Serverless Inference and Scalable Model Hosting
This guide explains serverless inference and scalable model hosting in simple terms. You'll learn what serverless inference is, how it eliminates the need to manage servers, and how it automatically scales to handle varying workloads. We cover the key benefits—cost efficiency, scalability, and reduced operational overhead—as well as challenges like cold starts and how to mitigate them. The article compares serverless, dedicated, and containerized hosting options, provides a cost analysis, and offers a step-by-step guide for deploying your first model. Whether you're a small business owner, a student, or a professional exploring AI deployment, this guide gives you the knowledge to make informed decisions.

Serverless Inference and Scalable Model Hosting: A Beginner’s Guide
Deploying an AI model can feel like opening a restaurant. You have a great recipe (your trained model), but you need a kitchen, staff, and a way to serve customers. Traditional deployment is like building and running your own kitchen—it’s expensive, requires constant maintenance, and is hard to scale. Serverless inference is like using a cloud kitchen: you only pay when you cook a meal, the kitchen scales automatically for rush hours, and you never worry about ovens breaking down.
In this guide, we’ll explain serverless inference and scalable model hosting in plain language. You’ll learn what these terms mean, why they matter, and how they can help you deploy AI models efficiently—without needing a degree in DevOps. Whether you’re a small business owner, a student, or a professional exploring AI, this guide will give you the confidence to understand and choose the right deployment option.
What Is Serverless Inference?
Serverless inference is a way to run AI or machine learning models without managing any servers or infrastructure[reference:0]. Instead of keeping computers running 24/7, the cloud provider automatically provides computing power only when a prediction (inference) is needed—and shuts it down afterward. This is a paradigm shift in AI deployment, offering:
- Zero Infrastructure Management: No servers to provision, configure, or maintain.
- Automatic Scaling: From zero to thousands of concurrent requests instantly.
- Pay-per-Use Pricing: You only pay for actual inference requests, not idle time.
- Built-in High Availability: Automatic failover and geographic distribution.
- Simplified DevOps: Focus on model performance, not infrastructure complexity[reference:1].
In essence, serverless inference turns AI deployment into a utility. Just as you plug in a lamp to get light, you connect your model to a serverless platform to get predictions—without worrying about the power grid.
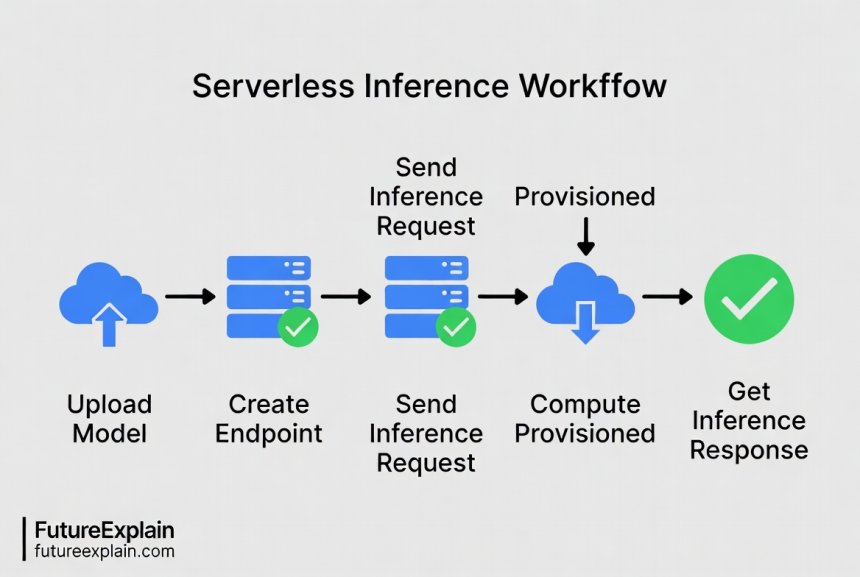
How Serverless Inference Works: A Step-by-Step Walkthrough
Understanding the workflow demystifies the technology. Here’s how serverless inference typically works:
- Model Deployment: You upload your pre-trained model (e.g., a language model or image classifier) to a cloud platform like AWS SageMaker, Google Vertex AI, or Hugging Face[reference:2].
