Model Cards & Responsible Documentation: A Template
This comprehensive guide provides everything you need to create effective model cards and responsible AI documentation. We start by explaining why model cards are essential for transparency, accountability, and compliance in today's AI landscape. You'll learn the core principles of responsible documentation, including what information to include and why. The heart of the article is a complete, fillable template with 25+ sections covering model details, training data, performance metrics, limitations, ethical considerations, and deployment information. We provide step-by-step implementation guidance for teams of all sizes, real-world examples across different industries, and strategies for maintaining documentation throughout the model lifecycle. The article also includes a compliance checklist for major regulations like the EU AI Act and practical advice for avoiding common documentation pitfalls. Whether you're a solo developer or part of an enterprise team, this guide gives you the tools to create documentation that builds trust and ensures responsible AI deployment.

Model Cards & Responsible Documentation: A Template
In the rapidly evolving world of artificial intelligence, transparency is no longer optional—it's essential. As AI systems increasingly influence decisions in healthcare, finance, employment, and everyday life, stakeholders need to understand how these systems work, what they can and cannot do, and what risks they might pose. This is where model cards and responsible documentation come into play. These tools serve as the bridge between AI developers and everyone else affected by AI systems: users, regulators, business leaders, and society at large.
Think of a model card as a nutritional label for AI. Just as food packaging tells you about ingredients, calories, and potential allergens, a model card provides essential information about an AI system. It answers critical questions: What was this model trained to do? What data was used? How well does it perform across different groups? What are its limitations? Who should use it, and who should avoid it?
This comprehensive guide will walk you through everything you need to create effective model cards and responsible documentation. We'll start with the fundamentals, explore why this practice matters more than ever in 2025, and then provide you with a complete, practical template you can adapt for your own projects. Whether you're building small machine learning models for personal projects or deploying enterprise-scale AI systems, this guide will give you the tools to document your work responsibly.
Why Model Cards Matter in 2025
The concept of model cards was introduced in a seminal 2019 paper by researchers at Google, but their importance has grown exponentially since then. Several key developments in 2024 and early 2025 have made comprehensive documentation not just a best practice, but often a legal requirement:
- Regulatory Pressure: The EU AI Act, which became fully enforceable in 2024, requires detailed documentation for high-risk AI systems. Similar regulations are emerging worldwide, from the US AI Executive Order to Canada's proposed AI and Data Act.
- Enterprise Adoption: As AI moves from experimentation to core business operations, companies need standardized documentation for governance, risk management, and compliance.
- Foundation Model Proliferation: The widespread use of large language models and other foundation models creates new documentation challenges around capabilities, limitations, and appropriate use cases.
- Multimodal AI Growth: Systems that combine text, image, audio, and video processing require more complex documentation to explain their capabilities and limitations.
- Supply Chain Transparency: Organizations increasingly need to document not just their own models, but also third-party models they incorporate into their systems.
Beyond compliance, model cards offer tangible business benefits. They reduce deployment risks by ensuring all stakeholders understand model limitations. They facilitate knowledge transfer when team members change. They build trust with customers and users. And they provide valuable context that can help debug issues when models behave unexpectedly.
The Core Principles of Responsible Documentation
Before diving into the template, it's essential to understand the guiding principles behind effective model documentation. These principles, distilled from industry best practices and ethical guidelines, should inform every aspect of your documentation process:
1. Transparency Over Perfection
Documentation doesn't need to be perfect—it needs to be honest and complete. It's better to acknowledge uncertainties and limitations than to present an overly polished picture that misleads users. The goal is to provide enough information for others to make informed decisions about using your model.
2. Audience Awareness
Effective documentation serves multiple audiences: technical teams who might modify or maintain the model, business stakeholders who need to understand its capabilities and limitations, end-users who interact with it, and regulators who need compliance evidence. Structure your documentation with clear sections for different audiences.
3. Actionable Information
Every piece of information in your documentation should serve a purpose. Ask yourself: How will this information help someone? Will it help them decide whether to use the model? Will it help them use it safely? Will it help them debug issues? If information doesn't serve a clear purpose, consider whether it belongs in your documentation.
