Open Data & Licenses: Where to Source Training Data
Finding the right data to train an AI model can be a major hurdle. This guide demystifies the world of open data and licensing for beginners. You'll learn where to find high-quality, free datasets from sources like Common Crawl, government portals, and academic projects. More importantly, we clearly explain how to navigate licenses like Creative Commons and public domain rules, so you can use data legally and ethically. We also cover essential first steps for cleaning and preparing your downloaded data, providing a complete, actionable roadmap for your first AI training project.

Training an artificial intelligence model requires vast amounts of data, often referred to as its 'fuel' [citation:9]. For beginners, students, or small businesses, acquiring this fuel can seem prohibitively expensive or legally complex. Fortunately, a world of open data—information made freely available for use and redistribution—exists. This guide will walk you through where to find this data and, crucially, how to understand the licenses that govern its use, empowering you to start your AI projects confidently and correctly.
Why Open Data is a Game-Changer for AI Beginners
Open-source datasets democratize AI development. They provide a cost-effective alternative to proprietary data, allowing individuals and smaller organizations to access diverse, high-quality information without a massive financial investment [citation:1]. This fosters transparency and reproducibility in research, as others can use the same data to verify or build upon your work. Furthermore, these datasets often encompass a wide range of topics and perspectives, which can help in creating more balanced and inclusive AI models [citation:1].
Major Repositories: Your Starting Points for Data
Think of these repositories as the largest libraries for machine learning data. They aggregate thousands of datasets, making them the best first stop for your search.
Hugging Face Datasets
The Hugging Face Hub is a central platform for the AI community, hosting a massive collection of datasets for tasks like text generation, translation, and image recognition. Its user-friendly interface and integration with popular coding libraries make it ideal for beginners. You can easily filter datasets by task, language, or license.
Kaggle Datasets
Kaggle is not just for competitions; it's also a vibrant community where researchers and companies publish datasets. It's excellent for finding practical, often well-documented data related to specific business problems or research questions. Many datasets include example notebooks (code tutorials) to help you get started [citation:9].
Google Dataset Search
This tool works like a search engine for datasets. It indexes thousands of repositories across the web, from government sites to university libraries. When you're looking for something very specific, this is the tool to use to scan the entire open data landscape [citation:9].
Key Categories of Open Data for AI
Open data comes from many spheres. Understanding these categories helps you know where to look for specific types of information.
1. Web-Crawled Corpus Data
This category includes massive, broad collections of text and images scraped from the public internet. They form the foundation for training large, general-purpose language and vision models.
- Common Crawl: A cornerstone of modern AI. This non-profit provides an enormous, freely accessible archive of web crawl data—over 250 billion pages gathered over 17 years [citation:1]. It's a raw resource used to train foundational models like GPT-3 and LLaMA [citation:6].
- RefinedWeb: A prime example of a processed web corpus. It takes data from Common Crawl and applies rigorous filtering and deduplication to create a higher-quality dataset of over 5 trillion tokens. It was created to train the Falcon-40B model and demonstrates the power of clean web data [citation:1][citation:6].
- The Pile: An 800 GB dataset curated from 22 diverse academic and professional sources (like academic papers, GitHub code, and forums). Its diversity helps AI models generalize better across different topics and writing styles [citation:1][citation:6].
2. Government & Public Sector Data
Governments worldwide release vast amounts of data on topics like transportation, health, economics, and environment. This data is typically factual, well-structured, and released under permissive licenses.
- Data.gov (U.S.): The home of the U.S. government's open data, offering over 350,000 datasets on everything from climate science to small business trends [citation:2]. The U.S. Department of Commerce has even released guidelines to make such data more usable for generative AI applications [citation:5].
- International Open Data Portals: Similar portals exist globally, such as data.gov.uk (UK) and data.europa.eu (EU). Policies like the EU's Data Act and European Health Data Space (EHDS) are actively working to standardize and facilitate more secure data sharing for research and innovation [citation:5].
3. Academic & Non-Profit Research Data
Universities and research labs are major producers of high-quality, niche datasets. These are often created for specific research papers and shared to allow reproducibility.
- Multimodal Datasets: Projects like InternVid (7M videos with text captions) or Flickr30k Entities (31,000 images with detailed annotations) are built to train AI that understands both text and visuals [citation:10].
