Multimodal Models: Combining Text, Image, Audio, and Video
This article provides a comprehensive, beginner-friendly guide to multimodal AI models, which can process and connect information from multiple sources like text, images, audio, and video simultaneously. Unlike earlier AI systems limited to single data types, these models create a more unified and human-like understanding of the world. We explain the core concepts of how multimodal AI works, including its architecture and the training breakthroughs that made it possible. The guide covers exciting real-world applications, from generating images from text descriptions and analyzing medical scans with patient notes to creating responsive educational tools and content. We also address the significant challenges, ethical considerations, and practical limitations of this technology, helping readers separate current reality from hype. Finally, we explore what the continued evolution of multimodal intelligence might mean for the future of human-computer interaction and various industries.

Multimodal Models: Combining Text, Image, Audio, and Video
For decades, the dream of artificial intelligence has been to create machines that can understand the world as we do—not through a single sense, but through a rich combination of sight, sound, and language. Think about how you learned to recognize a cat: you didn't just read the word "cat." You saw pictures, heard it meow, felt its fur, and connected those experiences with the spoken and written word. This holistic understanding is the essence of human intelligence, and it has long been a distant goal for AI. However, a powerful new class of systems is emerging that brings us closer to this reality: multimodal AI models.
Unlike traditional AI, which might specialize only in understanding text (like a chatbot) or identifying objects in images (like a photo organizer), multimodal models can process and, crucially, connect information from multiple different sources simultaneously[citation:7]. They can understand the relationship between a picture and its caption, generate an image from a detailed text description, or answer questions about a video by analyzing both its visual scenes and spoken dialogue. This ability to translate concepts between different "languages" of data—text, image, audio, video—represents a significant leap forward.
This leap was vividly demonstrated with the update from GPT-3.5 to GPT-4. The former, trained only on text, was a powerful writing and reasoning tool. The latter, trained on both text and images, gained a qualitatively new ability to understand and discuss visual content, showcasing how a multimodal approach can lead to a "huge leap in ability"[citation:7].
In this guide, we will demystify multimodal AI. We will explore how these models work under the hood, examine their transformative real-world applications, and honestly address their limitations and the ethical challenges they present. Our goal is to move beyond the hype and provide you with a clear, grounded understanding of this fascinating technology that is reshaping our interaction with machines.
What is Multimodal AI? Beyond Single-Mode Thinking
At its core, Artificial Intelligence (AI) is the field focused on building machines capable of tasks requiring human intelligence, such as perception, reasoning, and learning[citation:1]. For most of AI's history, progress happened within separate, specialized silos. Researchers developed excellent models for computer vision (understanding images), groundbreaking models for natural language processing (understanding text), and sophisticated models for speech recognition (understanding audio). These are all examples of unimodal AI—powerful within their narrow domain but unable to make connections outside of it.
An image recognition model could tell you a photo contains a "dog," but it couldn't read a related news article about dog breeds. A text model could write a poem about a sunset, but it couldn't appreciate an actual photograph of one. Their world was one-dimensional.
Multimodal AI shatters these silos. It refers to models and systems designed to process, interpret, and generate information from two or more different types of data, or modalities. The most common modalities are:
- Text: Written or spoken language.
- Vision: Images, drawings, and video frames.
- Audio: Speech, music, and environmental sounds.
Some advanced systems may also incorporate other data types, such as numerical sensor data or depth information. The magic isn't just in processing these types side-by-side; it's in learning the deep semantic relationships between them. The model learns that the pixel pattern of a "cat" is semantically linked to the word "cat," the sound "meow," and textual concepts like "furry," "pet," and "whiskers." It builds a unified understanding that transcends the original data format.
Visuals Produced by AI
How Do Multimodal Models Work? The Technical Bridge
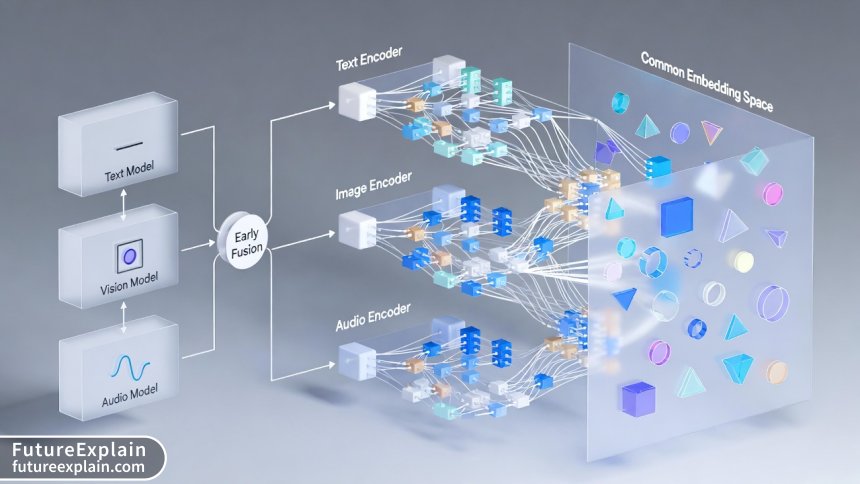
The fundamental challenge of multimodal AI is that computers ultimately understand numbers, not concepts. Text, images, and audio are all stored as vastly different numerical structures. How do you teach a model that a particular grid of pixel values (an image) and a specific sequence of word codes (a sentence) mean the same thing? The answer lies in a concept called a shared or common embedding space.
