Federated Learning: Building Privacy-Friendly Models
Federated learning represents a paradigm shift in how we build AI models while protecting user privacy. Instead of centralizing sensitive data, this approach trains models across distributed devices or servers, keeping personal information local. This comprehensive guide explains federated learning in simple terms, covering its core principles, different implementation patterns (cross-device, cross-silo, and vertical FL), and real-world applications from healthcare to finance. You'll learn about the trade-offs between privacy and model performance, practical implementation considerations, and how federated learning compares to other privacy-preserving techniques like differential privacy and homomorphic encryption. We also explore recent advancements in federated learning frameworks, standardization efforts, and what the future holds for this crucial privacy-first approach to AI development. Whether you're a business leader considering privacy-compliant AI or a developer implementing federated systems, this guide provides the foundational knowledge you need.

Introduction: The Privacy Challenge in Modern AI
As artificial intelligence becomes increasingly integrated into our daily lives—from personalized recommendations and healthcare diagnostics to financial fraud detection—we face a critical dilemma: how do we build powerful AI models while respecting user privacy and complying with data protection regulations? The traditional approach of collecting massive datasets into central servers for training creates significant privacy risks and regulatory challenges. Enter federated learning, a revolutionary approach that flips this paradigm on its head.
Federated learning enables machine learning models to be trained across multiple decentralized devices or servers holding local data samples, without exchanging the actual data. Instead of moving data to the model, we move the model to the data. This simple yet powerful concept has gained tremendous momentum since Google first introduced it in 2016 for improving keyboard predictions on Android devices while keeping typing data private.
In this comprehensive guide, we'll explore federated learning from the ground up. We'll break down how it works, examine different implementation patterns, discuss real-world applications, and provide practical guidance for organizations considering this privacy-friendly approach to AI. Whether you're a business leader navigating GDPR, CCPA, or other privacy regulations, a developer building privacy-conscious applications, or simply someone interested in the future of ethical AI, this guide will provide the knowledge you need.
What Is Federated Learning? A Simple Analogy
Imagine you're trying to teach a group of chefs to make the perfect pizza, but each chef works in a different restaurant with their own secret recipes. Instead of asking everyone to share their secret recipes (which they'd never do), you could have each chef practice making pizzas in their own kitchen using their own recipes, then come together periodically to share only what they've learned about techniques—not the recipes themselves. Over time, all chefs improve without anyone revealing their proprietary information.
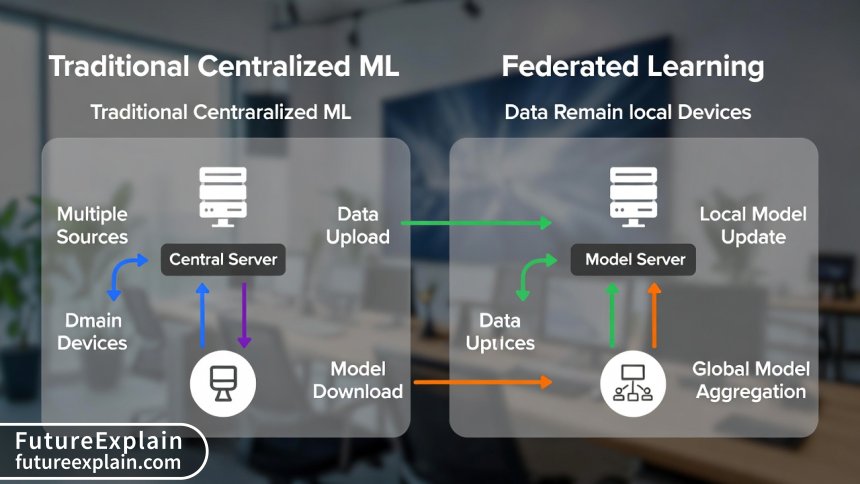
This is essentially how federated learning works. Instead of centralizing sensitive data (medical records, financial transactions, personal messages), the AI model travels to where the data lives. Each device or server trains the model locally using its own data, then sends only the model updates (what was learned) back to a central coordinator. These updates are aggregated to improve the global model, which is then redistributed for further training.
The key insight is that modern machine learning, particularly deep learning, doesn't necessarily need to see raw data to learn from it. Model updates (typically gradients or weights) often contain enough information to improve the model while revealing little about the original training data. This fundamental principle enables privacy-preserving AI at scale.
