Text-to-Speech & Voice Cloning: Best Tools and Ethics
This comprehensive guide explores the evolving landscape of text-to-speech and voice cloning technologies in 2025. We examine the most advanced tools available for businesses, creators, and developers, from enterprise solutions like Google Cloud Text-to-Speech and Amazon Polly to emerging voice cloning platforms. More importantly, we provide a practical ethical framework for responsible implementation, covering consent, disclosure, detection, and regulatory compliance. The article includes comparison matrices, implementation checklists, and real-world use cases that balance technological capability with ethical responsibility. Whether you're looking to enhance accessibility, create content, or develop voice-enabled applications, this guide helps you navigate both the technical possibilities and moral implications of synthetic voice technology.

In 2025, synthetic voice technology has reached a critical inflection point. What began as robotic text-to-speech systems has evolved into remarkably human-like voice synthesis and cloning capabilities that blur the line between artificial and human expression. This transformation brings unprecedented opportunities for accessibility, creativity, and business efficiency—but also introduces complex ethical challenges that demand our careful attention.
This comprehensive guide explores the current state of text-to-speech (TTS) and voice cloning technologies, providing both practical tool recommendations and essential ethical frameworks. Whether you're a content creator seeking to enhance your workflow, a business leader exploring voice-enabled applications, or simply curious about this rapidly evolving field, you'll find actionable insights for navigating the 2025 synthetic voice landscape responsibly.
The Evolution of Synthetic Voice Technology
The journey from early speech synthesis to today's sophisticated voice cloning reflects decades of technological advancement. Early text-to-speech systems, like the 1960s-era IBM Shoebox, produced robotic, mechanical speech that was functional but far from natural. The breakthrough came with concatenative synthesis in the 1990s, which stitched together pre-recorded speech segments. However, the real revolution began with the application of deep learning around 2016, leading to neural TTS systems that could generate fluid, expressive speech.
Today's most advanced systems use transformer architectures and diffusion models that analyze thousands of hours of human speech to learn the subtle patterns of natural expression. These systems don't just convert text to speech—they understand context, emotion, and linguistic nuance. The latest models from companies like Google DeepMind and OpenAI can generate speech with breathing patterns, emotional inflections, and even subtle mouth sounds that make synthetic voices indistinguishable from human ones in many contexts.
Voice cloning represents the next frontier: the ability to capture someone's unique vocal characteristics and generate new speech in their voice with just a few seconds of sample audio. This technology builds on the same neural architectures but adds speaker encoding layers that extract voiceprints—mathematical representations of vocal characteristics like timbre, pitch, and speaking style.
Current Text-to-Speech Landscape in 2025
The TTS market in 2025 is characterized by increasing specialization and accessibility. Major cloud providers offer enterprise-grade solutions, while specialized startups target specific niches like gaming, education, and content creation. Understanding this landscape requires examining tools across several categories.
Enterprise-Grade Cloud TTS Services
For businesses requiring reliability, scalability, and extensive language support, cloud-based TTS services remain the dominant choice. These platforms typically offer API access with pay-per-use pricing and extensive documentation.
Google Cloud Text-to-Speech leads in language diversity with over 380 voices across 90+ languages and variants. Their 2025 WaveNet voices incorporate emotional controls (happiness, sadness, excitement) and speaking style adjustments. The service integrates seamlessly with other Google Cloud AI services and offers custom voice creation for enterprises needing brand-specific voices.
Amazon Polly distinguishes itself with its Neural TTS technology that delivers especially natural-sounding speech in multiple languages. Amazon's 2025 innovations include real-time voice transformation (changing age, gender, or accent characteristics) and enhanced expressiveness controls. Their "Brand Voice" program allows companies to create custom neural voices trained on their specific requirements.
Microsoft Azure Text to Speech excels in customization and accessibility features. Their 2025 offering includes improved neural voices with fine-grained control over speaking rate, pitch, and volume. Microsoft's standout feature is its commitment to inclusive design, with voices specifically optimized for screen readers and learning applications.
IBM Watson Text to Speech maintains a strong position in regulated industries with its focus on data privacy and on-premise deployment options. Their 2025 updates emphasize multilingual voice consistency—ensuring the same "voice persona" sounds natural across different languages rather than switching to completely different voice actors.