Step 1: Encoding Different Languages into a Common One
Imagine you have an English speaker, a French speaker, and a painter. To get them to communicate, you teach them all an intermediate, conceptual sign language. They each translate their native "modality" (English, French, visual art) into this common set of signs. In AI, this "sign language" is a high-dimensional vector—a list of numbers that represents the semantic meaning.
- The text encoder (a neural network) converts the sentence "a black cat sitting on a mat" into Vector A: [0.12, -0.45, 0.87, ...].
- The image encoder (a different neural network, often a Convolutional Neural Network) converts a photo of a black cat on a mat into Vector B: [0.15, -0.41, 0.85, ...].
Through massive-scale training on millions of matched image-text pairs (like those found online), the model adjusts its neural networks so that Vector A and Vector B become mathematically similar. Even though they started from completely different data types, their numerical representations end up close together in the shared embedding space because they share meaning[citation:3].
Step 2: Architectural Approaches: Fusion Strategies
How and when do you combine these different streams of information? Researchers use different fusion architectures:
- Early Fusion: Raw or lightly processed data from different modalities is combined right at the input stage. Think of stitching image pixels and text word codes into one long input vector. This can be simple but often struggles because the model has to learn to disentangle the modalities from the start.
- Late Fusion: Each modality is processed independently by its own specialized model (a "vision expert" and a "language expert"). Their final outputs or high-level decisions are combined at the very end. This leverages strong unimodal models but may miss fine-grained interactions.
- Intermediate/Hybrid Fusion (the modern approach): This is where the shared embedding space shines. Each modality is encoded into its own vector, and these vectors interact throughout the model's processing layers via mechanisms like cross-attention. This allows the model to, for example, pay attention to the relevant part of an image while processing each word of a question about it. This deep, ongoing interaction is key to sophisticated multimodal reasoning[citation:3].
Step 3: Training on a Planetary Scale
The success of models like GPT-4 and others hinges on self-supervised learning on internet-scale data[citation:3]. The training doesn't require humans to label every connection. Instead, the model is presented with naturally occurring pairs: an image with its alt-text, a video with its subtitle track, a news article with its featured photo. Its task is to predict missing parts (e.g., predict the caption from the image, or predict a masked word in the caption given the image). By solving billions of these puzzles, the model internalizes the complex web of associations that link our visual and linguistic worlds.
The Real-World Magic: Applications of Multimodal AI
The theoretical breakthrough of multimodal AI is already translating into practical tools that are changing industries and creative workflows. Here are some of the most impactful applications you might encounter today.
1. Generative Creativity: From Imagination to Asset
This is the most visible application for many people. Tools like DALL-E, Midjourney, and Stable Diffusion are multimodal models at their core.
- How it works: You provide a text prompt ("a photorealistic image of an astronaut riding a horse on Mars"). The model's text encoder interprets this prompt and navigates to the corresponding region of the shared embedding space. A separate image generation component (often a diffusion model) then "walks" from random noise to a coherent image that matches the location in that conceptual space, effectively translating the text vector into a novel image vector and then into pixels[citation:7].
- Beyond Images: The same principle applies to generating video from text, music from a mood description, or 3D models from a blueprint sketch.
2. Enhanced Search and Discovery
Traditional search is based on keywords. Multimodal search understands content.
- Visual Search: You can upload a photo of a plant and ask "What species is this?" The model combines its visual analysis with its knowledge base to answer.
- Cross-Modal Retrieval: Search for "feel-good movies with beach scenes" and the AI can analyze video clips, audio tone (upbeat music), and subtitles to find matches, rather than just relying on textual tags[citation:7].
3. Accessibility and Inclusive Design
Multimodal AI is a powerful tool for breaking down barriers.