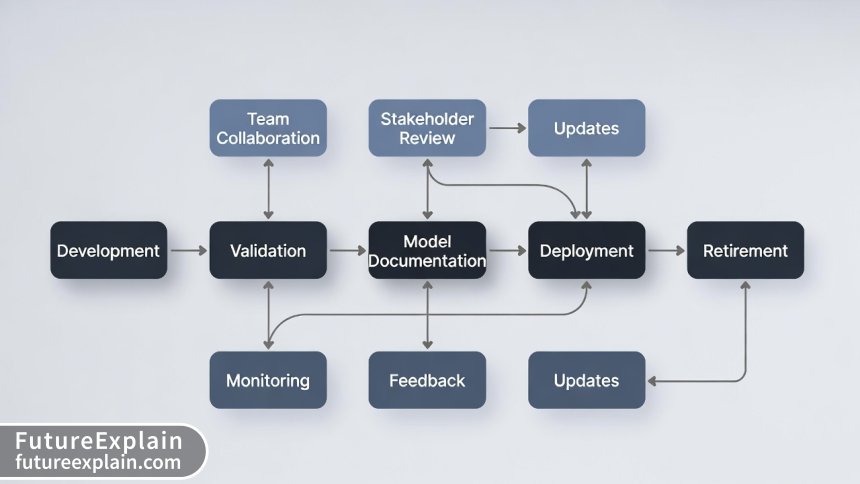
4. Living Documentation
Model documentation should evolve alongside the model itself. When you retrain the model, update hyperparameters, or discover new limitations, your documentation should reflect these changes. Establish clear processes for documentation updates as part of your MLOps workflow.
5. Accessibility
Documentation should be accessible to people with disabilities and available in formats that work for your organization's needs. This might mean providing multiple formats (HTML, PDF, Markdown) or ensuring compatibility with screen readers.
The Complete Model Card Template
Now let's dive into the comprehensive template. This template includes 25+ sections organized into logical categories. You don't need to include every section for every model—adapt it based on your model's complexity, risk level, and use case. However, we recommend at least considering each section to ensure you haven't overlooked important information.
Section 1: Model Identification & Metadata
1.1 Model Name: A clear, descriptive name that distinguishes this model from others.
1.2 Version: Use semantic versioning (e.g., 2.1.0) or a consistent numbering scheme.
1.3 Unique Identifier: A UUID or other globally unique identifier.
1.4 Release Date: When this version was released.
1.5 Last Updated: Date of last modification.
1.6 Model Type: Classification, regression, generation, etc.
1.7 Framework & Libraries: TensorFlow 2.12, PyTorch 1.14, scikit-learn 1.3, etc.
1.8 License: How others can use the model (MIT, Apache 2.0, proprietary, etc.).
1.9 Contact Information: Who to contact with questions or issues.
1.10 Changelog Reference: Link to detailed version history.
Section 2: Intended Use & Limitations
2.1 Primary Intended Use: What the model was designed to do.
2.2 Primary Intended Users: Who should use this model (data scientists, clinicians, general public, etc.).
2.3 Out-of-Scope Uses: What the model should NOT be used for.
2.4 Known Limitations: Specific situations where the model performs poorly.
2.5 Assumptions: Conditions that must be true for the model to work as intended.
Section 3: Training Data
3.1 Dataset Name & Source: Origin of training data.
3.2 Dataset Characteristics: Size, format, collection methods.
3.3 Preprocessing Steps: How data was cleaned and prepared.
3.4 Data Splits: Train/validation/test split ratios and methodology.
3.5 Demographic & Geographic Coverage: Who and where the data represents.
3.6 Data Licenses & Constraints: Legal considerations for data use.
3.7 Data Quality Assessment: Measures of data completeness, accuracy, and bias.