Specialized TTS Platforms
Beyond the major cloud providers, several platforms have carved out specific niches with tailored feature sets:
- ElevenLabs has emerged as the leader in expressive, conversational TTS with minimal data requirements. Their 2025 "Contextual TTS" technology analyzes surrounding text to determine appropriate emotional delivery, making it particularly popular with audiobook publishers and game developers.
- Resemble AI focuses on real-time voice cloning and generation, offering both TTS and voice conversion tools. Their 2025 platform includes "Voice Integrity" features that add imperceptible audio watermarks to detect synthetic content.
- Murf AI targets content creators with an all-in-one studio combining TTS, video synchronization, and background music. Their 2025 "Voice Choreography" tool allows precise timing control for multimedia projects.
- Play.ht serves the podcasting and e-learning markets with extensive voice libraries and natural pauses/emphasis controls. Their 2025 "Learning Voices" are specifically tuned for educational content retention.
Open Source and Research-Focused Tools
The open-source community continues to drive innovation in TTS technology, with several notable projects gaining traction in 2025:
- Coqui TTS provides a complete open-source toolkit for training and deploying neural TTS models. The 2025 release includes pre-trained models for 30+ languages and tools for fine-tuning with limited data.
- Tortoise-TTS specializes in highly realistic, expressive speech generation with exceptional prosody control. While computationally intensive, it produces some of the most natural-sounding speech available in open source.
- StyleTTS 2 introduces style transfer capabilities, allowing users to apply the speaking style from one audio sample to generated speech. This enables more diverse expression without retraining models.
Voice Cloning Technology in 2025
Voice cloning has progressed from requiring hours of training data to just seconds, making it both more accessible and potentially more dangerous. The 2025 landscape reflects this tension between capability and responsibility.
Commercial Voice Cloning Platforms
Commercial platforms balance ease of use with varying levels of ethical safeguards:
Descript Overdub pioneered consumer-friendly voice cloning for content creators, and their 2025 "Consent-First Cloning" requires explicit permission verification before voice creation. The platform integrates cloning directly into their audio/video editing workflow.
Respeecher focuses on high-quality voice conversion for film, gaming, and accessibility applications. Their 2025 "Ethical Source" verification ensures all training data comes from properly consented sources, with blockchain-based consent records.
iSpeech offers voice cloning as part of their broader TTS services, with particular strength in maintaining voice consistency across long-form content. Their 2025 innovation is "Aging Simulation"—adjusting a cloned voice to sound appropriately older or younger for continuity in long-running projects.
Sonantic (acquired by Spotify) specializes in emotional voice generation for gaming and interactive media. Their 2025 platform includes real-time emotion adjustment during voice generation, allowing dynamic responses in interactive applications.
Research-Driven Voice Cloning
Academic and research institutions continue pushing the boundaries of what's possible while increasingly focusing on safety:
OpenAI's Voice Engine, released with significant restrictions in 2024, represents the state-of-the-art in few-shot voice cloning. Their 2025 implementation includes mandatory audio watermarking and usage restrictions that prevent impersonation without consent.
Meta's Voicebox demonstrates impressive multilingual voice cloning capabilities but remains a research project with no public API. Their 2025 research focuses on detection methods and consent verification systems.
Google's VALL-E research shows remarkable few-shot cloning abilities but has not been released publicly due to ethical concerns. Google's 2025 publications emphasize "voice authentication" techniques that could distinguish cloned from genuine speech.
Ethical Framework for Synthetic Voice Technology
The power to replicate human voices comes with profound ethical responsibilities. In 2025, these concerns have moved from theoretical discussions to practical implementation challenges. A comprehensive ethical framework should address consent, disclosure, detection, and harm prevention.
Consent and Authorization
Consent forms the foundation of ethical voice cloning. Effective consent must be:
- Informed: Individuals must understand exactly how their voice will be used, stored, and potentially modified
- Specific: Consent should cover particular use cases rather than blanket permission
- Revocable: Individuals should be able to withdraw consent and have their voice data deleted
- Compensated (when commercial): Fair compensation for voice talent, especially for commercial applications
Emerging best practices in 2025 include "dynamic consent" systems that allow voice contributors to adjust permissions over time and blockchain-based consent ledgers that create immutable records of permission grants.
Disclosure and Transparency
When audiences encounter synthetic voices, they deserve to know what they're hearing. Disclosure practices vary by context:
- Entertainment and fiction: Clear credits indicating voice synthesis or cloning
- Educational content: Disclosure at point of use, especially when synthetic voices represent real historical figures
- Customer service and assistants: Initial disclosure that the voice is synthetic, with option to transfer to human
- Accessibility applications: Clear labeling but with consideration for user experience
The 2025 standard increasingly includes both human-readable disclosures and machine-readable metadata (like the C2PA standard for content provenance) that travels with audio files.