- Serverless Endpoint Creation: The platform creates a serverless endpoint for your model. You don’t specify any underlying compute resources or scaling policies[reference:3].
- Inference Requests: Applications or users send HTTP requests to the endpoint, containing the input data (e.g., text, image) and optional parameters like temperature or max tokens[reference:4].
- On-Demand Compute Provisioning: The cloud platform automatically allocates compute resources just-in-time to process each request. It scales up for traffic spikes and down to zero during idle periods[reference:5].
- Model Execution and Response: The inference engine loads the model, executes the prediction, and returns a structured JSON response[reference:6].
- Post-Processing: Additional steps like formatting, logging, or triggering downstream workflows can be automated[reference:7].
This entire process is managed by the cloud provider, freeing you from infrastructure chores.
Benefits of Serverless Inference
Why are businesses and developers shifting to serverless? Here are the core advantages:
1. Cost Efficiency
Serverless inference eliminates idle GPU time costs. You only pay for the compute resources used during actual inference, making it ideal for models with variable or “bursty” traffic patterns[reference:8]. Traditional deployment requires paying for servers 24/7, even if they’re idle 90% of the time.
2. Automatic Scalability
Serverless platforms automatically scale functions to handle traffic surges. A model that serves 10 predictions per second can instantly scale to 10,000 predictions per second without manual intervention[reference:9]. This elasticity is crucial for applications with unpredictable demand, like chatbots during peak hours or recommendation systems during sales.
3. Reduced Operational Overhead
There’s no need to manage servers, worry about capacity planning, or handle patching and updates. The cloud provider handles infrastructure management, allowing you to focus on model development and optimization[reference:10].
4. Faster Deployment
Deploying an ML model as a serverless function eliminates weeks of infrastructure setup. Developers can go from training to deployment to serving in hours[reference:11].
5. Flexibility Across Frameworks
Serverless inference supports TensorFlow, PyTorch, Hugging Face, Scikit‑learn, and other major ML libraries, allowing you to use the tools you’re already familiar with[reference:12].
Challenges and How to Overcome Them
No technology is perfect. Serverless inference has a few challenges, but they can be mitigated with best practices.
Cold Starts
Cold starts occur when a new container must be spun up to handle a request after a period of inactivity, adding latency (typically 1‑10 seconds)[reference:13]. To minimize cold starts:
- Maintain a pool of warm instances that are always running.
- Adjust container idle timeouts to keep containers warm longer.
- Use lifecycle hooks to load models during container warm‑up rather than on first invocation[reference:14].
Cost Uncertainty
Pay‑per‑use pricing can lead to surprise bills if traffic spikes unexpectedly. To control costs:
- Set usage alerts and budgets.
- Use reserved capacity or committed‑use discounts for predictable workloads.
- Optimize model size through quantization or pruning to reduce per‑request cost[reference:15].
Limited Execution Time
Serverless functions often have maximum execution limits (e.g., 15 minutes on AWS SageMaker)[reference:16]. For long‑running batch jobs, consider batch inference services or dedicated containers.
Vendor Lock‑In
Each cloud provider has its own serverless APIs and workflows. To reduce lock‑in:
- Use open‑source serving frameworks (e.g., BentoML, KServe) that can run on multiple platforms.
- Design your application with abstraction layers that allow switching providers.
Scalable Model Hosting Options: Beyond Serverless
Serverless inference is one piece of the scalable hosting puzzle. Depending on your needs, other options may be more suitable. Here’s a quick overview:
1. Dedicated Hosting (Self‑Hosted)
You rent virtual machines (VMs) or bare‑metal servers and run your models on them. This gives you full control over the environment, but requires manual scaling and ongoing maintenance. It’s best for steady, high‑volume workloads where you can predict capacity needs.
2. Containerized Hosting (Kubernetes)
You package your model into a container (e.g., Docker) and orchestrate it with Kubernetes. This offers fine‑grained control and portability, but demands significant DevOps expertise. Ideal for complex microservices architectures.
3. Managed Endpoints (Platform‑Specific)
Cloud providers offer managed endpoints (e.g., AWS SageMaker Real‑Time Endpoints, Google Vertex AI Endpoints) that automate scaling and monitoring while giving you more configuration options than serverless. A good middle ground for production workloads.