Section 4: Model Details
4.1 Architecture: Technical description of model structure.
4.2 Input Specifications: Required input format, size, type.
4.3 Output Specifications: Format and interpretation of outputs.
4.4 Hyperparameters: Key configuration values used during training.
4.5 Training Procedure: How the model was trained (optimizer, loss function, epochs, etc.).
4.6 Computational Requirements: Hardware needed for training and inference.
Section 5: Performance Metrics
5.1 Evaluation Methodology: How performance was measured.
5.2 Overall Performance: Aggregate metrics (accuracy, F1-score, RMSE, etc.).
5.3 Subgroup Performance: Performance across different demographic groups.
5.4 Error Analysis: Patterns in where and why the model makes mistakes.
5.5 Confidence Calibration: How well confidence scores reflect actual accuracy.
5.6 Benchmark Comparisons: How this model compares to alternatives.
Section 6: Ethical Considerations & Risks
6.1 Fairness Assessment: Analysis of bias across protected attributes.
6.2 Potential Harms: Ways the model could cause harm if misused.
6.3 Mitigation Strategies: Steps taken to reduce risks.
6.4 Environmental Impact: Carbon footprint of training and inference.
6.5 Privacy Considerations: How data privacy was protected.
Section 7: Deployment & Operations
7.1 Inference Requirements: Hardware and software needed for deployment.
7.2 Latency & Throughput: Expected performance in production.
7.3 Monitoring Plan: How model performance will be tracked over time.
7.4 Maintenance Schedule: Planned updates and retraining.
7.5 Failure Modes: What happens when the model fails.
7.6 Fallback Procedures: Backup plans for model failures.
Section 8: References & Related Materials
8.1 Research Papers: Academic literature informing the model.
8.2 Code Repository: Where to find implementation code.
8.3 Model Card Itself: Reference to this documentation.
8.4 Additional Documentation: User guides, API documentation, etc.
Step-by-Step Implementation Guide
Creating comprehensive documentation can feel overwhelming, especially for small teams. Follow this step-by-step approach to build your documentation systematically:
Phase 1: Planning (Before Development)
Week 1-2: Identify stakeholders and documentation requirements. Determine which template sections are mandatory for your use case. Assign documentation responsibilities to team members. Set up documentation templates in your preferred format (Markdown, Google Docs, Confluence, etc.).
Key Question: Who needs to use this documentation and for what purposes?
Phase 2: Development Documentation (During Model Building)
Ongoing: Document design decisions, data sources, and preprocessing steps as you work. Use tools like Weights & Biases, MLflow, or custom scripts to automatically capture hyperparameters and training metrics. Create preliminary versions of Sections 1-4 as information becomes available.
Key Question: What design choices might affect model behavior or performance?
Phase 3: Evaluation Documentation (After Training)
Week 3-4: Conduct comprehensive evaluation across multiple metrics and subgroups. Document performance results thoroughly, including edge cases and failure modes. Complete Sections 5-6 with detailed analysis. Involve domain experts in reviewing limitations and potential harms.
Key Question: How does the model perform in realistic scenarios, especially for vulnerable populations?
Phase 4: Deployment Documentation (Before Production)
Week 5: Document deployment requirements, monitoring plans, and operational procedures. Complete Section 7 with input from DevOps and infrastructure teams. Create user-facing documentation that explains appropriate use and limitations.
Key Question: What do different teams need to know to deploy and maintain this model safely?
Phase 5: Maintenance & Updates (Ongoing)
Continuous: Establish processes for updating documentation when the model changes. Schedule regular reviews to ensure documentation remains accurate. Track documentation changes alongside model versions.
Key Question: How do we ensure documentation stays synchronized with the actual model behavior?
Real-World Examples Across Industries
Let's examine how different industries approach model documentation, adapting the template to their specific needs:
Healthcare: Diagnostic Assistant Model
A model that assists radiologists in detecting lung nodules from X-rays requires particularly thorough documentation. The model card includes detailed information about the training data (source hospitals, patient demographics, image quality), extensive validation across different patient populations, clear limitations (cannot detect nodules smaller than 5mm), and specific instructions for human-in-the-loop review. Compliance documentation references FDA guidelines for medical AI devices.
Finance: Credit Scoring Model
Documentation focuses on fairness across protected attributes (race, gender, age), with detailed subgroup analysis showing performance differences. The card explains how the model complies with regulations like the Equal Credit Opportunity Act. It includes specific examples of factors the model considers and clear explanations of how applicants can improve their scores.
E-commerce: Product Recommendation Model
Documentation emphasizes transparency about how recommendations are generated, including factors like purchase history, browsing behavior, and similarity to other users. The card discusses measures to avoid filter bubbles and ensure diverse product exposure. Performance metrics include business outcomes (conversion rate, average order value) alongside accuracy metrics.