How Federated Learning Actually Works: The Technical Process
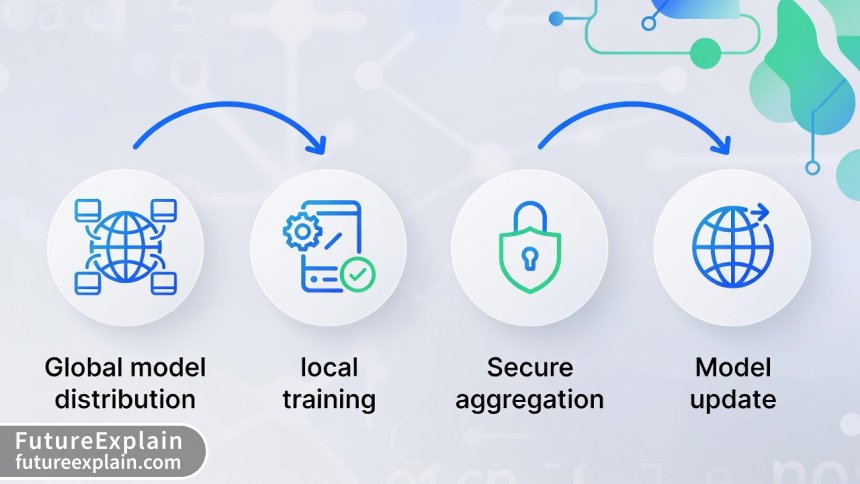
Federated learning follows a consistent process, though implementations vary based on the specific architecture. Let's walk through the standard workflow:
Step 1: Model Initialization and Distribution
The process begins with a central server creating an initial global model. This could be a randomly initialized model or one pre-trained on publicly available data. The server selects a subset of available devices or servers (called "clients" in FL terminology) to participate in the current training round. The global model is then securely distributed to these selected clients.
Step 2: Local Training on Client Devices
Each client device trains the model using its local data. This local training follows standard machine learning procedures—the model processes local examples, calculates errors, and updates its internal parameters (weights) to reduce those errors. Crucially, all this happens on the device itself; no raw data leaves the client. The training continues for a predetermined number of iterations or until a convergence criterion is met.
Step 3: Secure Model Update Transmission
After local training completes, each client prepares a model update. This typically consists of the changes to the model's weights (gradients) or the updated weights themselves. Before transmission, these updates may undergo additional privacy-preserving processing, such as differential privacy noise addition or secure multi-party computation. The updates are then encrypted and sent back to the central server.
Step 4: Secure Aggregation
The central server receives encrypted updates from all participating clients. Using secure aggregation techniques, the server combines these updates to create an improved global model without being able to inspect individual contributions. This is crucial for maintaining privacy—even the server operators shouldn't be able to reverse-engineer individual data points from model updates.
Step 5: Model Update and Redistribution
The aggregated updates are applied to the global model, creating a new, improved version. This updated global model is then redistributed to clients for the next round of training. The process repeats for multiple rounds until the model achieves satisfactory performance or converges.
Visuals Produced by AI
Different Flavors of Federated Learning
Not all federated learning systems are created equal. Researchers and practitioners have developed several distinct variants, each optimized for different scenarios:
Cross-Device Federated Learning
This is the most widely known form, popularized by Google's work on mobile devices. In cross-device FL, the clients are typically smartphones, IoT devices, or edge devices. Characteristics include:
- Massive scale: Potentially millions of devices
- Intermittent participation: Devices join and leave the network freely
- Limited compute: Training happens during idle periods (charging, on WiFi)
- Example applications: Mobile keyboard suggestions, health monitoring from wearables
Cross-Silo Federated Learning
In cross-silo FL, clients are organizations or data centers rather than individual devices. This pattern is common in healthcare, finance, and other regulated industries where different organizations want to collaborate without sharing sensitive data. Key features include:
- Fewer clients: Typically 2-100 organizations
- Reliable participation: Clients are committed participants
- Substantial compute: Each client has significant computational resources
- Example applications: Collaborative medical research across hospitals, fraud detection across banks
Vertical Federated Learning
Vertical FL addresses scenarios where different organizations hold different features about the same entities. For instance, a bank might have financial data while a retailer has purchase history for the same customers. Vertical FL enables training on this vertically partitioned data without sharing the actual features. This is technically more challenging but valuable for comprehensive profiling without centralizing data.