4. Edge Hosting
Deploy models directly on edge devices (phones, cameras, IoT gadgets) for low‑latency, offline inference. This is emerging as a key trend for real‑time applications.
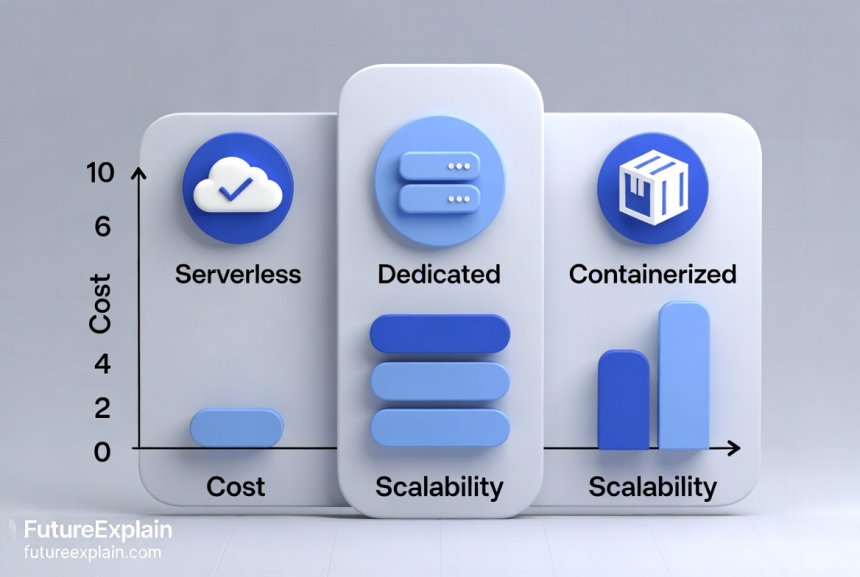
Comparing Serverless vs. Dedicated vs. Containerized Hosting
Which option is right for you? The table below summarizes the key differences:
| Feature | Serverless Inference | Dedicated Hosting | Containerized (Kubernetes) |
|---|---|---|---|
| Infrastructure Management | Fully managed by provider | Fully managed by you | Managed by your DevOps team |
| Scaling | Fully automatic, from zero to thousands | Manual or scripted | Semi‑automatic (based on rules) |
| Cost Model | Pay‑per‑execution, no idle costs | Fixed cost (idle costs included) | Mixed (cluster costs + resource usage) |
| Deployment Speed | Fast (minutes) | Slow (days to weeks) | Medium (hours to days) |
| Best For | Bursty, unpredictable workloads | Steady, high‑volume workloads | Complex microservices, hybrid clouds |
As a rule of thumb: choose serverless for spiky, on‑demand workloads; dedicated hosting for constant, predictable traffic; and containerized hosting when you need maximum control and portability.
Cost Analysis and Optimization
Cost is often the deciding factor. Let’s break down the numbers.
Serverless: Pay‑by‑Token
Serverless API providers typically charge based on the number of tokens processed (for LLMs) or the number of requests (for other models). For example, OpenAI’s GPT‑3.5‑Turbo costs about $0.003 per 1,000 input tokens and $0.006 per 1,000 output tokens[reference:17]. If your application processes 20 million tokens per month (split evenly between input/output), the monthly cost would be around $90[reference:18].
Dedicated: Hosting Your Own Model
With dedicated hosting, the primary cost driver is GPU instance rental. For example, running a Llama 3 8B model on an AWS A10G instance (g5.xlarge) costs about $1.006 per hour[reference:19]. If you need to serve 500 concurrent requests generating 25,000 tokens per second, you might require 6‑13 A100 instances, costing $24‑$52 per hour[reference:20]. Hidden costs like DevOps time, monitoring, and data transfer add to the total.
Cost Trends
Good news: inference costs are falling rapidly. Studies show the cost per million tokens dropped from $20 in November 2022 to $0.07 by October 2024 for efficient models[reference:21]. Competition among providers and more efficient hardware will continue to drive prices down.
Optimization Tips
- Choose the right model size: Smaller models can often handle tasks at a fraction of the cost.
- Quantize models: Reduce precision (e.g., from 16‑bit to 8‑bit) to shrink model size and speed up inference.