- Automatic Alt-Text Generation: AI can analyze complex images, infographics, or memes and generate accurate, detailed descriptions for screen readers, making the web more accessible to visually impaired users.
- Real-Time Transcription & Translation: Combining audio processing (speech-to-text) with language translation and perhaps even sign-language recognition from video can create seamless communication tools for deaf and hard-of-hearing individuals or across language divides.
4. Healthcare: A Second Pair of Eyes and Ears
In medicine, combining multiple data sources can lead to more accurate assessments. A multimodal system could:
- Analyze a medical scan (X-ray, MRI) while also reading the patient's electronic health record and doctor's notes to highlight potential concerns a human might miss.
- Listen to a patient describe symptoms while analyzing visual cues from a video consult, aiding in remote diagnostics[citation:1].
5. Education and Training
Imagine an intelligent tutoring system that doesn't just read your text answers but can see the diagram you've drawn on a digital whiteboard. It can understand your mistake is in mislabeling a part of the cell, not the concept of cells themselves. It can then generate a custom 3D animation or find a relevant video clip to address your specific misunderstanding, creating a truly adaptive learning experience.

Visuals Produced by AI
The Flip Side: Challenges, Limitations, and Ethical Terrain
For all their promise, multimodal models come with significant hurdles and risks that must be acknowledged and managed. It's crucial to remember that these systems, while advanced, do not possess human understanding, consciousness, or emotions[citation:2]. They are sophisticated pattern-matching engines.
Key Technical and Practical Challenges
- The "Black Box" Problem: Like many deep learning models, it's often difficult to understand exactly why a multimodal model made a particular connection or decision. This lack of transparency is a major issue in high-stakes fields like medicine or criminal justice[citation:1].
- Data Bias Amplification: These models learn from our world's data, which contains human biases. A model trained on stereotypical image-text pairs might learn that "CEO" is associated only with images of men in suits, or that "nurse" is predominantly female. It will then perpetuate and can even amplify these biases in its outputs[citation:1][citation:8].
- Computational Cost: Training and running these massive models requires enormous amounts of energy and specialized hardware, raising concerns about environmental sustainability and equitable access[citation:8].
- Hallucination and Confabulation: Just like text-only models can invent plausible-sounding but false facts, multimodal models can generate convincing images of events that never happened or provide authoritative-sounding but incorrect descriptions of videos[citation:5]. This makes verification more critical than ever.
How to Critically Evaluate Multimodal AI Output
Given the risk of "hallucinations," it's essential for users to develop a verification habit. Treat the AI as a highly creative, sometimes mistaken assistant. For factual claims (especially in generated text accompanying an image or video), cross-check with authoritative sources. Be skeptical of "perfect" or emotionally charged synthetic media. Understand that the AI is recombining patterns it has seen; it is not a source of ground truth. This critical mindset is your best defense against misinformation.
Ethical and Societal Considerations
- Deepfakes and Misinformation: The ability to generate realistic synthetic media (video of a politician saying something they never did, audio of a loved one's voice) poses profound threats to trust, journalism, and personal security. Developing detection tools and legal frameworks is an urgent challenge[citation:1].
- Copyright and Ownership: Who owns an image generated by an AI that was trained on millions of copyrighted artworks and photographs? This is a legal gray area with major implications for artists and content creators[citation:7].
- Job Displacement and Change: While AI is more likely to augment jobs than replace them entirely in the near term[citation:2], roles in content creation, graphic design, stock photography, and basic analysis will undoubtedly evolve. The focus will shift toward creative direction, curation, editing, and managing AI systems.
For Business Leaders and Managers
Understanding these limitations is not just an academic exercise; it's a business imperative. Believing the myth that "AI is a silver bullet" can lead to costly implementation failures[citation:2]. Successful integration requires identifying specific, well-defined problems where multimodal AI's strength—connecting different data types—adds clear value. It demands investment in data quality, not just quantity, and a plan for human oversight to catch errors and mitigate bias. The goal is strategic augmentation, not magical replacement.
The Future: Towards a More Seamless Interaction
The trajectory of multimodal AI points toward more natural and intuitive interfaces. We are moving away from the era of typing precise commands and toward an era of ambient, context-aware computing.
- Truly Intelligent Assistants: Future assistants could see what you see through smart glasses, hear your conversations (with permission), and access your documents to provide truly contextual help—like reminding you of a person's name when you see them, or suggesting a recipe based on the ingredients in your fridge and your dietary preferences.
- Robotics and Embodied AI: For robots to operate effectively in our messy, unstructured world, they need multimodal understanding. They must combine computer vision to navigate, natural language to understand instructions, and audio to hear warnings or requests.