Preventing Harm and Misuse
Synthetic voice technology creates several categories of potential harm that responsible practitioners must address:
Impersonation and fraud: Voice cloning can facilitate convincing social engineering attacks. Responsible platforms implement verification requirements and usage monitoring. Some jurisdictions now require "liveness detection" (proving the speaker is physically present) for sensitive voice transactions.
Non-consensual intimate content: Creating synthetic voices for harassment or exploitation represents a severe misuse. Platform safeguards include content moderation, reporting mechanisms, and collaboration with law enforcement.
Cultural appropriation and representation: Creating synthetic versions of voices from marginalized communities without proper consultation can perpetuate harm. Ethical guidelines increasingly recommend community review processes for such projects.
Psychological impact: Hearing a loved one's cloned voice after their death, or being unable to trust audio evidence, creates novel psychological challenges. Responsible deployment considers these human factors.
Technical Safeguards and Detection Methods
As synthetic voices improve, detection becomes more challenging but remains essential. The 2025 detection landscape includes several complementary approaches:
Active Watermarking
Watermarking embeds imperceptible signals into synthetic audio that can be detected with specialized tools. 2025 techniques include:
- Frequency-domain watermarks that spread identifying information across the audio spectrum
- Neural watermarks trained alongside TTS models to be robust to compression and modification
- Adversarial watermarks designed to break if someone tries to remove them
Major platforms like ElevenLabs and Google now include mandatory watermarking for all generated content, though implementation details vary.
Passive Detection Methods
When watermarks aren't present or have been removed, passive detection analyzes audio characteristics:
- Artifact detection looks for subtle imperfections in synthetic speech that current models still produce
- Consistency analysis examines whether vocal characteristics remain stable in ways that differ from human speech
- Breathing pattern analysis compares synthetic and natural breathing rhythms and placements
- Emotional congruence analysis checks whether emotional expression matches linguistic content appropriately
Research consortiums like the Audio Deepfake Detection Challenge continue to advance these techniques, though they face an ongoing arms race with generation methods.
Provenance and Attribution Systems
Technical systems for tracking content origin provide another layer of protection:
The Coalition for Content Provenance and Authenticity (C2PA) standard has been extended to audio in 2025, allowing synthetic content to carry verifiable metadata about its creation process and modifications.
Blockchain-based attribution creates immutable records of content creation and modification, though scalability challenges remain for high-volume applications.
Platform-level verification allows trusted platforms to vouch for content authenticity through API-verifiable signatures.
Business Applications and Use Cases
Synthetic voice technology enables transformative business applications when implemented responsibly. Understanding appropriate use cases helps balance innovation with ethics.
Accessibility Applications
Perhaps the most unequivocally positive application of TTS technology is enhancing accessibility:
Screen readers and reading assistance: Modern neural TTS provides more natural, less fatiguing audio for visually impaired users or those with reading difficulties. The 2025 focus is on emotional expressiveness that conveys textual nuance beyond mere word pronunciation.
Real-time captioning and translation: Combining speech recognition with TTS enables near-real-time translation services that maintain speaker voice characteristics, making multilingual communication more personal.
Voice banking for degenerative conditions: Individuals with conditions like ALS can create voice clones early in their diagnosis, preserving their vocal identity for future communication needs.
Content Creation and Media
The media industry has embraced synthetic voices with careful ethical boundaries:
Audiobook production: TTS enables faster, more cost-effective audiobook creation, especially for backlist titles or niche content. Ethical implementations clearly disclose synthetic narration and often use distinct "narrator voices" rather than impersonating human narrators.
Localization and dubbing: Voice cloning allows actors to "speak" in multiple languages while maintaining their vocal characteristics, though best practices require actor consent and appropriate compensation.
Podcast production: Synthetic voices enable corrections and updates without re-recording entire episodes, saving production time while maintaining audio consistency.
Customer Experience and Support
Businesses are increasingly using synthetic voices to enhance customer interactions:
Interactive Voice Response (IVR) systems: Modern TTS creates more natural, less frustrating automated phone systems that better understand customer needs.
Personalized voice assistants: Companies can create brand-specific voice personas that remain consistent across all customer touchpoints.