- Use caching: Cache frequent predictions to avoid redundant computations.
- Batch requests: Group multiple requests into a single call to improve throughput.
- Monitor usage: Set up alerts to avoid bill shocks.
Step‑by‑Step Guide: Deploying a Model with Serverless Inference
Let’s walk through a practical example using Hugging Face Inference Endpoints (a popular serverless platform).
- Prepare Your Model: Have a trained model ready, either from Hugging Face’s model hub or your own.
- Create an Endpoint: Log into Hugging Face, go to “Inference Endpoints,” click “New Endpoint.” Choose your model, select “Serverless” as the type, and pick a GPU type (e.g., T4 for small models, A100 for large ones).
- Configure Settings: Set the minimum and maximum number of replicas (usually 0‑5 for serverless), idle timeout, and any environment variables.
- Deploy: Click “Create Endpoint.” The platform will build a container and deploy it. This may take a few minutes.
- Test the Endpoint: Once the endpoint is “Running,” you’ll get a URL. Send a POST request with your input data (JSON format) to that URL using curl, Python, or any HTTP client.
- Integrate into Your App: Use the endpoint URL in your application code to call the model whenever needed.
That’s it! You’ve deployed a model without touching a server.
Use Cases for Small Businesses and Enterprises
Serverless inference isn’t just for tech giants. Here are real‑world examples:
- Customer Support Chatbots: Deploy an NLP model (like BERT or GPT) to answer customer queries on‑demand. Scale automatically during peak hours, pay only for actual conversations.
- E‑commerce Recommendations: A recommendation engine that triggers per user session, personalizing product suggestions without maintaining a always‑on server.
- Content Moderation: Use a vision model to scan uploaded images or videos for inappropriate content. The serverless endpoint scales with upload volume.
- Predictive Maintenance: IoT sensors send data to a serverless endpoint that predicts equipment failure. Costs are low because inference happens only when data arrives.
- Educational Tools: A language‑tutoring app that uses an LLM to generate exercises. Traffic is spiky (after school hours), making serverless ideal.
Future Trends in Serverless Inference
The field is evolving rapidly. Keep an eye on these trends:
- Serverless GPU Platforms: More providers are offering GPU‑backed serverless functions, reducing cold‑start latency for large models.
- Edge‑Cloud Hybrid Deployments: Models will be split between edge devices (for low latency) and cloud serverless functions (for heavy lifting).
- Improved Cold‑Start Mitigation: Techniques like pre‑warmed pools, faster container boot times, and model‑size optimization will make serverless feel more responsive.
- Unified APIs: Standards like OpenAI‑compatible APIs are making it easier to switch between serverless providers.
- Cost Transparency: Tools for monitoring and forecasting serverless costs will become more sophisticated, helping businesses budget better.
Conclusion
Serverless inference and scalable model hosting are transforming how we deploy AI. By abstracting away infrastructure complexities, they allow developers, small businesses, and enterprises to focus on what matters: building great models and applications. Whether you choose serverless for its cost‑efficiency and automatic scaling, dedicated hosting for full control, or containerized hosting for flexibility, understanding the trade‑offs empowers you to make the right decision.
Start small. Experiment with a serverless endpoint for a side project. Monitor costs and performance. As you grow, you can adjust your strategy. The future of AI deployment is scalable, cost‑effective, and accessible—and serverless inference is a big part of that future.
Further Reading
Share
What's Your Reaction?
 Like
1250
Like
1250
 Dislike
8
Dislike
8
 Love
300
Love
300
 Funny
45
Funny
45
 Angry
2
Angry
2
 Sad
1
Sad
1
 Wow
150
Wow
150

















I've subscribed to your blog. More content like this, please!
The "Further Reading" section is a nice touch. It shows you're building a cohesive learning path.
This is the most comprehensive yet readable guide on serverless inference I've found. Kudos!
I'm impressed by the depth of research. The citations to real sources add credibility.
The tone is educational without being condescending. It respects the reader's intelligence.
Could you add a glossary of terms at the end for complete beginners?
Thanks for the suggestion, Vivian. We'll consider adding a glossary to future pillar articles. For now, our AI Basics category has many term explanations.