement intelligent scaling to match demand:
- Horizontal vs. Vertical Scaling: Horizontal is often more cost-effective
- Predictive Scaling: Scale based on predicted demand patterns
- Cold Start Optimization: Keep minimal instances warm to reduce latency
Geographic Optimization
Deploy models closer to users:
- Reduce latency and data transfer costs
- Take advantage of regional pricing differences
- Consider edge deployment for high-frequency use cases
Advanced Serving Techniques for Maximum Efficiency
Modern model serving frameworks offer sophisticated optimization features:
Continuous Batching
Traditional batching waits for a full batch before processing. Continuous batching dynamically adds and removes requests:
- 2-10x higher GPU utilization
- Lower latency for individual requests
- Supported by vLLM, TensorRT-LLM, and Text Generation Inference
Speculative Decoding
An emerging technique that uses a smaller, faster "draft" model to predict tokens, verified by the main model:
- 1.5-3x speedup for LLM inference
- Particularly effective for autoregressive models
- Implemented in recent versions of popular serving frameworks
Paged Attention
Optimizes memory usage during attention computation:
- Reduces memory fragmentation
- Enables longer context windows
- 30-50% memory savings for long sequences
Caching Strategies: The Low-Hanging Fruit
Caching is one of the most effective yet overlooked optimization techniques:
Response Caching
Cache identical or similar requests:
- Exact Match Caching: Cache identical requests
- Semantic Caching: Cache semantically similar requests using embeddings
- Partial Response Caching: Cache components of complex responses
Embedding Caching
For RAG (Retrieval-Augmented Generation) applications:
- Cache document embeddings to avoid recomputation
- Cache query embeddings for frequent searches
- Use vector databases with built-in caching
Multi-Level Caching Architecture
Implement a hierarchical caching strategy:
- L1 Cache: In-memory cache on inference servers
- L2 Cache: Distributed cache (Redis, Memcached)
- L3 Cache: CDN for global distribution
Cost Monitoring and Governance
You can't optimize what you can't measure. Implement robust cost monitoring:
Key Metrics to Track
- Cost Per Request: Total cost divided by number of requests
- GPU Utilization: Percentage of time GPU is actively computing
- Cache Hit Rate: Percentage of requests served from cache
- Error Rate vs. Cost: Relationship between reliability and expense
Cost Allocation and Tagging
Implement granular cost tracking:
- Tag resources by project, team, and environment
- Implement showback/chargeback for internal teams
- Set up budget alerts and quotas
Regular Optimization Reviews
Schedule monthly cost review meetings to:
- Analyze cost trends and anomalies
- Identify new optimization opportunities
- Review optimization ROI and prioritize initiatives
Real-World Case Studies and ROI Examples
Case Study 1: E-commerce Product Recommendations
Challenge: 50% monthly cost growth for recommendation engine serving 10M requests/day
Solution:
- Replaced general LLM with specialized collaborative filtering model
- Implemented quantization (FP32 → INT8)
- Added semantic caching with 40% hit rate
Results: 68% cost reduction, latency improved from 250ms to 85ms
Case Study 2: Customer Support Chatbot
Challenge: High costs for GPT-4 API with inconsistent response quality
Solution:
- Fine-tuned Llama 3 8B for specific support domains
- Implemented RAG with cached embeddings
- Used continuous batching on A10G instances
Results: 82% cost reduction, accuracy improved from 75% to 88%
Case Study 3: Document Processing Pipeline
Challenge: Expensive OCR and text extraction for variable document volumes
Solution:
- Implemented spot instances for batch processing
- Added automatic model selection based on document complexity
- Created multi-region deployment for global customers
Results: 57% cost reduction, 99.9% uptime achieved
Emerging Trends and Future Considerations
The AI cost optimization landscape is rapidly evolving. Stay ahead with these trends:
Specialized AI Hardware
New hardware optimized for AI inference:
- Inferentia (AWS): Custom chips for inference
- Groq LPU: Language processing units
- Habana Gaudi: AI training and inference accelerators
Serverless AI Inference
Pay-per-millisecond pricing models:
- AWS SageMaker Serverless Inference
- Google Cloud Run for AI
- Azure Container Instances
Federated Learning and Edge AI
Reduce data transfer and central processing:
- Process data locally on edge devices
- Aggregate learnings centrally
- Significant bandwidth and privacy benefits