- The Long-Term Goal: Artificial General Intelligence (AGI)? The ability to integrate and reason across different types of information is considered a cornerstone of general intelligence[citation:7][citation:10]. While today's multimodal AI is still a form of Narrow AI (excelling at specific, trained tasks), it represents a foundational step toward the broader, more adaptable intelligence envisioned as AGI. However, AGI remains a theoretical goal with immense technical and philosophical hurdles[citation:1][citation:10].
The path forward requires balanced progress. We must pursue the remarkable capabilities of this technology while building robust guardrails—ethical guidelines, transparency tools, and regulatory frameworks—to ensure it develops in a way that is trustworthy, fair, and ultimately benefits all of humanity[citation:8].
Conclusion
Multimodal AI models represent a paradigm shift from single-sense, specialized intelligence to a more integrated, human-like form of understanding. By learning the deep connections between text, images, audio, and video, they enable revolutionary applications in creativity, accessibility, healthcare, and beyond. However, this power comes with significant responsibility. These systems are not infallible or truly intelligent; they are complex tools that reflect both the brilliance and the biases of their training data.
As this technology continues to evolve and permeate our lives, our role is to be informed users and thoughtful shapers. By understanding how multimodal AI works, recognizing its current limitations, and critically engaging with its outputs, we can harness its potential while navigating its risks. The future it points to is one of richer, more natural interaction between humans and machines—but it is a future we must build with our eyes wide open.
Further Reading
To continue your exploration of AI and its evolving capabilities, consider these related articles from FutureExplain:
- Multimodal AI: Combining Text, Image, Audio, and Video (Our 2024 deep dive on the core concepts).
- AI Myths vs Reality: What AI Can and Cannot Do (A foundational guide to separating hype from reality).
- Deep Learning & Neural Networks (Understand the engine powering modern AI, including multimodal models).
Share
What's Your Reaction?
 Like
15230
Like
15230
 Dislike
85
Dislike
85
 Love
2100
Love
2100
 Funny
345
Funny
345
 Angry
120
Angry
120
 Sad
65
Sad
65
 Wow
2505
Wow
2505















This article connected so many dots for me. I'd read about neural networks, and I'd read about ChatGPT, and I'd seen AI art, but I never understood they were all converging into this multimodal thing. The diagram was super helpful. FutureExplain consistently has the best "bridge" content between beginner and intermediate.
I work in film production, and the video generation tools are getting scary good. We used one to quickly create a rough storyboard from a script. It saved us a week of work. But the copyright question looms large. If the model was trained on copyrighted movies, who owns our storyboard? The legal uncertainty is holding back a lot of professional adoption.
The part about "hallucination" in multimodal contexts is terrifying. A fake but convincing video with a fake but convincing news article to back it up? That's a disinformation super-weapon. The verification tips are crucial, but will the average person bother? This feels like a societal problem we're not ready for.
The technical explanation was good, but I'm still confused about one thing: in "intermediate fusion," when the vectors interact via "cross-attention," is that a continuous back-and-forth during the entire process, or just at one stage? The article says "throughout," but a more detailed metaphor might help.
Excellent question, Tomas, which gets into the architecture specifics. A common method is to have the encoded text sequence (a set of vectors, one per word) and the encoded image (a set of vectors, often for different image patches) attend to each other across multiple layers. So, in layer 1, the word "black" might find and focus on the dark patches in the image. In a deeper layer, the phrase "sitting on" might attend to the spatial relationship between the cat vector and the mat vector. It's an iterative, refined dialogue across the network's depth.
As a small business owner, the "business implications" box was the most valuable part for me. It's easy to get swept up in the hype and think you need this fancy AI. Your point about finding a specific problem it solves is gold. I'm now thinking about using it to automatically generate alt-text for my product images to improve website accessibility.
That's a fantastic and immediately practical use case, Amelia! Improving accessibility is not just the right thing to do, it also opens up your market. There are already some affordable SaaS tools that offer this exact feature using multimodal AI. Start small and see how it works for your workflow.
This feels like the beginning of the "J.A.R.V.I.S." style AI from the movies. Combining sight, sound, and knowledge. The part about future assistants using smart glasses really drove that home. The privacy implications of that, though, are enormous.
Absolutely, Alex. It's the classic trade-off: convenience vs. privacy. An AI that sees and hears everything to be truly helpful is also a surveillance engine. The article touched on ethics, but this specific privacy angle for ambient AI deserves its own deep dive. We need strong opt-in, data minimization, and on-device processing standards.