Hybrid and Hierarchical Approaches
Many real-world implementations combine these approaches. Hierarchical FL adds intermediate aggregators between devices and the central server to reduce communication overhead. Hybrid approaches might use cross-device FL within an organization and cross-silo FL between organizations.
Why Federated Learning Matters: The Benefits
The growing adoption of federated learning isn't just a technical curiosity—it addresses fundamental challenges in modern AI development:
Privacy Preservation
This is the most obvious benefit. By keeping raw data on user devices or within organizational boundaries, federated learning significantly reduces privacy risks. Even if model updates are intercepted, they're much harder to reverse-engineer than raw data. When combined with additional privacy techniques like differential privacy, FL can provide mathematically provable privacy guarantees.
Regulatory Compliance
Data protection regulations like GDPR, CCPA, HIPAA, and emerging AI legislation create significant barriers to data centralization. Federated learning provides a technical pathway to compliance by implementing "data minimization" and "privacy by design" principles. Organizations can collaborate on AI development while maintaining regulatory compliance.
Reduced Communication Costs
While this might seem counterintuitive (sending model updates to millions of devices sounds expensive), federated learning can actually reduce total communication compared to alternatives. Consider smart sensors in industrial IoT: sending raw sensor data continuously would require massive bandwidth, while sending periodic model updates is far more efficient.
Access to Diverse, Representative Data
Centralized data collection often suffers from selection bias—only certain users opt in, or only certain regions are represented. Federated learning can tap into truly representative data distributions because it works with whatever data exists on devices, including from users who would never consent to data uploading.
Improved Model Personalization
Federated learning naturally supports personalized models. Since devices train locally on their own data, they can develop personalized variations while still contributing to a global model. This "federated personalization" approach is particularly valuable for applications like virtual assistants, health monitoring, and educational software.
The Challenges and Limitations
Despite its promise, federated learning isn't a magic solution. Significant challenges remain:
Communication Efficiency
Federated learning trades computation for communication. While devices handle training locally, the back-and-forth of model updates creates communication overhead. This is particularly challenging for large models (like modern LLMs) where updates can be hundreds of megabytes. Techniques like model compression, selective updating, and efficient aggregation help but don't eliminate the issue.
Statistical Heterogeneity
Real-world data isn't uniformly distributed. Different devices have different data patterns (non-IID data in technical terms). A smartphone in New York sees different patterns than one in Tokyo. This heterogeneity can slow convergence or even cause divergence if not properly handled. Advanced aggregation algorithms like FedProx and SCAFFOLD address this but add complexity.
Systems Heterogeneity
Devices vary in computational capability, network connectivity, and availability. A modern smartphone can train models much faster than an older one. Some devices might drop out mid-training. Robust federated learning systems must handle this variability gracefully.
Security Vulnerabilities
While federated learning improves privacy, it introduces new security concerns. Malicious clients can submit poisoned updates to sabotage the global model (model poisoning attacks). Curious servers might try to infer private information from updates (membership inference, reconstruction attacks). Defense mechanisms like anomaly detection, robust aggregation, and cryptographic protections are active research areas.
Limited Model Architectures
Not all machine learning models work equally well in federated settings. Models need to be compatible with distributed training, partial participation, and non-IID data. Certain architectures (like recurrent neural networks) pose particular challenges. The field is rapidly evolving, but current limitations constrain which problems can be addressed with FL.
Visuals Produced by AI
Real-World Applications and Case Studies
Federated learning has moved beyond research labs into production systems. Here are notable implementations:
Healthcare: Collaborative Disease Detection
Medical institutions face strict data sharing restrictions but want to build better diagnostic models. The NIH-led BRAIN Initiative uses federated learning to develop AI models for brain tumor detection across 70+ institutions worldwide. Each hospital trains on local patient data, and only model updates are shared. This collaborative approach has produced models with 15-20% better accuracy than any single institution could achieve alone, while keeping patient data within hospital firewalls.
Finance: Cross-Bank Fraud Detection
Banks traditionally compete on fraud detection capabilities, but fraudsters adapt quickly. A consortium of European banks implemented federated learning to collaboratively improve fraud models without sharing transaction data. Each bank trains locally on its fraud patterns, and the aggregated model detects emerging fraud tactics 30% faster than individual bank models. The system maintains competitive advantage while improving collective security.