Getting Started: Your 30-Day Optimization Plan
Ready to start optimizing? Follow this actionable 30-day plan:
Week 1: Assessment and Instrumentation
- Implement comprehensive cost tracking
- Identify top 3 most expensive endpoints
- Establish baseline metrics
Week 2-3: Quick Wins Implementation
- Implement response caching
- Right-size underutilized resources
- Optimize prompts (for LLMs)
Week 4: Strategic Optimizations
- Evaluate model alternatives
- Plan architecture improvements
- Design long-term optimization roadmap
Common Pitfalls to Avoid
Learn from others' mistakes:
- Over-Optimization: Don't spend $100 to save $1
- Ignoring Hidden Costs: Consider all cost components
- Sacrificing Reliability: Maintain appropriate SLAs
- Vendor Lock-in: Maintain flexibility
- Technical Debt: Balance quick fixes with sustainable solutions
Conclusion: Sustainable AI Cost Management
AI cost optimization isn't a one-time project but an ongoing practice. The most successful organizations treat cost efficiency as a core requirement, not an afterthought. By implementing the strategies outlined in this guide—from model selection and quantization to intelligent scaling and caching—you can achieve dramatic cost reductions while maintaining or even improving performance.
Remember that every AI application is unique. Start with a thorough assessment, prioritize based on potential ROI, and implement optimizations incrementally. Monitor results closely, learn from each optimization, and continuously refine your approach. With the right strategies and mindset, you can build AI systems that are both powerful and cost-effective, enabling sustainable growth and innovation.
Visuals Produced by AI
Further Reading
Share
What's Your Reaction?
 Like
1421
Like
1421
 Dislike
23
Dislike
23
 Love
567
Love
567
 Funny
89
Funny
89
 Angry
12
Angry
12
 Sad
8
Sad
8
 Wow
345
Wow
345

















The serverless inference mention intrigued me. We have spiky workloads that seem perfect for serverless. Anyone have experience with cold start times for larger models? That's our main concern.
Maxwell, cold starts are indeed the challenge. For models under 2GB, serverless can work well with 2-5 second cold starts. For larger models, consider: 1) Provisioned concurrency (keeps instances warm), 2) Hybrid approach (serverless for spikes, dedicated for baseline), 3) Model partitioning (load parts on demand). We're seeing innovations here monthly, so this is rapidly improving.
How do you balance optimization efforts with keeping up with rapidly evolving models? We optimize for a model, then a better one gets released, and we have to start over. It feels like chasing our tail.
Priya, we faced this too. Our solution: 1) Standardize optimization techniques that transfer across models (quantization, caching), 2) Create model evaluation pipelines that include cost metrics, 3) Only switch models when the total cost of change (including re-optimization) is justified by the improvements. Sometimes staying with a slightly inferior but well-optimized model is better.
This should be required reading for anyone building AI products. The ROI mindset is crucial - we treat every optimization as an investment with expected returns. Some have 300% ROI, others aren't worth pursuing. The framework helps prioritize.
The hardware comparison would benefit from more detail on the new AI chips. We're evaluating Inferentia vs. T4 vs. A10G for our specific workload. Any benchmarks or decision frameworks you recommend?
Jeremiah, we just went through this evaluation. Key factors: 1) Model compatibility (check official support), 2) Batch size requirements (some chips optimize for large batches), 3) Memory bandwidth needs, 4) Software ecosystem maturity. AWS has a great cost calculator that includes Inferentia, but nothing beats running your actual workload on each option.
Could you provide more guidance on cost monitoring? We have CloudWatch alarms but they feel reactive rather than proactive. What metrics are most predictive of cost overruns?
Zariyah, the most predictive metrics we've found are: 1) Cost per request trend (not just absolute), 2) Cache hit rate degradation, 3) Model latency increases (often indicates need for more resources), 4) Request pattern changes (new peaks or valleys). Setting up anomaly detection on these metrics can provide early warnings.
The model selection advice is gold. We were using a massive multimodal model for simple text classification because "it was the best model available." Switched to a 100x smaller specialized model and got better accuracy at 5% of the cost. Sometimes simpler really is better!