- Specialized Corpora: Datasets like ROOTS, a 1.6TB multilingual text collection in 59 languages, support the development of non-English AI models [citation:1]. The Books Data Commons initiative, explored by Creative Commons, is looking at ways to responsibly provide access to digitized book collections for AI training [citation:8].
Understanding Licenses: The Rules of the Road
An open dataset isn't necessarily 'free' to use in any way you want. It is governed by a license. Ignoring licenses is a legal risk. Here’s a plain-language guide to the most common types.
Creative Commons Licenses
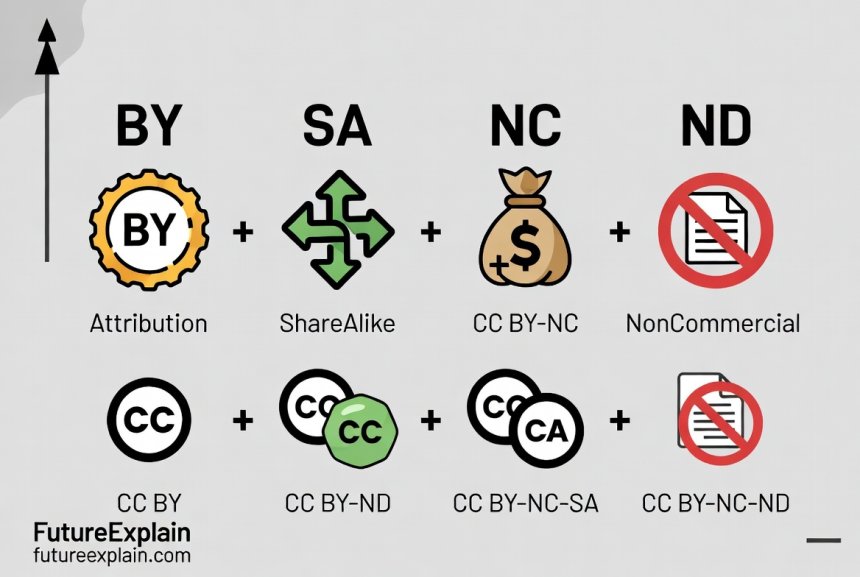
Creative Commons (CC) licenses are the most common standard for sharing creative and research work. They are built from four basic conditions [citation:3]:
- BY (Attribution): You must credit the original creator.
- SA (ShareAlike): If you adapt the data, you must share your new work under the same license.
- NC (NonCommercial): You cannot use the data for commercial purposes.
- ND (NoDerivatives): You can use the data, but you cannot create modified or derivative works from it.
These conditions mix to form licenses like CC BY (most permissive, just require credit) or CC BY-NC-SA (credit, non-commercial, and share-alike). For AI training, the ND (NoDerivatives) restriction is a critical red flag—using ND-licensed content to train a model, which inherently creates derivatives, is very likely prohibited [citation:3].
Public Domain & Specialized Licenses
- Public Domain (CC0): The creator has waived all rights. You can use the data for any purpose without restriction, making it ideal for AI training.
- Open Government Licenses: Many governments use their own simple terms, like the UK's Open Government Licence (OGL), which is broadly permissive for reuse.
- Academic/Non-Commercial Licenses: Common in research, these allow use for educational or research purposes but prohibit commercial deployment. Always check the terms.
A Practical Licensing Checklist
Before downloading a dataset, ask these questions:
- What is the exact license name? (e.g., CC BY-SA 4.0, MIT, ODbL).
- Does it have a ShareAlike (SA) condition? This may affect how you license your final AI model.
- Does it have a NonCommercial (NC) restriction? This blocks any for-profit use.
- Does it have a NoDerivatives (ND) restriction? If yes, it is generally not suitable for AI training.
- What attribution is required? Plan how you will credit the source.
From Download to Model: Essential First Steps
Raw open data is rarely ready for immediate use. Data preprocessing is a critical step to ensure your model learns from clean, consistent information [citation:6].
1. Cleaning and Filtering
Datasets, especially large web crawls, contain noise. Basic cleaning involves:
- Deduplication: Removing identical or near-identical entries to prevent the model from overfitting to repeated information.
- Language Filtering: If you're building an English model, filter out non-English text.
- Removing Gibberish/Boilerplate: Filter out low-quality text like error messages, navigation menus, or nonsensical content.
2. Ethical Review and Bias Checking
Datasets can reflect societal biases. Before training, try to:
- Understand the Source: Where did the data come from? A forum, academic journals, or news sites? This influences its perspective.