Proactive notification systems: Synthetic voices enable personalized, timely notifications (appointment reminders, delivery updates) at scale.
Creative and Entertainment Applications
The entertainment industry pushes creative boundaries while navigating ethical considerations:
Video game character voices: Synthetic voices enable more dialogue options, dynamic responses, and character variety within production budgets.
Interactive storytelling: Voice cloning allows characters to respond to user input with appropriate emotional expression.
Posthumous performances (with appropriate estate permissions): Carefully managed use of voice cloning can extend artistic legacies while respecting the deceased's wishes and family concerns.
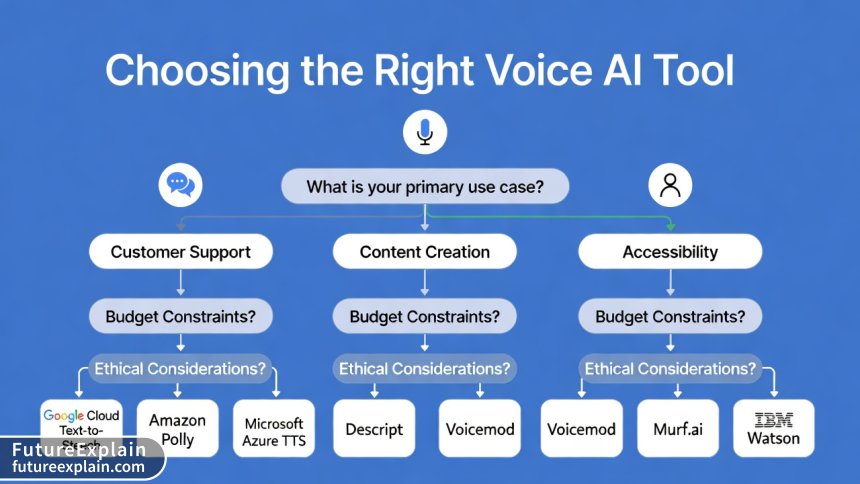
Implementation Guide: Choosing the Right Tool
Selecting appropriate TTS or voice cloning technology requires matching technical capabilities with ethical considerations and business needs. This decision framework helps navigate the options.
Assessment Phase: Defining Requirements
Begin by clarifying your specific needs across several dimensions:
- Use case specificity: Are you creating audiobooks, enhancing accessibility, building voice assistants, or something else?
- Quality requirements: Does your application need near-human quality or will functional clarity suffice?
- Language and voice diversity needs: How many languages and distinct voices are required?
- Real-time requirements: Does generation need to happen instantly or can it be pre-rendered?
- Ethical considerations: What consent, disclosure, and harm prevention measures are necessary?
- Budget constraints: What are your limits for initial development and ongoing usage?
Tool Selection Matrix
Based on your requirements, different tools will be appropriate:
For enterprise applications with extensive language needs: Google Cloud Text-to-Speech or Amazon Polly offer the broadest language support and enterprise-grade reliability.
For content creation with emotional expression: ElevenLabs or Murf AI provide the most control over tone, emphasis, and pacing.
For accessibility-focused applications: Microsoft Azure TTS includes specific optimizations for screen readers and learning applications.
For voice cloning with ethical safeguards: Descript Overdub or Respeecher emphasize consent verification and responsible use.
For research or custom model development: Open-source options like Coqui TTS provide flexibility and transparency.
Implementation Checklist
Once you've selected a tool, responsible implementation includes:
- Ethical review: Conduct internal or external review of proposed use cases for potential harm
- Consent protocols: Establish clear processes for obtaining and documenting consent when using human voices
- Disclosure planning: Determine appropriate disclosure methods for your audience and context
- Technical safeguards: Implement watermarks, detection methods, and access controls as appropriate
- User testing: Test with diverse user groups to identify unintended consequences or biases
- Monitoring and adjustment: Establish ongoing monitoring for misuse and mechanisms for course correction
Regulatory Landscape in 2025
The legal framework for synthetic voice technology is evolving rapidly. Understanding current regulations helps ensure compliance and anticipate future developments.
Global Regulatory Approaches
Different jurisdictions have taken varying approaches to synthetic media regulation:
European Union: The AI Act (fully implemented in 2025) classifies certain voice cloning applications as high-risk, requiring transparency, human oversight, and risk mitigation measures. The Act mandates clear labeling of synthetic content and imposes strict consent requirements.