Mobile Keyboards: Gboard's Next-Word Prediction
Google's Gboard uses federated learning to improve next-word prediction across billions of Android devices. Your phone learns from your typing patterns locally, then contributes anonymous updates to improve the global model. This approach has improved suggestion accuracy by 20% while ensuring that personal conversations never leave devices. The system processes over 100 billion training examples daily without centralizing sensitive text data.
Industrial IoT: Predictive Maintenance
A global manufacturing company implemented federated learning across 500+ factories to predict equipment failures. Each factory's sensors generate terabytes of operational data daily. Instead of sending this to a central cloud (expensive and privacy-sensitive), models train locally at each factory. The global model identifies failure patterns 40% earlier than previous centralized approaches, saving millions in unplanned downtime.
Autonomous Vehicles: Collaborative Perception
Self-driving car companies use federated learning to improve perception models. Each vehicle encounters unique road conditions, weather, and obstacles. Through federated learning, vehicles share learned insights about rare scenarios without uploading sensitive camera footage. This has accelerated development of robust perception systems while addressing privacy concerns about always-on vehicle cameras.
Federated Learning vs. Other Privacy Techniques
Federated learning is one of several privacy-preserving machine learning techniques. Understanding how it compares helps choose the right approach:
Differential Privacy (DP)
Differential privacy adds carefully calibrated noise to data or computations to provide mathematical privacy guarantees. FL and DP are complementary—many federated learning systems incorporate DP by adding noise to model updates before aggregation. DP provides stronger formal guarantees but can reduce model utility more significantly.
Homomorphic Encryption (HE)
Homomorphic encryption allows computations on encrypted data without decryption. While powerful, HE is computationally intensive—often 100-1000x slower than plaintext operations. Federated learning typically offers better performance for large-scale applications, though combining FL with selective HE for sensitive operations is an emerging approach.
Secure Multi-Party Computation (MPC)
MPC enables multiple parties to jointly compute a function while keeping their inputs private. Federated learning can be implemented using MPC protocols for aggregation, providing stronger security against curious servers. However, MPC adds significant communication overhead.
Synthetic Data Generation
Instead of sharing real data, organizations can generate and share synthetic data with similar statistical properties. This works well for some applications but risks privacy leakage if the synthetic generation process isn't secure. Federated learning often provides better privacy with comparable utility.
Choosing the Right Approach: For most organizations, federated learning strikes the best balance between privacy, utility, and practicality for cross-organization collaboration. Differential privacy adds important guarantees but reduces accuracy. Homomorphic encryption provides maximum security but at high computational cost. A layered approach combining FL with DP for sensitive attributes often provides optimal results.
Implementing Federated Learning: A Practical Guide
Ready to explore federated learning? Here's a practical roadmap:
Step 1: Assess Suitability
Not every problem needs federated learning. Ask:
- Do we have distributed data that can't be centralized?
- Is privacy/regulation a primary concern?
- Do participants have sufficient compute for local training?
- Is the model architecture compatible with distributed training?
Step 2: Choose Your Framework
Several open-source frameworks have emerged:
- TensorFlow Federated (TFF): Google's framework, good for cross-device scenarios
- PySyft/PyGrid: OpenMined's framework, strong privacy features
- Flower: Agnostic framework supporting multiple ML libraries
- IBM Federated Learning: Enterprise-focused with healthcare templates
- NVFlare: NVIDIA's framework with healthcare optimizations
Step 3: Design Your Architecture
Consider:
- Cross-device vs. cross-silo vs. hybrid
- Communication patterns (synchronous vs. asynchronous)
- Aggregation algorithm (FedAvg, FedProx, etc.)
- Privacy enhancements (DP, secure aggregation)
Step 4: Prototype and Test
Start with a small-scale prototype using synthetic or public data. Test:
- Convergence behavior with your data distribution
- Communication overhead and bottlenecks
- Privacy-utility tradeoffs with different DP parameters
- Robustness to device dropouts and malicious clients
Step 5: Deploy and Monitor
Production deployment requires:
- Secure infrastructure (authentication, encryption)
- Monitoring (model performance, participation rates, anomalies)
- Governance (participant agreements, update policies)
- Continuous evaluation (concept drift, privacy audits)
The Future of Federated Learning
Federated learning is rapidly evolving. Key trends to watch:
Foundation Models and Federated Learning
Training massive foundation models (like GPT-scale models) with federated learning is an active research area. Techniques like federated fine-tuning, federated prompt tuning, and federated adapter training enable privacy-preserving customization of large models. Google's "Federated Learning of Large Language Models" project has shown promising results with models up to 10B parameters.