Content Moderation: Hate Speech Detection
Given the subjective nature of content moderation, documentation thoroughly explains labeling guidelines, annotator training, and disagreement rates. The card includes extensive examples of edge cases and how they're handled. Performance metrics show precision and recall across different types of hate speech and across demographic groups targeted by hate speech.
Advanced Considerations for 2025
As AI technology evolves, documentation practices must adapt. Here are key considerations for modern AI systems:
Foundation Models and LLMs
Documenting large language models presents unique challenges. Beyond traditional metrics, you need to document capabilities across different tasks, potential for harmful outputs, content moderation approach, fine-tuning process (if applicable), and cost of inference. Special sections might cover prompt engineering guidelines, temperature settings, and strategies for reducing hallucinations.
Multimodal Models
Models that process multiple data types (text, image, audio) require documentation for each modality. Document the architecture for handling different inputs, performance on cross-modal tasks, and limitations specific to each modality. Include examples showing how the model handles different input combinations.
Edge Deployment
Models deployed on edge devices (phones, IoT devices) need documentation covering hardware constraints, offline capabilities, update mechanisms, and privacy considerations for on-device processing. Include benchmarking results for different hardware configurations and battery impact assessments.
Continuous Learning Systems
Models that learn from new data in production require documentation of the update process, data quality checks for new training data, versioning strategy, and rollback procedures. Clearly document what triggers retraining and how model drift is monitored.
Compliance Checklist for Major Regulations
Use this checklist to ensure your documentation meets regulatory requirements:
EU AI Act (High-Risk Systems)
- ✓ Technical documentation including system description, development process, and monitoring functionality
- ✓ Risk management system documentation
- ✓ Data governance documentation showing training, validation, and testing data
- ✓ Transparency information for users
- ✓ Human oversight measures documentation
- ✓ Accuracy, robustness, and cybersecurity documentation
- ✓ Quality management system documentation
US AI Executive Order (Federal Agencies)
- ✓ Impact assessments for rights-affecting systems
- ✓ Testing and evaluation results
- ✓ Mitigation of algorithmic discrimination
- ✓ Public notice for automated systems
- ✓ Opt-out mechanisms documentation
- ✓ Periodic review documentation
Industry-Specific Regulations
- Healthcare (FDA): Clinical validation documentation, software as medical device (SaMD) classification
- Finance (Various): Model validation documentation, fair lending analysis, model risk management (MRM) framework
- Automotive (ISO 21448): Safety of the intended functionality (SOTIF) documentation
Common Pitfalls and How to Avoid Them
Even with good intentions, teams often make these documentation mistakes:
Pitfall 1: Documentation as Afterthought
Problem: Creating documentation at the end of development leads to incomplete or inaccurate information.
Solution: Integrate documentation into your development workflow from day one. Use templates that team members fill incrementally as they work.
Pitfall 2: Overly Technical Language
Problem: Documentation written only for technical audiences excludes business stakeholders and users.
Solution: Create layered documentation with executive summaries, user guides, and technical details. Use clear language and avoid unnecessary jargon.
Pitfall 3: Static Documentation
Problem: Documentation created once and never updated becomes misleading as the model evolves.
Solution: Treat documentation as code—version it, review changes, and establish update triggers tied to model changes.
Pitfall 4: Missing Context
Problem: Documentation that lists metrics without explaining what they mean or why they matter.
Solution: Always include interpretation guidelines. Explain what "good" performance looks like for your use case and what metrics are most important.
Pitfall 5: Ignoring Negative Results
Problem: Focusing only on what the model does well, hiding limitations and failures.
Solution: Dedicate substantial space to limitations, failure modes, and edge cases. These are often the most valuable parts of your documentation.
Tools and Automation Strategies
While documentation requires human judgment, several tools can streamline the process:
Documentation Generation Tools
- Model Card Toolkit (Google): Automates parts of model card creation from ML metadata
- Weights & Biases: Tracks experiments and can generate documentation reports
- MLflow: Manages model lifecycle including documentation
- DVC: Version control for models and data that supports documentation
Template Management
- Store templates as Markdown files in your code repository
- Use tools like Cookiecutter to generate project scaffolding with documentation templates
- Integrate documentation checks into CI/CD pipelines
Automation Opportunities
- Automatically capture hyperparameters and training metrics
- Generate performance visualizations from evaluation results
- Create documentation diffs when models are updated
- Automate compliance checklist verification
Building a Documentation Culture
The most comprehensive template is useless without a culture that values documentation. Here's how to build that culture:
Leadership Buy-in
Frame documentation as risk management, not bureaucracy. Calculate the cost of undocumented model failures versus the cost of documentation. Share examples where good documentation prevented problems or bad documentation caused them.