United States: A patchwork of state laws addresses specific concerns like deepfakes in elections or non-consensual intimate imagery. The proposed federal AI Labeling Act would require disclosure of synthetic content but faces ongoing legislative challenges.
China: 2024 regulations require watermarks on all synthetic media and platform responsibility for preventing harmful content. The 2025 "Real Name Verification for Synthetic Media" rule adds creator identification requirements.
International efforts: The UNESCO recommendation on the ethics of AI includes provisions for synthetic media, emphasizing consent, cultural respect, and prevention of disinformation.
Industry Self-Regulation
In the absence of comprehensive legislation, industry initiatives have emerged:
The Partnership on AI's Synthetic Media Framework provides guidelines for responsible development and deployment, with 2025 updates focusing on voice-specific considerations.
The Content Authenticity Initiative brings together companies across the media ecosystem to develop technical standards for content provenance.
Platform-specific policies: Major platforms like YouTube, TikTok, and Spotify have implemented their own rules for synthetic content, typically requiring labels and prohibiting certain deceptive uses.
Future Trends and Considerations
Looking beyond 2025, several trends will shape the evolution of synthetic voice technology:
Technical Advancements on the Horizon
Emotional intelligence: Future systems will better detect and respond to user emotional states, creating more empathetic interactions.
Multimodal integration: Combining voice synthesis with facial animation and gesture generation will create more holistic synthetic personas.
Personalization at scale: Systems will increasingly adapt to individual listener preferences and contexts.
Reduced data requirements: Advancements in few-shot and zero-shot learning will enable voice cloning from even smaller samples.
Ethical and Social Developments
Digital identity frameworks: Systems for managing and controlling one's digital voiceprint may emerge as fundamental rights.
Consent management platforms: Specialized tools for managing voice consent across different applications and platforms.
Cultural voice preservation: Using voice cloning to preserve endangered languages and speaking styles with community oversight.
Forensic voice analysis: Advanced detection methods may become standard in legal and investigative contexts.
Conclusion: Balancing Innovation and Responsibility
Synthetic voice technology in 2025 offers remarkable capabilities that can enhance accessibility, creativity, and efficiency across countless applications. The tools available—from enterprise TTS services to sophisticated voice cloning platforms—provide unprecedented opportunities for positive impact.
However, these capabilities come with profound responsibilities. The ethical considerations surrounding consent, disclosure, and harm prevention are not mere add-ons but fundamental to responsible implementation. The most successful applications of synthetic voice technology will be those that balance technical capability with ethical rigor, creating value while respecting individual rights and societal norms.
As we move forward, ongoing dialogue between technologists, ethicists, policymakers, and the public will be essential. By approaching synthetic voice technology with both enthusiasm for its potential and caution regarding its risks, we can harness its benefits while minimizing harm. The choices we make today about how to develop and deploy these technologies will shape the audio landscape for years to come.
Visuals Produced by AI
Further Reading
Share
What's Your Reaction?
 Like
15240
Like
15240
 Dislike
125
Dislike
125
 Love
2105
Love
2105
 Funny
430
Funny
430
 Angry
85
Angry
85
 Sad
65
Sad
65
 Wow
1700
Wow
1700


















Excellent article overall, but I noticed you didn't cover regional language support in depth. In India alone, we have 22 official languages with diverse phonetic systems. Which tools handle this complexity best in 2025?
The comparison between enterprise TTS solutions helped our IT department make a decision. We were torn between Google and Amazon, but your analysis of their emotional controls tipped us toward Google for our customer service implementation.
I teach media ethics at a university, and I'll be assigning this article next semester. The framework you provide is exactly what students need to think critically about these technologies. Any plans to develop teaching resources around this content?
The future trends section got me thinking about cultural preservation. My community has an endangered language with only a few elderly speakers. Could voice cloning help preserve their unique vocal patterns for future generations?
Elliana, what an important application! Yes, voice cloning with proper community consent and oversight could be incredibly valuable for language preservation. The 2024 UNESCO guidelines specifically mention this as an ethical use case. The key is community control over the process and outputs. We're actually working on a case study with the Cherokee Nation's language preservation program—look for it in our Industry AI section soon!
I'm concerned about the psychological impact section. We're already seeing "voice trust" issues in relationships where people question if phone calls are real. This technology needs slow, careful introduction with public education.
The technical explanation of watermarking methods is the clearest I've seen. Do any of these methods survive common audio compression formats like MP3 or streaming codecs? We're building a content moderation system and need robust detection.