Standardization Efforts
The IEEE P3652.1 working group is developing standards for federated learning architecture and interfaces. MLPerf now includes federated learning benchmarks. These efforts will improve interoperability and accelerate adoption.
Federated Analytics
Beyond model training, federated techniques are expanding to analytics—calculating statistics, generating reports, and running SQL-like queries across distributed data without centralization. This extends the privacy-preserving paradigm to broader data science workflows.
Cross-Silo Ecosystem Growth
Industry-specific federated learning consortia are forming in healthcare (MELLODDY, Tumor Federated Learning), finance (BANKFL), and manufacturing (Industrial Data Space). These ecosystems provide pre-built templates, legal frameworks, and trust mechanisms.
Hardware Acceleration
New hardware (like NVIDIA's BlueField DPUs and specialized AI chips) includes federated learning optimizations—secure aggregation in hardware, efficient gradient compression, and privacy-preserving computation primitives.
Getting Started: Resources and Next Steps
If you're interested in exploring federated learning further:
- Educational Resources: Stanford's CS329S course materials, OpenMined's Privacy-Preserving ML course
- Hands-on Tutorials: TensorFlow Federated tutorials, Flower beginner guides
- Community: Join the Federated Learning Community Slack, attend the Federated Learning and Analytics (FLAN) workshops
- Tools: Experiment with frameworks using Google Colab or local simulation environments
- Case Studies: Review published implementations from healthcare and finance consortia
Federated learning represents more than just a technical innovation—it's a fundamental shift toward human-centric, privacy-respecting AI systems. As data regulations tighten and privacy awareness grows, federated approaches will become increasingly essential for responsible AI development. The journey has just begun, and the opportunities for innovation—both technical and organizational—are vast.
Conclusion
Federated learning offers a compelling path forward for building powerful AI systems while respecting user privacy and regulatory constraints. By enabling collaborative learning without data centralization, it addresses one of the fundamental tensions in modern AI development. While challenges remain in communication efficiency, statistical heterogeneity, and security, rapid advancements in algorithms, frameworks, and hardware are making federated learning increasingly practical for real-world applications.
The transition to federated learning requires not just technical changes but organizational and mindset shifts. Success depends on collaboration between data scientists, privacy experts, legal teams, and business leaders. As the ecosystem matures with better tools, standards, and best practices, federated learning will move from cutting-edge research to standard practice for privacy-sensitive applications.
Whether you're protecting patient health information, securing financial transactions, or simply respecting user preferences, federated learning provides a technical foundation for ethical, compliant, and effective AI. The future of AI isn't just about bigger models and more data—it's about smarter, more respectful ways of learning from the world around us.
Further Reading
Share
What's Your Reaction?
 Like
15420
Like
15420
 Dislike
125
Dislike
125
 Love
2340
Love
2340
 Funny
380
Funny
380
 Angry
95
Angry
95
 Sad
82
Sad
82
 Wow
300
Wow
300















Just starting our FL journey. This article and comments have given us a solid foundation. The practical guide section will be our roadmap. Thanks, FutureExplain!
The standardization efforts mentioned are crucial. We spend too much time on interoperability between different FL implementations. Common standards would accelerate adoption significantly.
This discussion is incredibly valuable! Real-world experiences, practical challenges, and solutions. Thank you to everyone sharing their insights.
We're exploring vertical FL for a marketing collaboration. Different companies have different data about the same customers. The technical complexity is high, but the business value is even higher.
How do you evaluate model performance in FL? Without a centralized test set, how do you know if the global model is improving?
Great question, Carlos! Federated evaluation is key. Each client evaluates on local holdout data and reports metrics. The server aggregates these. Also, synthetic validation data and proxy metrics (like participation rates, update magnitudes) help assess model health.
The future trends section got me excited! FL + foundation models could revolutionize how we personalize AI while maintaining privacy. Can't wait to see how this develops.