Integration with Workflows
Make documentation the path of least resistance. Integrate templates into development environments. Set up automated reminders and checks. Include documentation quality in code reviews and model validation processes.
Training and Resources
Train team members on documentation best practices. Create quick reference guides and examples. Designate documentation champions on each team. Celebrate good documentation with recognition and rewards.
Continuous Improvement
Regularly review and update your documentation processes. Solicit feedback from documentation users. Analyze which parts of documentation are most and least used. Adapt your approach based on what works for your organization.
The Future of Model Documentation
Looking ahead to 2026 and beyond, we can expect several trends in model documentation:
Standardization and Interoperability
Expect more industry standards for documentation formats, similar to Software Bill of Materials (SBOM) in cybersecurity. These standards will enable automated compliance checking and model comparison across organizations.
Dynamic Documentation
Documentation that updates automatically based on model monitoring data, showing current performance metrics and drift indicators in real-time.
Interactive Documentation
Web-based documentation that lets users explore model behavior through interactive examples, test edge cases, and visualize decision boundaries.
Blockchain Verification
Using blockchain or other immutable ledgers to verify documentation authenticity and create audit trails for model changes.
AI-Assisted Documentation
AI tools that help generate documentation, suggest improvements, identify missing information, and translate technical details for different audiences.
Getting Started Today
Don't let perfection be the enemy of progress. Start documenting your models today, even if your first attempt is imperfect. Here's a simple action plan:
- Pick one model to document first—preferably one currently in production.
- Use our template to create a first draft, focusing on the most critical sections for your use case.
- Share the draft with stakeholders and incorporate their feedback.
- Establish a process for keeping documentation updated as the model changes.
- Expand gradually to other models, refining your approach based on what you learn.
Remember: The goal isn't to create perfect documentation overnight. The goal is to start being more transparent about your AI systems, to learn from the process, and to continuously improve. Every step toward better documentation is a step toward more responsible, trustworthy AI.
Conclusion
Model cards and responsible documentation are fundamental to building AI systems that are transparent, accountable, and trustworthy. In 2025, with increasing regulatory scrutiny and public awareness, comprehensive documentation is no longer optional—it's essential for any organization deploying AI.
The template and guidance provided in this article give you a practical starting point. Remember that the most effective documentation is tailored to your specific context: your model, your users, your risks, and your regulatory environment. Use our template as a foundation, but adapt it based on what you learn through implementation.
As you develop your documentation practices, focus on creating value for all stakeholders. Good documentation should make it easier to use models correctly, identify issues quickly, maintain systems effectively, and demonstrate compliance efficiently. When documentation achieves these goals, it becomes not just a compliance requirement, but a competitive advantage.
The journey toward responsible AI documentation is ongoing. Start today, iterate based on feedback, and contribute to the growing community of practice around transparent AI systems. Together, we can build AI that serves everyone better by being more understandable and accountable.
Visuals Produced by AI
Further Reading
Share
What's Your Reaction?
 Like
1427
Like
1427
 Dislike
18
Dislike
18
 Love
356
Love
356
 Funny
45
Funny
45
 Angry
9
Angry
9
 Sad
5
Sad
5
 Wow
267
Wow
267
















Following up on my earlier question about tools: We implemented a combination of MLflow and custom scripts based on your suggestions. Working much better now. Thanks!
We've shared this with our entire AI team. The compliance checklist helped us identify gaps in our existing documentation that could have been problematic during our upcoming audit.
This article should be required reading for anyone deploying AI systems. The template alone is worth bookmarking.
Final thought: The most resistance we faced was from engineers who saw documentation as "extra work." Framing it as risk mitigation and quality improvement changed minds.
The hierarchical approach for ensemble models (suggested in earlier comments) worked perfectly for our fraud detection system. Thanks for the guidance!
We're three weeks into using this template across 5 models. The consistency makes it much easier to compare models and make informed decisions about which to use for new projects.