- Use Bias Detection Tools (for advanced users): Some tools can help analyze text for stereotypes or unequal representation.
3. Formatting for Your Tool
Finally, structure the data so your machine learning framework (like TensorFlow or PyTorch) can read it. This usually means converting it into a standard format like JSON Lines (.jsonl) or CSV and ensuring text is properly encoded.
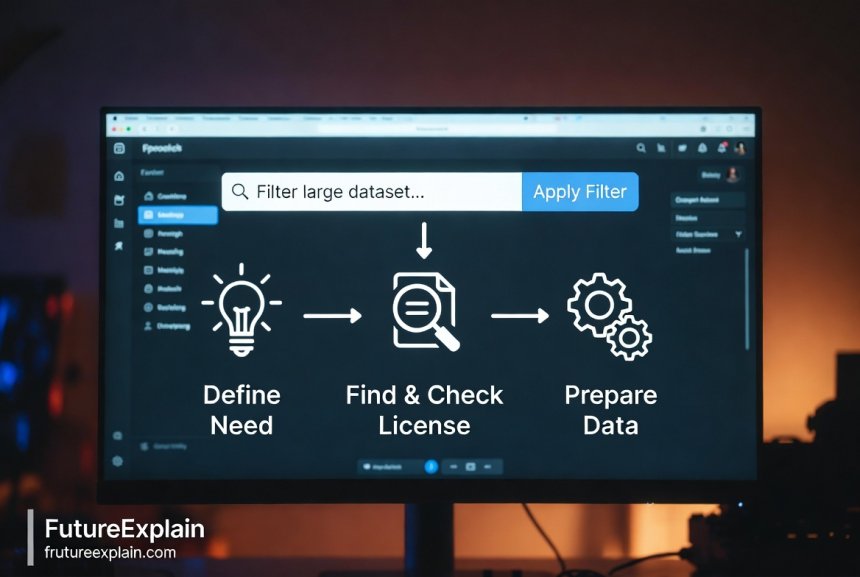
A Simple Workflow for Your First Project
To tie it all together, here is a straightforward, five-step workflow for sourcing your first training dataset:
- Define Your Need: Be specific. "I need English sentences labeled with positive or negative sentiment for a sentiment analysis model."
- Search a Major Repository: Go to Hugging Face Datasets or Kaggle and use your project keywords as search terms.
- Evaluate the License: For any promising dataset, immediately check its license using the checklist above. Disqualify any with ND restrictions.
- Inspect the Data Download a small sample. Open it, look at the quality, and check the structure. Does it match what you need?
- Plan Your Preprocessing: Based on your inspection, note what cleaning steps (deduplication, filtering) you'll need to perform before training.
Conclusion: Building on a Solid Foundation
Sourcing open data for AI is a skill that blends research, legal understanding, and technical preparation. By starting with reputable repositories, diligently checking licenses, and applying careful preprocessing, you build your projects on a foundation that is both powerful and responsible. The open data ecosystem is vast and growing, fueled by communities, governments, and researchers. By understanding how to navigate it, you unlock the potential to train AI that is innovative, equitable, and built for the benefit of all.
Further Reading
Share
What's Your Reaction?
 Like
1550
Like
1550
 Dislike
12
Dislike
12
 Love
320
Love
320
 Funny
45
Funny
45
 Angry
8
Angry
8
 Sad
5
Sad
5
 Wow
210
Wow
210

















This has been bookmarked. As a project manager overseeing an AI initiative, I'm sending this link to my entire team. It sets the right foundation.
The five-step workflow is the MVP of this article. Clear, actionable steps beat vague theory any day. Thanks for providing a real roadmap.
Is there a similar go-to guide for synthetic data? After reading this, I'm curious about when to use real open data vs. when to generate your own.
Great segue, Kylian! We actually have an article dedicated to that exact question. Check out "Synthetic Data for Training: When and How to Use It" (linked at the bottom of this article). It covers the pros, cons, and tools for generating data when real data is scarce or sensitive.
The "Ethical Review" section should be bolded and highlighted. It's the step everyone wants to skip, but it's probably the most important one for building responsible tech.
This demystified a huge part of AI for me. I always thought you needed to collect your own data from scratch. Knowing these repositories exist changes everything.
Practical and to the point. No fluff, just the info you need to actually get started. More articles like this, please.